爬了链家二手房数据来告诉你深圳房价到底多恐怖!
最新推荐文章于 2021-03-19 23:41:34 发布

AwesomeTang
 最新推荐文章于 2021-03-19 23:41:34 发布
最新推荐文章于 2021-03-19 23:41:34 发布
 阅读量1.3k
阅读量1.3k
 收藏
10
收藏
10
 点赞数
3
点赞数
3
最新推荐文章于 2021-03-19 23:41:34 发布
阅读量1.3k
收藏
10

 点赞数
3
点赞数
3
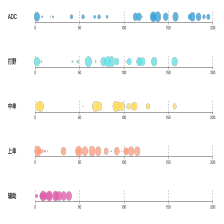
使用Pyecharts对链家上的深圳二手房信息进行可视化分析,内容包括:
- 房屋面积与房屋总价散点图分布;
- 各行政区二手房均价;
- 均价最贵的10个地段;
- 户型分布;
- 标题中最常出现的词;
数据背景
- 数据来源:链家二手房上深圳的房源信息「后附爬虫代码」;
- 数量:共采集数据总量***18841***条,数据清洗后***18811***条;
- 数据字段:
字段名称 解释 area 房屋面积 area_positon 所属行政区「南山/福田等」 community 所属小区 direction 房屋朝向 elevator 有无电梯 fitment 装修情况「精装/简装/其他」 floorInfo 楼层信息「高层/中层」 hourseType 户型「三室两厅等」 position 位置「科技园/香蜜湖等」 price 房屋总价 title 房源信息标题 unit-price 每平米单价
项目内容
准备工作
- 导入项目所需第三方库以及数据:
import pandas as pd
import pyecharts
data['area'] = data['area'].str.replace(u'平米','')
data['area'] = data['area'].astype('float')
#去掉房屋面积中「平米」并保存为浮点型
data['unit-price'] = data['price']/data['area']
#生成每平方米房屋单价
data = data.round(1)
data.head()
房价整体分布
我们借助散点图来看目前深圳二手房价格的整体分布情况:
scatter = pyecharts.Scatter("总价-面积散点图",'统计时间:2018-9-22')
scatter.add('🏠总价(单位:万元)',data['area'],data['price'],is_legend_show = False, visual_pos = 'right',
is_visualmap = True,visual_type="color",visual_range=[100, 1000],mark_point=['max'],
xaxis_name = '面积' , yaxis_name = '总价')
scatter
- 目前标价最高的一套房子位于深圳湾,面积600平米,价格9800W❗️❗️❗️
- 红色的点是房屋总价超过1000W的,当然可能这个散点图会存在一点误导,因为1000W以上的房源价格浮动比较大,导致红色部分视觉上占了大部分,实际上我们获取到的1.8W房源信息中,1000W以上的共1994条记录,占比11%,绝大部分的还是集中在500W左右。
- 所获取到的1.8W条房源信息中整体均价6.4W每平米。
各行政区均价
需要说明一点,我们采集的数据中未包含大鹏新区/光明新区,因为这两个新区房源信息较少,加上pyecharts里面深圳的行政区也未包含这两个新区,所以没将这两个区的数据统计在内:
temp = data.groupby(['area_positon'])['unit-price'].mean().reset_index()
temp = temp.round(1)
attr = list(temp['area_positon'])
value = list(temp['unit-price'])
map = pyecharts.Map("深圳各行政区二手房均价", "统计时间:2018-09-22", width=800, height=600)
map.add(
"二手房均价(单位:万元)", attr, value, maptype= u"深圳",is_legend_show = False,is_label_show = True,
is_visualmap=True, visual_text_color="#000",visual_range=[3, 8]
)
map
- 本来pyecharts的交互优势到了文章页面却反而有点鸡肋了 ,具体均价如下:
| 行政区 | 二手房均价 |
|---|---|
| 南山区 | 8.1万元/平米 |
| 坪山区 | 3.6万元/平米 |
| 宝安区 | 6.0万元/平米 |
| 盐田区 | 4.7万元/平米 |
| 福田区 | 7.0万元/平米 |
| 罗湖区 | 5.5万元/平米 |
| 龙华区 | 5.5万元/平米 |
| 龙岗区 | 4.4万元/平米 |
- 目前最贵的还是南山区,整体均价8.1W每平米,最便宜的坪山区,均价3.6W每平米;
- 关内来说,最便宜的是盐田区,均价4.7W每平,不过房源较少;
- 关外最贵的是宝安区,均价6W,不过宝安区辖区面积大,价格跨度也比较广。
最贵的10个地段
看完了各行政区的均价,我们来看下更具体的,目前深圳房价最贵的10各地段都是什么位置:
temp = data.groupby(['position'])['unit-price'].mean().reset_index()
temp = temp.round(1)
temp = temp.nlargest(10,'unit-price').reset_index()
attr = list(temp['position'])
value = list(temp['unit-price'])
Bar = pyecharts.Bar("深圳房价最高的10个地段", "统计时间:2018-09-22")
Bar.add("每平米均价(单位:万元)", attr, value,mark_point=['max'],is_legend_show = False,is_label_show = True)
Bar
- 深圳湾共计43套房源,整体均价15.2W每平米,甩开其他地段好几个身位;
- 唯一属于的关外地段宝安中心,排名第10,均价8.2W;
户型分布
户型里面有点凌乱,一些比较奇怪的户型(如8室0厅)就没算在里面,只取了数量前10的户型。
temp = data.groupby(['hourseType'])['unit-price'].count().reset_index()
temp.columns = ['hourseType','counter']
temp = temp.nlargest(10,'counter')
Pie = pyecharts.Pie('户型占比','统计时间:2018-9-22')
Pie.add("🏠🏠", temp['hourseType'], temp['counter'],
radius=[20, 75], rosetype='radius',
is_legend_show=False, is_label_show=True)
Pie
- 三室两厅是在出售的房源中占比最多,为25.9%,这也应该是目前最符合中国家庭的户型分布了;
- 在深圳如此高昂的房价压迫下,小户型也挺受欢迎,一室一厅,两室一厅也有不小的占比;
词频统计
获取到的标题是房屋中介或者业主在链家上发布房源时填写的标题信息,想要获得关注,一个抓人眼球的标题肯定不能少,透过标题我们也能发现目前买家都会关注哪些信息,我们来看看,标题中最常出现的都是什么词语:
from jieba import posseg as psg
import collections
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
'''
分词部分
'''
word_list = []
stop_words = ['花园','业主','出售']
string = str(''.join(data['title']))
words = psg.cut(string)
for x in words:
if len(x.word)==1:
pass
elif x.flag == 'x':
pass
elif x.word in stop_words:
pass
else:
word_list.append(x.word)
c = collections.Counter(word_list)
attr = []
value = []
for x in c.most_common(10):
attr.append(x[0])
value.append(x[1])
'''
柱形图
'''
Bar = pyecharts.Bar("标题中出现频率最高的10个词", "统计时间:2018-09-22")
Bar.add("出现次数", attr, value,mark_point=['max'],is_legend_show = False)
Bar.render
Bar
- 生成词云
import imageio
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
back_color = imageio.imread('house.jpeg')
words = ' '.join(word_list)
wc = WordCloud(background_color='white',
max_words=5000,
mask=back_color,
max_font_size=200,
font_path="/Users/~/Documents/fonts/SimHei.ttf",
random_state=None
)
wc.generate(words)
image_colors = ImageColorGenerator(back_color)
plt.figure(figsize = (15,8))
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis('off')
plt.show()
wc.to_file('comment.png')
效果如下:
最后
太TM贵了!
附爬虫代码:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import lxml
import re
import pandas as pd
from tqdm import tqdm
import math
class lianjia():
def __init__(self):
print '*******lianjia_spider******'
print 'Author : Awesome_Tang'
print 'Date : 2018-09-16'
print 'Version: Python2.7'
print '**************************\n'
self.pattern = re.compile('<div class="info clear">.*?target="_blank">(.*?)</a>.*?class="houseInfo"><span class="houseIcon">.*?target="_blank">(.*?)</a>(.*?)</div>.*?class="positionIcon"></span>(.*?)<a href=.*?target="_blank">(.*?)</a>.*?class="totalPrice"><span>(.*?)</span>万')
self.house_num_pattern = re.compile(u'共找到<span> (.*?) </span>套深圳二手房')
self.area_dic = {'罗湖区':'luohuqu',
'福田区':'futianqu',
'南山区':'nanshanqu',
'盐田区':'yantianqu',
'宝安区':'baoanqu',
'龙岗区':'longgangqu',
'龙华区':'longhuaqu',
'坪山区':'pingshanqu'}
def get_info(self,url):
html = requests.get(url).text
html = html.encode('utf-8')
soup=BeautifulSoup(html,'lxml')
infos=soup.find_all(class_="info clear")
return infos
def get_content(self,info,area):
info_dic = {}
info = re.findall(self.pattern,str(info))
info = list(info[0])
info_dic['title'] = info[0].strip()
info_dic['community'] = info[1].strip()
house_list = info[2].split('|')
if len(house_list) == 6:
info_dic['hourseType'] = house_list[1].strip()
info_dic['area'] = house_list[2].strip()
info_dic['direction'] = house_list[3].strip()
info_dic['fitment'] = house_list[4].strip()
info_dic['elevator'] = house_list[5].strip()
else:
info_dic['hourseType'] = house_list[1].strip()
info_dic['area'] = house_list[2].strip()
info_dic['direction'] = house_list[3].strip()
info_dic['fitment'] = '其他'
info_dic['elevator'] = house_list[4].strip()
info_dic['floorInfo'] = info[3].strip(' - ')
info_dic['position'] = info[4].strip()
info_dic['price'] = info[5].strip()
info_dic['area_positon'] = area
return info_dic
def run(self):
data = pd.DataFrame()
for area in self.area_dic.keys():
print '>>>> 正在保存%s的二手房信息>>>\n'%area
url = 'https://sz.lianjia.com/ershoufang/%s/'%self.area_dic[area]
r = requests.get(url).text
house_num = re.findall(self.house_num_pattern,r)[0].strip()
total_page = int(math.ceil(int(house_num)/30.0))
if total_page >= 100:
total_page = 100
else:
pass
for page in tqdm(range(total_page)):
url = 'https://sz.lianjia.com/ershoufang/%s/pg%s/'%(self.area_dic[area],str(page+1))
infos = self.get_info(url)
for info in infos:
info_dic = self.get_content(info,area)
if data.empty:
data = pd.DataFrame(info_dic,index=[0])
else:
data = data.append(info_dic,ignore_index = True)
data.to_csv('lianjia.csv',encoding = 'utf-8-sig')
print '>>>> 链家二手房数据已保存❗️❗️❗️'
if __name__ == '__main__':
x = lianjia()
x.run()
















 2254
2254











 Python领域优质创作者
Python领域优质创作者





















 到【灌水乐园】发言
到【灌水乐园】发言












Liberty812: 升序和降序那两个是不是写差东西呀
ζ珊大宝~: 请问最后一个的多个环形图的代码for _, row in t_data.iterrows(): if idx % 2 == 0: x = 30 y = int(idx / 2) * 22 + 18 else: x = 70 y = int(idx / 2) * 22 + 18 idx += 1 pos_x = str(x) + '%' pos_y = str(y) + '%' pie.add( row['Sport'], [[row['region'], row['Event_x']], ['其他国家', row['Event_y'] - row['Event_x']]], center=[pos_x, pos_y], radius=[70, 100], label_opts=new_label_opts())什么意思哇
GouDX: 不出现地图是啥情况呀
Penna_a: 请教下Gauge仪表盘颜色设置成渐变色应该怎么操作呢?
Nemo-Wang: from pyecharts.datasets import register_url报错是为什么啊