La indexaci贸n es una forma de optimizar el rendimiento de una base de datos al minimizar la cantidad de accesos al disco necesarios cuando se procesa una consulta. Es una t茅cnica de estructura de datos que se utiliza para localizar y acceder r谩pidamente a los datos en una base de datos.聽
Los 铆ndices se crean utilizando unas pocas columnas de la base de datos.聽
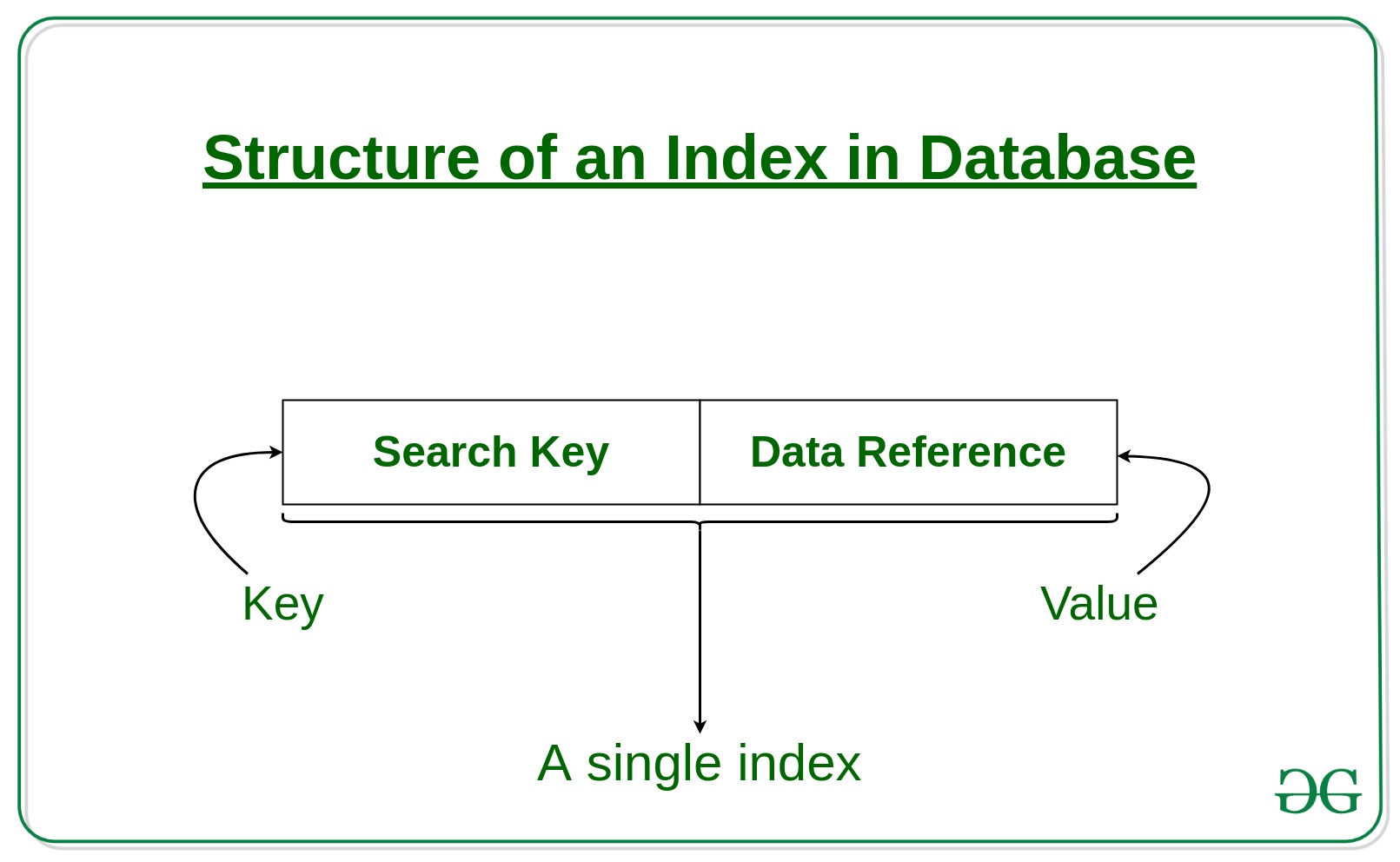
- La primera columna es la clave de b煤squeda que contiene una copia de la clave principal o clave candidata de la tabla. Estos valores se almacenan ordenados para que se pueda acceder r谩pidamente a los datos correspondientes.聽
Nota: Los datos pueden almacenarse o no en orden ordenado. - La segunda columna es la referencia de datos o puntero que contiene un conjunto de punteros que contienen la direcci贸n del bloque de disco donde se puede encontrar ese valor de clave en particular.
La indexaci贸n tiene varios atributos:聽聽
- Tipos de acceso : se refiere al tipo de acceso, como b煤squeda basada en valores, acceso por rango, etc.
- Tiempo de acceso : se refiere al tiempo necesario para encontrar un elemento de datos en particular o un conjunto de elementos.
- Tiempo de inserci贸n : se refiere al tiempo necesario para encontrar el espacio adecuado e insertar un nuevo dato.
- Tiempo de eliminaci贸n : tiempo necesario para encontrar un elemento y eliminarlo, as铆 como para actualizar la estructura del 铆ndice.
- Space Overhead : Se refiere al espacio adicional requerido por el 铆ndice.
En general, existen dos tipos de mecanismos de organizaci贸n de archivos que son seguidos por los m茅todos de indexaci贸n para almacenar los datos:聽聽
1. Organizaci贸n de archivos secuenciales o archivo de 铆ndice ordenado: en este, los 铆ndices se basan en una ordenaci贸n ordenada de los valores. Estos son generalmente r谩pidos y un tipo de mecanismo de almacenamiento m谩s tradicional. Estas organizaciones de archivos ordenados o secuenciales pueden almacenar los datos en un formato denso o disperso:聽
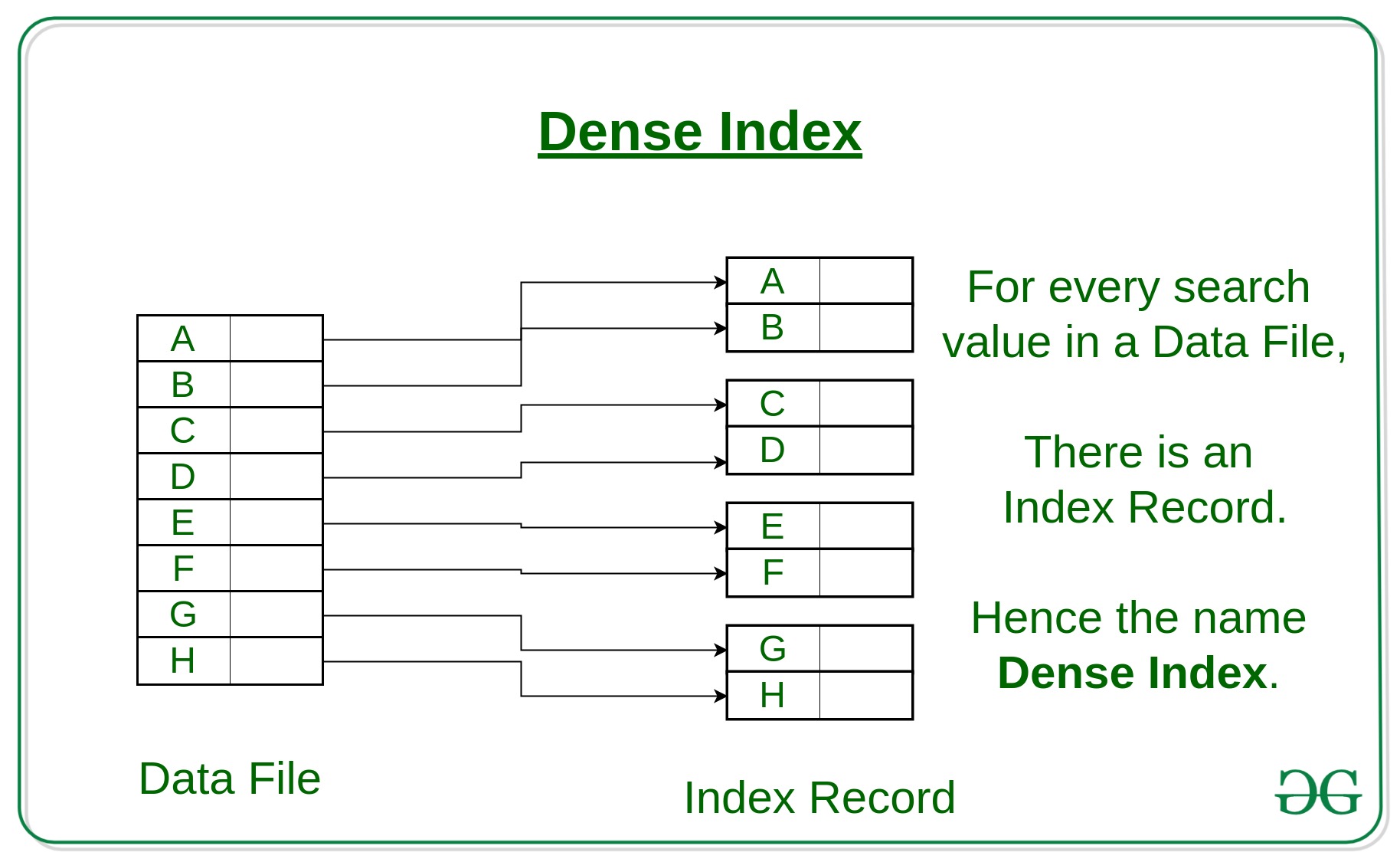
(i) 脥ndice denso:聽
- Para cada valor de clave de b煤squeda en el archivo de datos, hay un registro de 铆ndice.
- Este registro contiene la clave de b煤squeda y tambi茅n una referencia al primer registro de datos con ese valor de clave de b煤squeda.
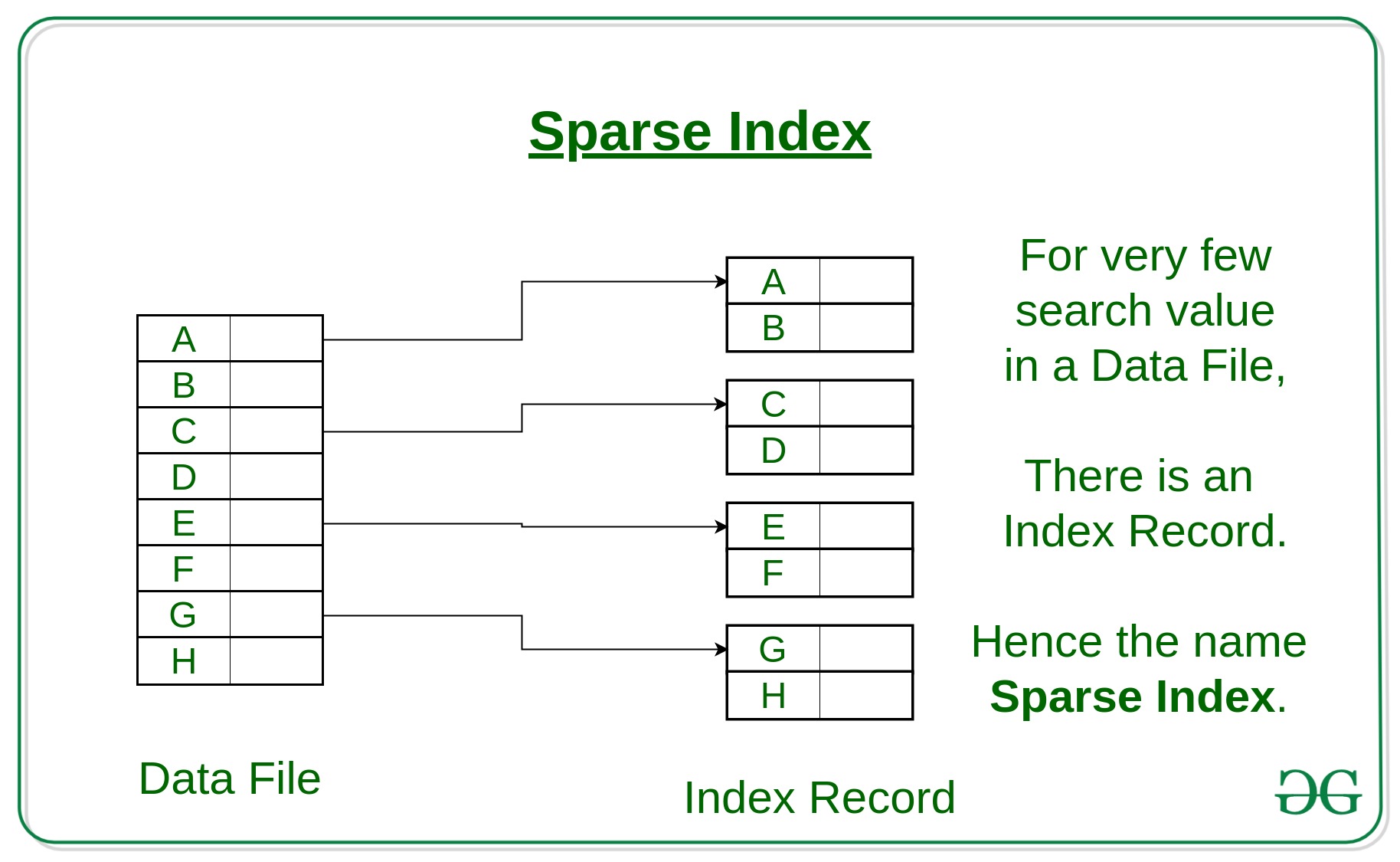
(ii) 脥ndice disperso:聽
- El registro de 铆ndice aparece solo para algunos elementos en el archivo de datos. Cada elemento apunta a un bloque como se muestra.
- Para localizar un registro, buscamos el registro de 铆ndice con el mayor valor de clave de b煤squeda menor o igual que el valor de clave de b煤squeda que estamos buscando.
- Comenzamos en ese registro al que apunta el registro 铆ndice y avanzamos junto con los punteros en el archivo (es decir, secuencialmente) hasta que encontramos el registro deseado.
2. Organizaci贸n de archivos hash: los 铆ndices se basan en que los valores se distribuyen uniformemente en un rango de cubos. Los cubos a los que se asigna un valor est谩n determinados por una funci贸n llamada funci贸n hash.
Existen principalmente tres m茅todos de indexaci贸n:聽聽
- Indexaci贸n agrupada
- Indexaci贸n secundaria o no agrupada
- Indexaci贸n multinivel
1. Indexaci贸n聽
en cl煤ster Cuando se almacenan m谩s de dos registros en el mismo archivo, este tipo de almacenamiento se conoce como indexaci贸n en cl煤ster. Al usar la indexaci贸n de cl煤steres, podemos reducir el costo de la b煤squeda, ya que se almacenan m煤ltiples registros relacionados con lo mismo en un solo lugar y tambi茅n brinda la uni贸n frecuente de m谩s de dos tablas (registros).聽
El 铆ndice de agrupamiento se define en un archivo de datos ordenados. El archivo de datos se ordena en un campo no clave. En algunos casos, el 铆ndice se crea en columnas de clave no primaria que pueden no ser 煤nicas para cada registro. En tales casos, para identificar los registros m谩s r谩pido, agruparemos dos o m谩s columnas para obtener los valores 煤nicos y crear un 铆ndice a partir de ellos. Este m茅todo se conoce como el 铆ndice de agrupamiento. B谩sicamente, los registros con caracter铆sticas similares se agrupan y se crean 铆ndices para estos grupos.聽
Por ejemplo, los estudiantes que estudian en cada semestre se agrupan. es decir , se agrupan los estudiantes del 1er semestre, los estudiantes del 2do semestre, los estudiantes del 3er semestre , etc.聽
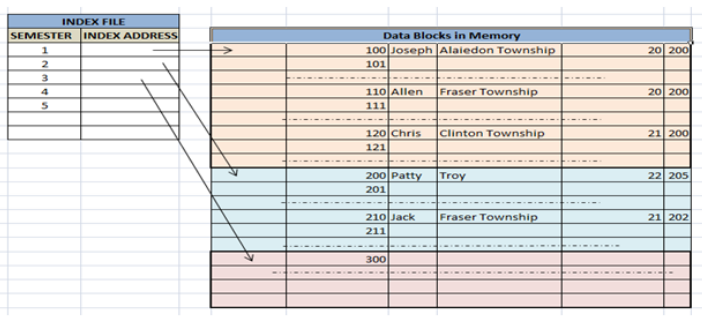
脥ndice agrupado ordenado seg煤n el nombre (tecla de b煤squeda)聽
Indexaci贸n primaria:聽
este es un tipo de indexaci贸n agrupada en la que los datos se ordenan seg煤n la clave de b煤squeda y la clave principal de la tabla de la base de datos se usa para crear el 铆ndice. Es un formato predeterminado de indexaci贸n donde induce la organizaci贸n secuencial de archivos. Como las claves primarias son 煤nicas y se almacenan ordenadas, el rendimiento de la operaci贸n de b煤squeda es bastante eficiente.聽
2. Indexaci贸n secundaria o聽
no agrupada Un 铆ndice no agrupado simplemente nos dice d贸nde se encuentran los datos, es decir, nos brinda una lista de punteros virtuales o referencias a la ubicaci贸n donde se almacenan realmente los datos. Los datos no se almacenan f铆sicamente en el orden del 铆ndice. En cambio, los datos est谩n presentes en los Nodes hoja. Por ej. la p谩gina de contenido de un libro. Cada entrada nos da el n煤mero de p谩gina o la ubicaci贸n de la informaci贸n almacenada. Los datos reales aqu铆 (informaci贸n en cada p谩gina del libro) no est谩n organizados, pero tenemos una referencia ordenada (p谩gina de contenido) de d贸nde se encuentran realmente los puntos de datos. Solo podemos tener un ordenamiento denso en el 铆ndice no agrupado, ya que el ordenamiento disperso no es posible porque los datos no est谩n organizados f铆sicamente en consecuencia.聽
Requiere m谩s tiempo en comparaci贸n con el 铆ndice agrupado porque se realiza una cierta cantidad de trabajo adicional para extraer los datos siguiendo m谩s el puntero. En el caso de un 铆ndice agrupado, los datos est谩n directamente presentes delante del 铆ndice.聽

3. Indexaci贸n multinivel聽
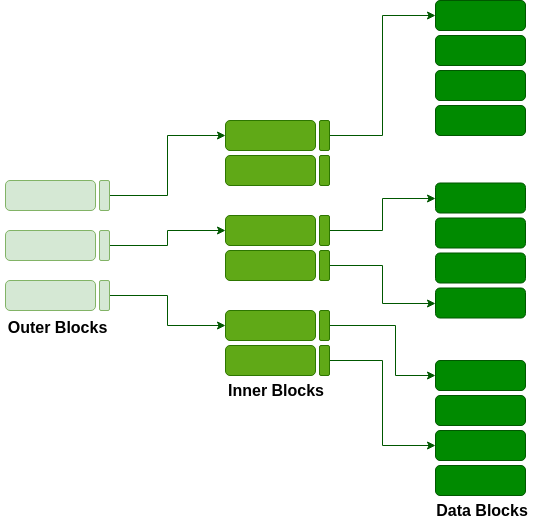
Con el crecimiento del tama帽o de la base de datos, los 铆ndices tambi茅n crecen. Como el 铆ndice se almacena en la memoria principal, un 铆ndice de un solo nivel puede tener un tama帽o demasiado grande para almacenarse con m煤ltiples accesos al disco. La indexaci贸n multinivel segrega el bloque principal en varios bloques m谩s peque帽os para que el mismo pueda almacenarse en un solo bloque. Los bloques exteriores se dividen en bloques interiores que, a su vez, apuntan a los bloques de datos. Esto se puede almacenar f谩cilmente en la memoria principal con menos gastos generales.聽
Este art铆culo es una contribuci贸n de Avneet Kaur . Escriba comentarios si encuentra algo incorrecto o si desea compartir m谩s informaci贸n sobre el tema tratado anteriormente.
聽
Publicaci贸n traducida autom谩ticamente
Art铆culo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA