全国历史天气查询/历史天气预报查询——全国各月份数据爬取

 最新推荐文章于 2024-05-16 15:57:11 发布
最新推荐文章于 2024-05-16 15:57:11 发布
 阅读量1w
阅读量1w
 收藏
51
收藏
51


 点赞数
7
点赞数
7

全国历史天气查询/历史天气预报查询——全国各月份数据爬取
效果
 图1 目标爬取数据 图1 目标爬取数据
|
 图2 最终实验效果 图2 最终实验效果
|
实验效果:最终可将官网已有的数据进行爬取整理,共363个城市,从2011年1月——至今
数据已上传至CSDN,若无C币的小伙伴可以自行爬取或至QQ群:782589269,群文件中免费下载使用
目录
- 全国历史天气查询/历史天气预报查询——全国各月份数据爬取
- 效果
- 导入所需库
- 分析官网HTML内容
- 使用正则抽取所需的城市名信息
- 爬取全部的城市名与链接
- 保存城市名与基链接
- 各城市的月份数据爬取
全国历史天气查询_历史天气预报查询_温度查询_天气后报官网,戳它直达!
导入所需库
import os
import re
import time
import pandas as pd
from tqdm import tqdm
import pickle
import requests
分析官网HTML内容
首先,进行官网HTML内容的分析,找出我们所需信息的代码段
官网链接:http://www.tianqihoubao.com/lishi/
url = "http://www.tianqihoubao.com/lishi/"
url_request = requests.get(url)
url_request.encoding = 'gb2312'
url_text = url_request.text
print(url_text)

可以看出我们要爬取的城市名在,诸如这样的<a>城市名</a>代码块
<a href="/lishi/bj.htm" title=“北京历史天气预报”><b>北京</b></a>
使用正则抽取所需的城市名信息
若不懂正则表达式,在此,你只需了解在正则表达式中可以用(\w+)来提取所需内容即可
比如对于上例中的链接,将其中的‘北京’换成(\w+)即可,对于各城市相同的部分保持不变,各城市不同的部分使用正则表达式替换,不加括号代表不提取,即\w+
因此,可以得到下述pattern提取公式
url ='<a href="/lishi/beijing.html" title="北京历史天气查询">北京 </a>'
pattern = '<a href="/lishi/(\w+.html)" title="\w+">(\w+) </a>'
实验测试
exapmle_text = '<a href="/lishi/beijing.html" title="北京历史天气查询">北京 </a>'
pattern = re.compile(r'<a href="/lishi/(\w+.html)" title="\w+">(\w+) </a>')
example_city = pattern.findall(exapmle_text)
print(example_city)

爬取全部的城市名与链接
pattern = re.compile(r'<a href="/lishi/(\w+.html)" title="\w+">(\w+) </a>')
citys = pattern.findall(url_text) # 获取363个城市名
print("已获取{}个城市名,第一个城市是{},最后一个城市是{}".format(len(citys),citys[0],citys[-1]))

进行城市各月份链接的爬取,以同样的方法分析其中一个城市的各月份链接地址,如北京
北京2011年1月的链接为
http://www.tianqihoubao.com/lishi/beijing/month/201101.html
北京2011年2月的链接为
http://www.tianqihoubao.com/lishi/beijing/month/201102.html
可以得到如下规律
- 基地址:http://www.tianqihoubao.com/lishi/
- 城市地址:beijing/
- 月份地址:month/201101.html
- 各个城市的月份链接地址=基地址+城市地址+月份地址
以此规律进行爬取即可?
不可,在笔者尝试N次后,发现必然部分城市数据爬取不全,为什么呢?因为这个网站的HTML语言不是均按照上述规律写的(可能官网的程序员中途换人了,真的太让人头秃了)
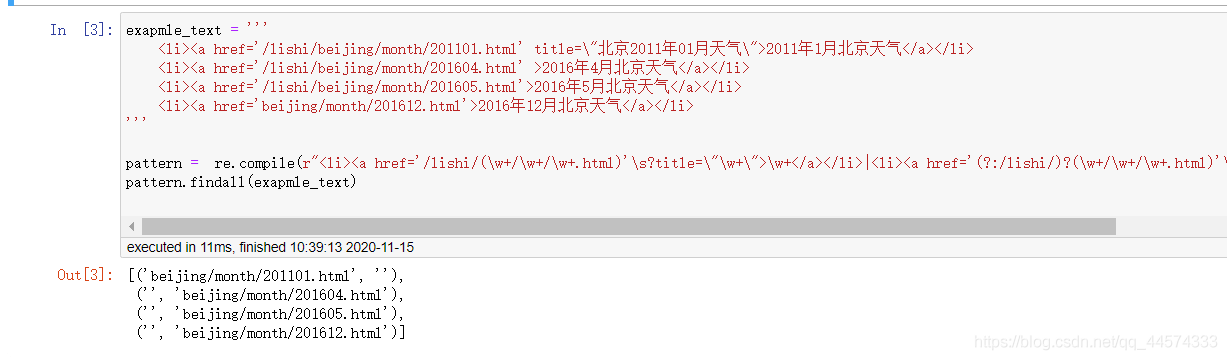
实验发现,大约对于同一个城市有大约这样四种神奇的HTML语言格式,在此就是一展你正则表达式的水平的时候了…(写了个爬虫,正则倒是进步了)
exapmle_text = '''
<li><a href='/lishi/beijing/month/201101.html' title=\"北京2011年01月天气\">2011年1月北京天气</a></li>
<li><a href='/lishi/beijing/month/201604.html' >2016年4月北京天气</a></li>
<li><a href='/lishi/beijing/month/201605.html'>2016年5月北京天气</a></li>
<li><a href='beijing/month/201612.html'>2016年12月北京天气</a></li>
'''
pattern = re.compile(r"<li><a href='/lishi/(\w+/\w+/\w+.html)'\s?title=\"\w+\">\w+</a></li>|<li><a href='(?:/lishi/)?(\w+/\w+/\w+.html)'\s?>\w+</a></li>")
pattern.findall(exapmle_text)
进行城市月份数据的爬取
city_urls = {}
base_url = 'http://www.tianqihoubao.com/lishi/'
for url_city in citys:
url,city = url_city
city_base_url = base_url + url
city_urls[city] = []
pattern = re.compile(r"<li><a href='/lishi/(\w+/\w+/\w+.html)'\s?title=\"\w+\">\w+</a></li>|<li><a href='(?:/lishi/)?(\w+/\w+/\w+.html)'\s?>\w+</a></li>")
city_url_request = requests.get(city_base_url)
for tuple_ in pattern.findall(city_url_request.text):
i,j = tuple_
if i.strip():
i = base_url + i
city_urls[city].append(i)
else:
j = base_url + j
city_urls[city].append(j)
print('{}:{}份数据'.format(city,len(city_urls[city])))
print('示例链接:',city_urls[city][0],'\n')
保存城市名与基链接
本地保存后,即使后面实验失败了,也可以从此再次断点重启
通过pickle保存字典
with open("city_urls.file", "wb") as f:
pickle.dump(city_urls, f)
# 通过pickle读取字典
with open("city_urls.file", "rb") as f:
city_urls = pickle.load(f)
各城市的月份数据爬取
df:将保存所有数据,以城市列为区分
df_city:将保存各个城市单独的数据
error:不断记录爬取失败的城市与对应链接
df = pd.DataFrame(columns = ['日期', '天气状况', '气温', '风力风向','城市'])
error = []
for city in tqdm(city_urls.keys()):
df_city = pd.DataFrame(columns = ['日期', '天气状况', '气温', '风力风向','城市'])
if city + '.csv' in os.listdir('./output/'):
continue
for month_url in city_urls[city]:
try:
dataframe = pd.read_html(month_url,encoding = 'gb2312')[0]
if dataframe.shape[0] == 0:
dataframe = pd.DataFrame(columns = ['日期', '天气状况', '气温', '风力风向','城市'])
dataframe.loc[0,:] = [None,None,None,None,city]
else:
dataframe = dataframe.loc[1:,:]
dataframe.columns = ['日期', '天气状况', '气温', '风力风向']
dataframe['城市'] = city
df_city = df_city.append(dataframe)
df = df.append(dataframe)
except:
print('Error')
print(month_url)
error.append((city,month_url))
continue
df_city.to_csv('./output/'+city+'.csv',index=False)
print('城市:\t',city,'数据收集完毕')
print('所有城市数据,已收集完成!')

















 439
439










 暂无认证
暂无认证





























 到【灌水乐园】发言
到【灌水乐园】发言












云野の风: 别的没看,溢出判断那里的图,负数的补码是反码加一,图是错的
jjkkk9: 想问您花了多久时间爬完363个市的所有历史气象数据呀,我这边总是卡,好久才完成一个
jjkkk9: 想问一下中间经常卡住怎么解决呀
jjkkk9: 你好,这个网站 能爬到记录到县的历史其后数据吗
做而论道_CS: 计算机刚诞生时,基本器件是电子管。 CPU (运算器控制器) 是由几个大型机柜组成的。 占地上百平米,耗电多少多少瓦,... 。 在这种条件下,才能说: CPU 只有加法器,没有减法器; 必须用补码相加,来实现减法运算。 ---------------- 经历了 “晶体管、集成电路、大规模集成电路” 时代, 你还以为计算机【没有减法器】吗? 你的想法,肯定是错的! 用集成电路,做一个减法器,已经是轻而易举了。 现在想做减法,直接就可以做了。 根本就不用 “用补码相加” 了。 你写这些,太落后了。 ---------------- 终于知道我们为什么缺芯片用了。 就是被你们这些 “专家” 耽误了。