map与apply函数-日期-merge与concate—DataFrame.reindex/stack(看图) 多层行列索引(多条件索引)+转换

 已于 2023-12-26 00:27:48 修改
已于 2023-12-26 00:27:48 修改
 阅读量961
阅读量961
 收藏
2
收藏
2


 点赞数
点赞数
为了方便自己使用以免忘记而写的。
jupyter notebook取消缩进快捷键(取消缩进代码块):选中,然后Ctrl+[
jupyter notebook用清华源安装库(直接换库名就行):
# 安装导入execl库,注意:使用外网连不上清华源
# !pip install xlwings -i https://pypi.tuna.tsinghua.edu.cn/simple
#或者库放在后面
#pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyecharts==1.9.2# 保存csv、excel文件忽略索引:DataFrame.to_csv("",index=False)
#转成一维数组:y = np.array(j[j.columns].values).flatten()
#某列填充:datas['开关状态'].fillna('正常',inplace=True)
#去掉数据中的‘\t’空格
for columns_name in df_not.columns:
df_not[columns_name] = df_not[columns_name].apply(lambda x: x.strip() if isinstance(x, str) else x)
目录
2. 常用数据处理 apply函数 应用于每个值 ,agg应用于每列的聚合函数
3. 重置行列索引:
4. 索引某列值对应的行,“ | ”表示“或”
5. groupby:
all_day = predict_true_data.groupby('日期').sum()
6. pd.merge()与pd.concat()
7. 作图
8. 日期
9. filter() 过滤函数
10.遍历字典的键值
11. reindex
12. DataFrame.rename修改行列索引
13. 使用index.map
14. 获取多层索引的DataFrame值
14.1 .loc[]多层索引
14.2 根据多个行索引值选取值,法一:
14.3 使用.loc[].loc[]逐层索引,要输入行索引值
14.4 swaplevel() 交换行索引的层级关系,并全部显示行索引值 + .loc[]多层索引(‘行索引值’,‘列索引名’)
15. 根据clomuns查询:
15.1 根据外层column取值:
16. reset_index(): 将索引转化为列
17. set_index(): 指定列为索引
18. stack与unstack
19. DataFrame—droplevel
提示:对于有多层索引的DataFrame,可以用.loc[]抽出一块DataFrame,再用.loc[]依次地抽出需要用到的DataFrame,不过对于大数据速度有点慢。
借用别人一张图片:
参考网址:
https://blog.csdn.net/a321123b/article/details/121229832?spm=1001.2014.3001.5506
https://blog.csdn.net/Caiqiudan/article/details/122435560?spm=1001.2014.3001.5506
MultiIndex DataFrame多重索引的引用方法 https://blog.csdn.net/qq_30958667/article/details/126409737?spm=1001.2014.3001.5506
1. 常用数据处理 map函数 :
#从1开始序数编码
dicts_w1 = {}
dicts_w2 = {}
for i,j in enumerate(w1):
dicts_w1[j]=i+1
for i,j in enumerate(w2):
dicts_w2[j]=i+1
df_weather['天气状况1'] = df_weather['天气状况1'].map(dicts_w1)
df_weather['天气状况2'] = df_weather['天气状况2'].map(dicts_w2)
df_weather.head()
使用map()函数将列表中的每个元素平方
nums = [1, 2, 3, 4, 5]
squares = map(lambda x: x**2, nums)
print(list(squares)) # 输出:[1, 4, 9, 16, 25]
2. 常用数据处理 apply函数 应用于每个值 ,agg应用于每列的聚合函数
#季节
def date_to_season(month):
if month in (3, 4, 5):
return 0 #'春季'
elif month in (6, 7, 8):
return 1 #'夏季'
elif month in (9, 10, 11):
return 2 # '秋季'
else:
return 3 #'冬季'
df_new21['季节'] = df_new21['月'].apply(date_to_season)
df_new21.head()
——lambda函数
df['日期'] = df['数据时间'].apply(lambda x: x.split(" ")[0])
# 转时间序列:
df['数据时间'] = pd.to_datetime(df['数据时间'])
3. 重置行列索引:
#重置列索引
df1.columns = ["新列名",........................"新列名"]
df4 = self.df1.rename(columns={'交易卡号': '账户开户卡号'})
#重置行索引,索引没有对应的值会为空
df1 = df1.reindex(index)
df_new21.index = df_new21['数据时间']
或
index= pd.date_range(start='2018/1/1 00:00:00',end = '2021-08-31 23:45:00',freq="15T")
data = data.reindex(index)
4. 索引某列值对应的行,“ | ”表示“或”
df_future_weather[(df_future_weather['日期'] == '2021-09-04') | (df_future_weather['日期'] == '2021-09-09')]
5. groupby:
all_day = predict_true_data.groupby('日期').sum()
6. pd.merge()与pd.concat()
#左连节
datas = pd.merge(datas,df_word,on='数据时间',how='left')
datas.head()`pd.merge()` 和 `pd.concat()` 是 Pandas 库中常用的数据合并函数。下面解析一下这两个函数的参数:
`pd.merge()` 函数的参数:
- `left`:左侧的数据框。
- `right`:右侧的数据框。
- `on`:指定用于合并的列名或列名列表。默认为 None。如果未指定,则会自动根据两个数据框中的列名进行合并。
- `how`:指定合并的方式。可选值为 'inner'、'outer'、'left'、'right'。默认为 'inner'。'inner' 表示内连接,只保留两个数据框中共有的行;'outer' 表示外连接,保留两个数据框中所有的行,并用 NaN 填充缺失值;'left' 表示左连接,保留左侧数据框中的所有行,并用 NaN 填充右侧数据框中的缺失值;'right' 表示右连接,保留右侧数据框中的所有行,并用 NaN 填充左侧数据框中的缺失值。
- `left_on`:左侧数据框中用于合并的列名或列名列表。默认为 None。
- `right_on`:右侧数据框中用于合并的列名或列名列表。默认为 None。
- `left_index`:是否使用左侧数据框的索引作为合并的依据。默认为 False。
- `right_index`:是否使用右侧数据框的索引作为合并的依据。默认为 False。
`pd.concat()` 函数的参数:
- `objs`:要合并的数据框、Series 或者 DataFrame 的列表。
- `axis`:指定合并的轴。默认为 0,表示沿着行方向进行合并;如果设置为 1,则表示沿着列方向进行合并。
- `join`:指定合并的方式。可选值为 'inner'、'outer'。默认为 'outer'。'inner' 表示内连接,只保留所有数据框中共有的列;'outer' 表示外连接,保留所有数据框中的列,并用 NaN 填充缺失值。
- `ignore_index`:是否忽略原始数据框的索引,并重新生成新的索引。默认为 False。
- `keys`:用于创建层次化索引的标签列表或数组。默认为 None。
希望以上解析对你有所帮助。
7. 作图
colors=['#00FFFF','#FF3030']
bar_width = 0.4
plt.figure(figsize=(8,6))
for i,k in enumerate(dit_month.index):
plt.bar(np.arange(12)+bar_width*i,dit_month.loc[k,:],width=0.3,label=k,color=colors[i])
plt.xticks(np.arange(12)+0.2,dit_month.columns,rotation=60)
# 添加标题和标签
plt.title('不同销售点各月份总销售额')
plt.xlabel('月份')
plt.ylabel('销售额(万元)')
plt.legend()
plt.show()import matplotlib.pyplot as plt
# 设置字体为SimHei
plt.rcParams['font.family'] = 'SimHei'
# 创建一个图形对象
ax = plt.gca()
# 隐藏图形对象的顶部和右侧边框
ax.spines['top'].set_color('None')
ax.spines['right'].set_color('None')
# 创建一个柱状图
data = {'购买周期1': 7, '购买周期2': 0, '购买周期3': 7} # 假设有一个字典data,包含购买周期和数量
x = range(len(data))
y = list(data.values())
plt.bar(x, y, width=0.3)
# 设置x轴刻度标签
plt.xticks(x, data.keys())
# 添加柱状图标签
for i, v in enumerate(y):
plt.text(i, v, str(v), ha='center', va='bottom')
# 添加x轴和y轴标签
plt.xlabel('购买周期')
plt.ylabel('数量')
# 显示图形
plt.show()
8. 日期
转文本: datas4['年月'] = datas4['日期'].dt.strftime("%y/%m") "%Y/%m/%d"有完整年份
datas4.head(1)

提取小时:df['时间'] = pd.to_datetime(df['时间'], format='%H:%M').dt.time
在pandas中,`dt`是一个日期时间访问器(Datetime Accessor),它提供了一组方便的方法,用于在`Series`或`DataFrame`中处理日期时间数据。
`dt`访问器可以应用于`Series`对象的日期时间列,它使您能够轻松地访问和操作日期时间的各个组成部分,如年、月、日、小时、分钟、秒等。以下是一些常用的`dt`方法:
- `dt.year`:获取日期时间的年份。
- `dt.month`:获取日期时间的月份。
- `dt.day`:获取日期时间的日。
- `dt.hour`:获取日期时间的小时。
- `dt.minute`:获取日期时间的分钟。
- `dt.second`:获取日期时间的秒。
- `dt.weekday`:获取日期时间的星期几(0表示星期一,6表示星期日)。
- `dt.weekday_name`:获取日期时间的星期几的名称。
- `dt.strftime()`:将日期时间格式化为指定的字符串格式。
通过使用`dt`访问器,您可以方便地提取和操作日期时间的不同部分,进行日期时间的比较和筛选,以及将日期时间转换为不同的字符串格式。这对于数据分析和处理时间序列数据非常有用。
9. filter() 过滤函数
filter() 函数接收一个函数和一个可迭代对象作为参数,并返回一个新的可迭代对象,该对象包含所有使该函数返回 True 的元素。
# 使用filter()函数筛选出列表中的偶数
nums = [1, 2, 3, 4, 5]
evens = filter(lambda x: x % 2 == 0, nums)
print(list(evens)) # 输出:[2, 4]10.遍历字典的键值
在Python中,可以使用for循环来遍历字典的键值。以下是两种常见的方法:
my_dict = {"key1": "value1", "key2": "value2", "key3": "value3"}
for key, value in my_dict.items():
print(key, value)my_dict = {"key1": "value1", "key2": "value2", "key3": "value3"}
for key in my_dict.keys():
value = my_dict[key]
print(key, value)11. reindex
reindex执行的是索引重组操作,接收一组标签序列作为新索引,既适用于行索引也适用于列标签名,重组之后索引数量可能发生变化,索引名为传入标签序列
rename执行的是索引重命名操作,接收一个字典映射或一个变换函数,也均适用于行列索引,重命名之后索引数量不发生改变,索引名可能发生变化
另外二者执行功能和接收参数的套路也是很为相近的,均支持两种变换方式:
一种是变换内容+axis指定作用轴(可选0/1或index/columns);
另一种是直接用index/columns关键字指定作用轴
#具体而言,reindex执行索引重组操作,以新接收的一组标签序列作为索引,
#当原DataFrame中存在该索引时则提取相应行或列,否则赋值为空或填充指定值。
#对于前面介绍的示例数据df,以重组行索引为例,
df2 = pd.DataFrame([('bird', 389.0),
('bird', 24.0),
('mammal', 80.5),
('mammal', np.nan)],
index=['falcon', 'parrot', 'lion', 'monkey'],
columns=('class', 'max_speed'))
df2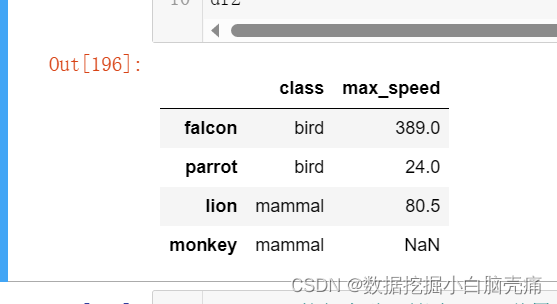
#axis=0 按行索引 不能与index共用
df2.reindex(labels=['falcon','parrot'],axis=0)
# 按新的索引名索引,匹配原索引则显示值,不匹配则以空值或其他值填充
df2.reindex(labels=['falcon','parrot',1,2],axis=0)
df2.reindex(index=['falcon','parrot',1,2])
#以fill_value填充空值
df2.reindex(index=['falcon','parrot',1,2],fill_value='没有')
df2.reindex(labels=['falcon','parrot',1,2],axis=0,fill_value='没有')
df2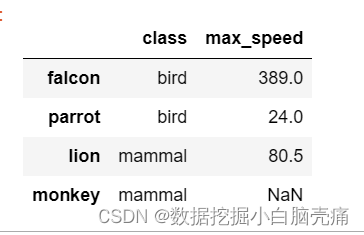
# 用method 进行填充,不行有问题
df2.index=(1,2,3,4)
df2.reindex(index=[1,2,3,6],method='ffill')
df2.fillna('a')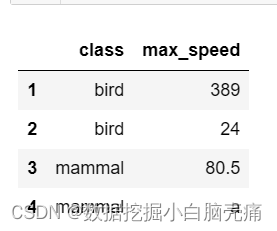
12. DataFrame.rename修改行列索引
pd.rename修改 (可修改部分索引)
Series.rename(index=None, *, axis=None, copy=True, inplace=False, level=None, errors=‘ignore’)
df2 = pd.DataFrame([('bird', 389.0),
('bird', 24.0),
('mammal', 80.5),
('mammal', np.nan)],
index=['falcon', 'parrot', 'lion', 'monkey'],
columns=('class', 'max_speed'))
df2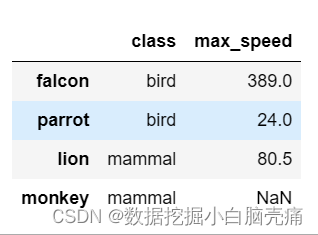
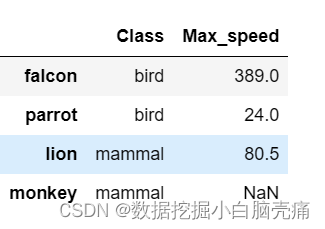
#修改列索引名
df2.columns=['Class', 'Max_speed']
df2
#使用mapper+axis修改行索引
df2.rename(mapper={1:0},axis=0)
#使用匿名函数
df2.rename(index=lambda x:x+str('_1'))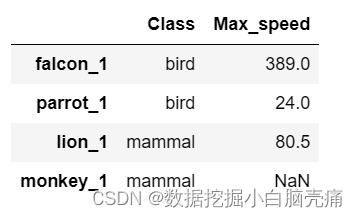
df2.rename(index={'Falcon':'falcon', 'Parrot':'parrot', 'Lion':'lion', 'Monkey':'monkey'},
columns={'Class':'class', 'Max_speed':'max_speed'}, inplace=True)
df2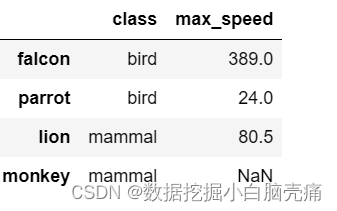
13. 使用index.map
# 3. 使用index.map
针对DataFrame中的数据,pandas中提供了一对功能有些相近的接口:map和apply,以及applymap,其中map仅可用于DataFrame中的一列(也即即Series),可接收字典或函数完成单列数据的变换;apply既可用于一列(即Series)也可用于多列(即DataFrame),但仅可接收函数作为参数,当作用于Series时对每个元素进行变换,作用于DataFrame时对其中的每一行或每一列进行变换;而applymap则仅可作用于DataFrame,且作用对象是对DataFrame中的每个元素进行变换。也就是说,三者的最大不同在于作用范围以及变换方式的不同。
实际上,apply和map还有一个细微区别在于:同样是可作用于单列对象,apply适用于索引这种特殊的单列,而map则不适用。所以,对索引执行变换的另一种可选方式是用map函数,其具体操作方式与DataFrame常规map操作一致,接收一个函数作为参数即可:
def aggs(x):
return x+'44'
df2.index.map(lambda x:aggs(x))

14. 获取多层索引的DataFrame值
提示:对于有多层索引的DataFrame,可以用.loc[]抽出一块DataFrame,再用.loc[]依次地抽出需要用到的DataFrame,不过对于大数据速度有点慢,输入的是行索引值,输入行索引名会报错
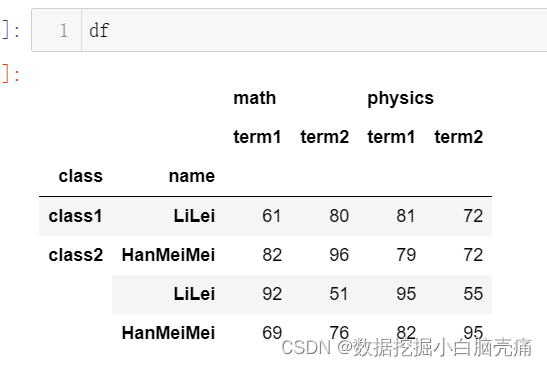
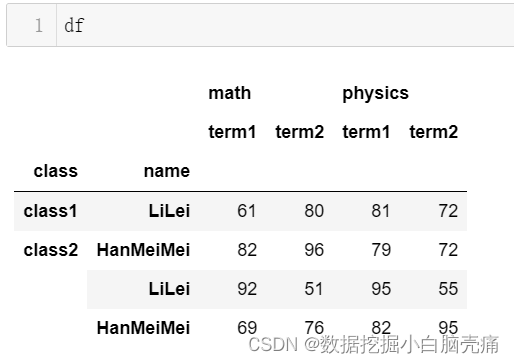
df = pd.DataFrame(np.random.randint(50, 100, size=(4, 4)), #任意生成4行4列50至100的整数
columns=pd.MultiIndex.from_product( #第一层列名['math', 'physics'],第二层['term1', 'term2']
[['math', 'physics'], ['term1', 'term2']]), #'math'和 'physics'下分别都有['term1', 'term2']
index=pd.MultiIndex.from_tuples( #元组第一元素是第一层索引值,第二个元素是第二层索引值
[('class1', 'LiLei'), ('class2', 'HanMeiMei'),
('class2', 'LiLei'), ('class2', 'HanMeiMei')]))
df
df.index.names = ['class', 'name'] #添加对应行索引值的行索引名
df
14.1 .loc[]多层索引
df.loc[('class1','LiLei'),'math'] #必须是值('class1','LiLei'),行名会报错
# 取第一层索引值为'class1'的数据
df1 = df.loc['class1']
df1
14.2 根据多个行索引值选取值,法一:
# 根据多个行索引值选取值,法一:
df.loc[('class2', 'HanMeiMei')]
14.3 使用.loc[].loc[]逐层索引,要输入行索引值
#输入的是索引值
df.loc['class2'].loc['HanMeiMei']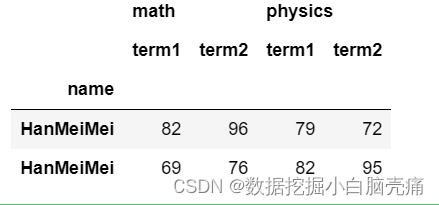
14.4 swaplevel() 交换行索引的层级关系,并全部显示行索引值 + .loc[]多层索引(‘行索引值’,‘列索引名’)

df.swaplevel() ##交换行索引轴,默认 axis=0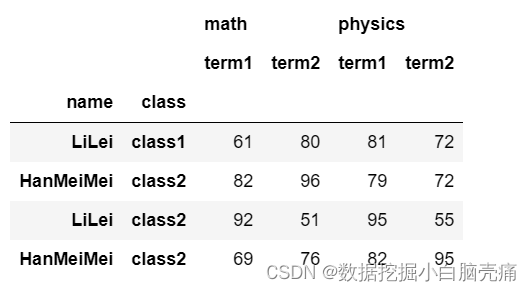
df.swaplevel(axis=1) #交换列索引轴
##交换列索引轴后索引某列
df.swaplevel(axis=1)['term1']
#根据行索引值索引
df.swaplevel().loc['HanMeiMei']
df.swaplevel().loc[('HanMeiMei','class2')]
df.swaplevel().loc[('HanMeiMei','class2'),'math']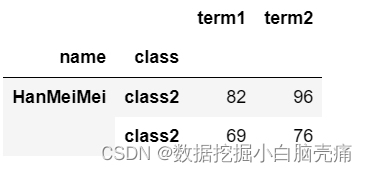
df_s_loc = df.swaplevel().loc[('HanMeiMei','class2'),('math','term2')]
df_s_loc
15. 根据clomuns查询:

15.1 根据外层column取值:

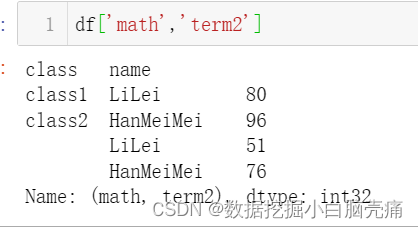


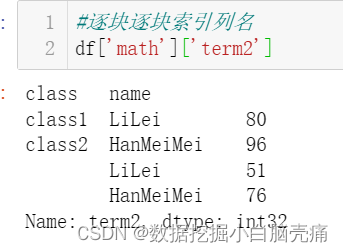
16. reset_index(): 将索引转化为列
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=’’)
level: 用于指定要将层次化索引的第几层转化为columns,第一个索引为0级,第二个为1级,默认为None(全部索引)。也可以用list的形式表示
drop: 是否删除索引列,默认False。
inplace: 是否修改原数据
col_level: 当有多列索引时,选取特定层级转换为列
col_fill: 当有多列索引时,确定转换为列的索引的名称

# 把行索引值全部显示出来,均转为列。行索引已更新
df.reset_index()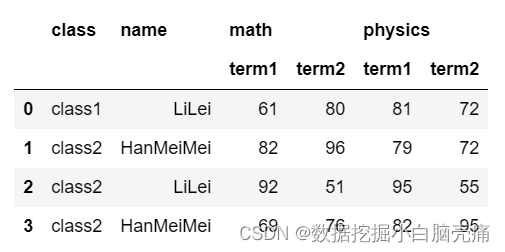
df.reset_index(level=0)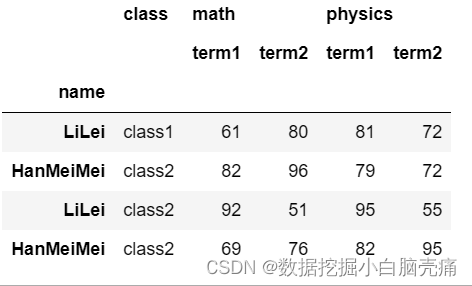
df.reset_index(level=1)
# 将某个行索引值转为一列值
df.reset_index('name')#['name']
#将多层行索引名设置为列
df.reset_index(['class','name'])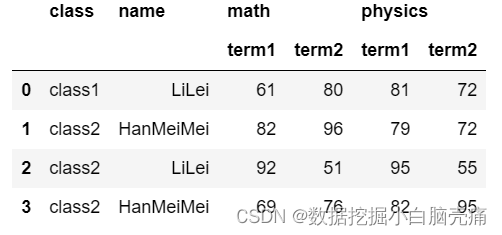
#将多层行索引名设置为列
df.reset_index(('class','name'))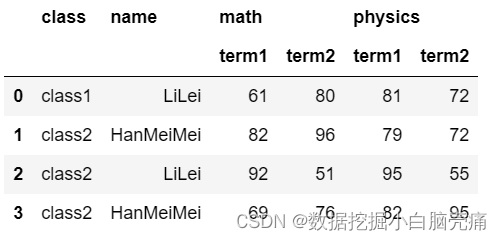
17. set_index(): 指定列为索引
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
keys: 设置为索引的列名,以list的形式表示 drop: 是否删除被设为索引的列,默认True(删除) append: 是否将新索引列附加到旧索引列上,默认False(不附加) inplace: 是否修改原数据,默认为False verify_integrity: 检查索引是否重复。默认False。
#指定某列为索引
df.set_index(('math','term1'))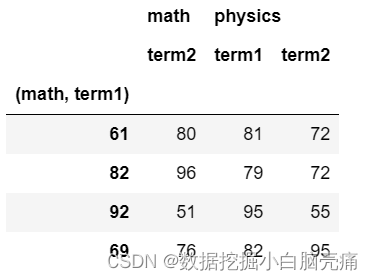
# 也可以保留改索引的列
df.set_index(('math','term1'), drop=False)
#指定多列作为索引
df.set_index([('math','term1'),('math','term2')],drop=False)
# append: 是否将新索引列附加到旧索引列上,默认False(不附加)
df.set_index([('math','term1'),('math','term2')],drop=False,append=True)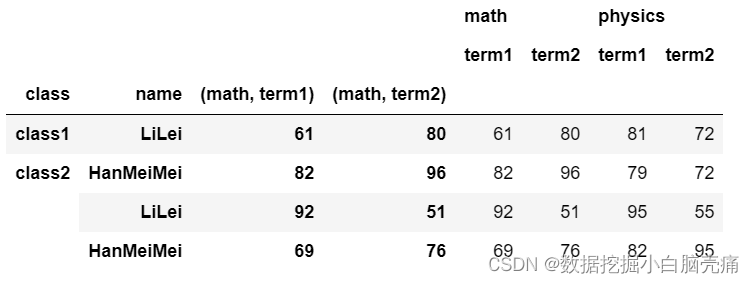
18. stack与unstack
这也是一对互逆的操作,其中stack原义表示堆叠,实现将所有列标签堆叠到行索引中;unstack即解堆,用于将复合行索引中的一个维度索引平铺到列标签中。实际上,二者的操作即是SQL中经典的行转列与列转行,也即在长表与宽表之间转换。


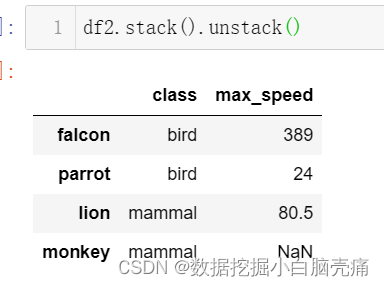

19. DataFrame—droplevel
#删除行名'class'
df.droplevel('class')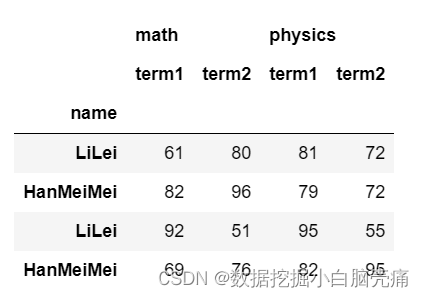
df3 = pd.DataFrame([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]]).set_index([0, 1]).rename_axis(['a', 'b'])
df3.columns = pd.MultiIndex.from_tuples([
('c', 'e'), ('d', 'f')], names=['level_1', 'level_2'])
df3
df3.droplevel('level_2', axis=1)















 1万+
1万+
















 到【灌水乐园】发言
到【灌水乐园】发言










gund1f: 我遇到同样的问题,是sqlalchemy版本太高,降版本就可以了,感谢博主分享
CSDN-Ada助手: 恭喜您写了第12篇博客!不过我注意到标题里提到了一个“不良方法”,我希望您在下一篇博客里能够分享更多安全可靠的方法,让读者能够更好地学习和理解。继续加油,期待您的下一篇作品!
CSDN-Ada助手: 恭喜你写了第10篇博客!不过很抱歉听到你在导入mysql时遇到了问题。或许你可以尝试检查一下参数传递是否正确,或者尝试使用其他方法导入数据。希望你能解决这个问题并继续分享你的经验。另外,也许你可以考虑写一些关于数据处理或者数据库优化方面的内容,这对读者可能会有所帮助。加油!期待你的下一篇文章。
wh~~: 能帮上忙就好
饿de慌: 多谢博主分享,方法一配置不行,方法二可以。