自动写诗APP项目、基于python+Android实现(技术:LSTM+Fasttext分类+word2vec+Flask+mysql)第三节

 最新推荐文章于 2024-03-23 20:07:37 发布
最新推荐文章于 2024-03-23 20:07:37 发布
 阅读量1.1k
阅读量1.1k
 收藏
6
收藏
6


 点赞数
3
点赞数
3



二、用户主题词分类,相似词生成
1.word2vec模型原理
在主题词分类、候选词生成、选取时,都使用了word2vec模型。word2vec模型主要包含两部分:跳字模型(skip-gram)和连续词袋模型(CBOW),和两种高效训练的方法:负采样(negative sampling)和层序softmax(hierarchical softmax)。
word2vec词向量可以较好地表达不同词之间的相似度和类比关系。其主要是通过训练神经网络语言模型,即CBOW和Skip-gram模型而得到的。这个模型的输出并不需要,而模型中第一个隐含层中的参数权重,即参数矩阵才是我们需要的word2vec词向量。它的每一行就是词典中对应词的词向量,行数就是词典的大小。
CBOW模型和skip-gram的结构如下图所示:


CBOW结构图 skip-gram结构图
CBOW是一个三层神经网络。模型的特点是输入已知上下文,输出对当前单词的预测。CBOW中,w(t)代表当前词语位于诗句中的位置t,同理定义其他记号。在窗口内,除了当前词语之外的其他词语共同构成上下文。
其学习目标是最大化对数似然函数:

输入层:Context(w)是上下文词语的词向量,也是CBOW模型的一个参数。训练开始的时候,词向量是个随机值,随着训练的进行而不断被更新。训练CBOW模型时,词向量只是个副产品,最终训练得到的模型此处我们并不需要。
投影层:对向量做加法。
输出层:一个概率分布w(t),表示词典中每个词出现的概率。
训练完成后第一个全连接层的参数就是word embedding。Skip-gram只是逆转了CBOW的因果关系而已,就是已知当前词语,预测上下文。
负采样(negative sampling)和层序softmax,是用来提高训练速度并且改善所得到的词向量质量的一种方法。不同于每个训练样本更新所有的权重,负采样每次让一个训练样本仅更新小部分的权重,这样便可以降低梯度下降过程中的计算量。
2、word2vec模型应用
训练模型使用的是word2vec工具库中的Word2Vec()函数。在此项目中模型设置了以下几个参数:
Sentences:分析的预料
size=150:词向量的维度
window=5:词向量上下文最大距离
sg=1:0为CBOW模型,1为Skip-Gram模型
hs=1:0为负采样,1为Hierarchical softmax
min_count=8:计算词向量的最小词频,可以去掉一些生僻词
iter=20:随机梯度下降法中迭代的最大次数
alpha=0.0025:迭代的初始步长
min_alpha=0.005:最小迭代步长,随机梯度下降法,迭代中步长逐步减小
使用维基百科的word2vec模型时,在word2vec工具库中调用了similarity(word1,word2)函数,来计算2个词的相似度。返回值在[-1,1]之间。因为计算的是2个词向量的余弦值,即通过计算两个向量的夹角 余弦值来评估他们的 相似度。
例如:
边塞、大漠:0.6080173
边塞、田园:0.27724376
从中可见,边塞、大漠2词,和边塞、山水2词相比,前者的相似度还是较大的。虽然概率的对比效果不是很明显,但也是能够判别用户输入的主题词所属类别的。此处训练的语料是维基百科,语料库是很大的,且文本内容包含了各个方面,大多是对词的定义解释,并不针对于某一领域,并且训练时设置的各个参数,都会对词的相似性计算产生影响。因此,计算出来的相似度准确性上往往有些差异,但大体上是差不多的,足以判别主题词所属类别。
用维基百科预料训练的word2vec模型计算“边塞”主题词与5类诗的15个关键词的相似度值:
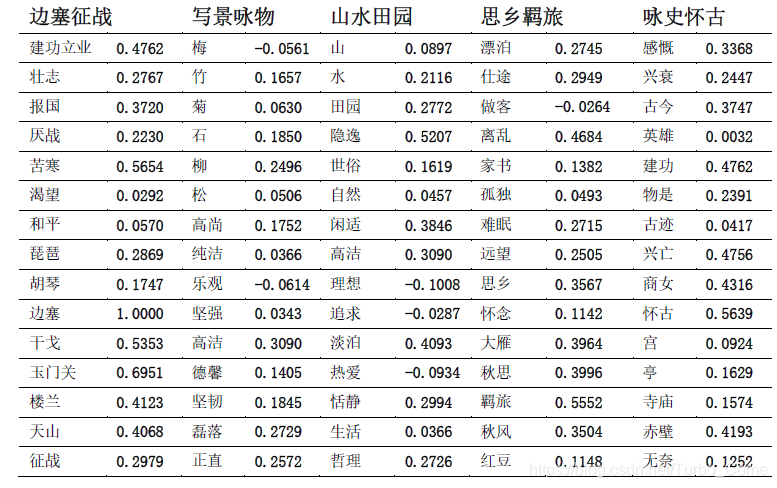
从“边塞”与5类诗的15个关键词的相似度值,可以确定该主题词最可能所属于“边塞征战”类诗。
计算词的相似词函数为:
most_similar(key_word,topn=N),
key_word为指定的关键词
topn指定与关键词最相似的几个词
3、用户主题词分类,相似词生成的具体代码实现:
# coding=gbk
"""
word2vec 模型
1.根据用户输入关键词判断其所属类别,用wiki_model(以维基百科为语料得到预测模型)
本来想着用全部诗歌数据集作为语料,但实践发现,若用户输入的关键词不在诗歌中(ep:壮志难酬)
则模型无法实施预测,根本原因语料数据太小,无法加载大量词汇
2.根据判断后的所属类别,分别生成5类诗的 ***.model ,以所属类别的 .model来预测与用户关键词
最相近的 6 个词,去重后用作诗中每句的备选开头字
"""
from config import *
class Word2vec_similar():
# 处理数据(若分类已处理过,则不用再次处理)
def file_deal(self,path_before,path_after):
# 处理停用词
stop_word = []
with open("Data/Stopwords.txt",'r',encoding='utf-8') as f_reader:
for line in f_reader:
line = str(line.replace('\n','').replace('\r','').split())
stop_word.append(line)
stop_word = set(stop_word)
rules = u'[\u4e00-\u9fa5]+'
pattern = re.compile(rules)
f_write = open(path_after, 'a',encoding='utf-8')
with open(path_before, 'r', encoding='utf-8') as f_reader2:
for line in f_reader2:
title,author,poem = line.strip().split("::")
poem = poem.replace('\n','').replace('\r','').split()
poem = str(poem)
poem = ' '.join(jieba.cut(poem))
seg_list = pattern.findall(poem)
word_list = []
for word in seg_list:
if word not in stop_word:
word_list.append(word)
line = " ".join(word_list)
f_write.write(line + '\n')
f_write.flush()
f_write.close()
""""
Word2vec 训练模型参数
sentences 分析的预料,可以是一个列表,或从文件中遍历读出
size :词向量的维度, 默认值 100 , 语料> 100M, size值应增大
window: 词向量上下文最大距离,默认 5,小语料值取小
sg: 0--> CBOW模型 1--> Skip-Gram模型
hs: 0 负采样 , 1 Hierarchical Softmax
negative : 使用负采样 的个数, 默认 5
cbow_mean: CBOW中做投影,默认 1,按词向量平均值来描述
min_count: 计算词向量的最小词频 ,可以去掉一些生僻词(低频),默认 5
iter:随机梯度下降法中迭代的最大次数,默认 5,大语料可增大
alpha: 迭代的初始步长,默认 0.025
min_alpha:最小迭代步长,随机梯度下降法,迭代中步长逐步减小
"""
def practice_model (self ,path_6shi_deal, path_save_key):
# path 全唐诗路径(处理后的) ,path_save_key 生成模型后保存的路径
path = path_6shi_deal
sentences = word2vec.Text8Corpus (path) # 加载文件
# 调参 iter 训练轮次 size 大小
# 全部诗个模型性 iter = 20 ,size = 300
# 其余5类是模型 iter = 20 , size = 200
model = word2vec.Word2Vec(sentences, iter=20, min_alpha=0.005, min_count=8,size=150)
# 保存模型 path_save模型路径
path_save = path_save_key
model.save (path_save)
# 返回 6 个相似词
def similar_6words(self,key_word, label):
if label == '边塞征战':
path_save = "Data\Class_model\Keyword_biansai.model"
elif label == '写景咏物':
path_save = "Data\Class_model\Keyword_jingwu.model"
elif label == '山水田园':
path_save = "Data\Class_model\Keyword_shanshui.model"
elif label == '思乡羁旅':
path_save = 'Data\Class_model\Keyword_sixiang.model'
else:
path_save = "Data\Class_model\Keyword_yongshi.model"
# 维基百科 2 词 相似度计算
model = word2vec.Word2Vec.load(path_save)
re_word = []
# 异常处理,当语料中无此关键词时,先取词前2个字,若还没有,取第一个字
try:
similary_words = model.most_similar(positive=[key_word], topn=6)
except:
key_word = key_word[0:2]
try:
similary_words = model.most_similar(positive=[key_word], topn = 6)
except:
key_word = key_word[0]
similary_words = model.most_similar(positive=[key_word], topn=6)
print(similary_words)
for e in similary_words:
print(e[0],e[1])
re_word.append(e[0])
return re_word
# 计算 2 词之间的相似度
def class_tags(self,str1):
# 以全唐诗为语料,计算2词相似度(不用,语料少)
# path_save = 'E:\Desk\MyProjects\Python/NLP_Demo1\File_jar\data_dir\Quanshi_Judge_6class.model'
# 5类诗的主题词,用于与用户输入的关键词进行相似度计算,判断类别--》5*15 二维矩阵
Themeword = [['' for i in range (5)] for i in range (15)]
Themeword[0] = ['建功立业', '壮志', '报国', '厌战', '苦寒', '渴望', '和平', '琵琶', '胡琴', '边塞', '干戈', '玉门关', '楼兰', '天山', '征战']
Themeword[1] = ['梅', '竹', '菊', '石', '柳', '松', '高尚', '纯洁', '乐观', '坚强', '高洁', '德馨', '坚韧', '磊落', '正直']
Themeword[2] = ['山', '水', '田园', '隐逸', '世俗', '自然', '闲适', '高洁', '理想', '追求', '淡泊', '热爱', '恬静', '生活', '哲理']
Themeword[3] = ['漂泊', '仕途', '作客', '离乱', '家书', '孤独', '难眠', '远望', '思乡', '怀念', '大雁', '秋思', '羁旅', '秋风', '红豆']
Themeword[4] = ['感慨', '兴衰', '古今', '英雄', '建功立业', '物是人非', '古迹', '兴亡', '商女', '怀古', '宫', '亭', '寺庙', '赤壁', '无奈']
# 维基百科计算2个词的相似度
wiki_path_model = "Data\Class_model\wiki_model\wiki_corpus.model" # 加载训练好的模型wiki_corpus.model
model2 = word2vec.Word2Vec.load (wiki_path_model)
sum_similar = [0 for i in range(5)]
for i in range(5):
for j in range(15):
# 异常处理,解决 wiki_model中没用此关键词的情况
# 异常处理,当语料中无此关键词时,先取词前2个字,若还没有,取第一个字
flag = False
try:
sim_value = model2.similarity(str1, Themeword[i][j])
flag = True
except:
print("Error")
str1 = str1[0:2]
try:
sim_value = model2.similarity(str1, Themeword[i][j])
flag = True
except:
str1 = str1[0]
if flag == False:
sim_value = model2.similarity(str1, Themeword[i][j])
sum_similar[i] += sim_value
max_value = max(sum_similar) # 选出最相似的那类
similar_index = sum_similar.index(max_value) # 确定是哪类的标签
label_tags = ["边塞征战", "写景咏物", "山水田园", "思乡羁旅", "咏史怀古"]
return label_tags[similar_index]
# 选择《诗学含英》中的6个与主题词最相似的标题词
def label_offen_words(self,character):
before_key = 6
title =[]
word_list = []
shi_xue_han_ying_path = 'Data/Shi_xue_han_ying.txt'
with open(shi_xue_han_ying_path,'r',encoding='urf-8') as f_reader:
for line in f_reader:
t,w = line.split("::")
title.append(t)
word_list.append(w)
# 维基百科的模型
path_save = 'Data/Class_model/'
# 加载训练好的模型 wiki_corpus.model
model = word2vec.Word2Vec.load(path_save)
similary_6value = [0 for i in range(len(title))]
for i in range(len(title)):
try:
similary_6value[i] = model.similarity(character)
except Exception as e:
character =character[0:2]
try:
similary_6value[i] = model.similarity(character)
except :
character = character[0]
similary_6value = np.array(similary_6value)
# 返回一个排序后的数组的索引, 倒序-截取数组下标值
max_6value_id = similary_6value.argsor()[::-1][0:before_key]
word_6list = ""
for i in range(before_key):
word_6list += "".join(word_list[max_6value_id[i]])
word_6list = word_6list.replace("\n", "")
word_6list = set(word_6list)
return word_6list
# 训练生成 5 类诗歌的word2vec模型
def train_6poems_word2vec_model(self):
ws = Word2vec_similar ()
# path1..,path1_save_model ,生成各类诗的word2vec的模型
path1 = 'Data\Generate_poems_jar/biansai.txt'
path11 = "Data\Class_model\Class_before_dealed_data/biansai.txt"
ws.file_deal(path1,path11)
path1_save_model = 'Data\Class_model/Keyword_biansai.model'
path2 = 'Data\Generate_poems_jar/jingwu.txt'
path22= "Data\Class_model\Class_before_dealed_data/jingwu.txt"
ws.file_deal (path2, path22)
path2_save_model = 'Data\Class_model/Keyword_jingwu.model'
path3 = 'Data\Generate_poems_jar/shanshui.txt'
path33 = "Data\Class_model\Class_before_dealed_data/shanshui.txt"
ws.file_deal (path3,path33)
path3_save_model = 'Data\Class_model/Keyword_shanshui.model'
path4 = 'Data\Generate_poems_jar/sixiang.txt'
path44 = "Data\Class_model\Class_before_dealed_data/sixiang.txt"
ws.file_deal (path4, path44)
path4_save_model = 'Data\Class_model/Keyword_sixiang.model'
path5 = 'Data\Generate_poems_jar/yongshi.txt'
path55 = "Data\Class_model\Class_before_dealed_data/yongshi.txt"
ws.file_deal (path5, path55)
path5_save_model = 'Data\Class_model/Keyword_yongshi.model'
# 训练每类的模型
ws.practice_model(path1, path1_save_model)
ws.practice_model(path2, path2_save_model)
ws.practice_model(path3, path3_save_model)
ws.practice_model(path4, path4_save_model)
ws.practice_model(path5, path5_save_model)
#按词(字)频 进行云图展示
def Picture_file(self,text_words,label): #text_words文字总数,label云图标题
# 定义保存图片的绝对路径,云图背景
file_path = r'Data\Class_model\Cloud_picture\\'
# 把路径地址字符串转换为文件路径
d = path.dirname(file_path)
backgroug_Image = np.array(Image.open(path.join(d,'cloud.png')))
wc = WordCloud(
background_color='white', # 背景颜色
mask=backgroug_Image, # 设置背景为指定图片
# font_path="C:\Windows\Fonts\汉仪雪君体简.ttf", # 设置字体
font_path="C:\Windows\Fonts\simkai.ttf",
max_words=2000, # 最大字频数
max_font_size=150, # #最大号字体,如果不指定则为图像高度
random_state=1,
scale=3 # 像素
)
wc.generate(text_words)
# 根据图片颜色重新上色
image_color = ImageColorGenerator(backgroug_Image)
plt.imshow(wc.recolor(color_func=image_color))
wc.to_file('Data\Class_model\Cloud_picture\cloud_%s.png'%label) # 保存图片
plt.axis('off') # 去除坐标轴
plt.show()
if __name__ == '__main__':
ws = Word2vec_similar()
# 若5 类诗歌的word2vec模型不存在,则训练生成
if os.path.exists('Data/Class_model/Keyword_biansai.model')== False:
ws.train_6poems_word2vec_model()
# # 测试:根据输入词,来判别哪一类, eg: 边塞--->边塞征战类
# key_word = '山水'
# result = ws.class_tags(key_word)
# print(result)
# 测试:判断类别后返回6个相似词,eg: 秋思-->['秋意', '寒砧', '竹声', '空阶', '窗且', '灯昏']
# key_word = '秋思'
# class_tag = '思乡羁旅'
# result = ws.similar_6words(key_word,class_tag)
# print(result)
# 测试:绘制一类诗歌的云图
file_path = 'Data\Class_model\Class_before_dealed_data/biansai.txt'
texts = open(file_path,'r',encoding='utf-8').read()
texts = texts.replace('\n','')
label = '边塞征战'
ws.Picture_file(texts,label)4、数据集:
1. 主题词分类:
分别为五类诗歌设置15个关键词,然后以维基百科为语料训练得到维基百科的word2vec模型,百度云链接如下:
链接: https://pan.baidu.com/s/11RXXyOckIW7SWUlULNNkPQ 提取码: 3egr
根据用户输入的主题词,来与各类诗歌的关键词做相似度计算,判断主题词最可能所属的诗歌类别。
2. 相似词生成:
以分好类的五类诗歌为语料,训练得到各自的word2vec模型。判断主题词类别后,以其所属类别的word2vec模型,生成6个与主题词最相似的词,作为后续生成诗歌时,每句开头字的候选集合。此处的5类诗歌各自的word2vec模型可自行训练。
我训练好的模型,百度云链接如下:
链接: https://pan.baidu.com/s/1Xkxs5tkttIoBxs_eYbZe_A 提取码: 40ux
测试时绘制了一张边塞征战类诗歌的云图:
(此图已去除诗歌题目、作者、停用词)

代码中计算《诗学含英》的6个标题词函数,是在后续LSTM模型生成诗歌时,进行每个生成字的概率权重计算时要应用的。














 854
854










 暂无认证
暂无认证


















 到【灌水乐园】发言
到【灌水乐园】发言










CSDN-Ada助手: 多亏了你这篇博客, 解决了问题: https://ask.csdn.net/questions/7996897, 请多输出高质量博客, 帮助更多的人
一蓑烟雨渡平生: 博主您好,请问修改网络后,怎么加载这一行呢?[code=python] optimizer.load_state_dict(checkpoint['optimizer_state_dict']) [/code]
qq_41317248: 请问一下博主 这个"诗学含英”的txt文件有提供吗,想学习一下
qq_41317248: 请问一下博主 这个"诗学含英”的txt文件有提供吗,想学习一下
__Eric: 原数据data做了scale处理,为什么会影响CAM的训练过程啊?