使用gcc编译代码时的具体过程

 已于 2022-09-23 16:28:27 修改
已于 2022-09-23 16:28:27 修改
 阅读量1.4k
阅读量1.4k
 收藏
4
收藏
4


 点赞数
1
点赞数
1
目录
- 前言
- 一、以一个熟悉的代码为例子
- 1、一步到位的编译
- 2.代码的编译过程
- 2.1 预处理
- 2.2 编译为汇编代码
- 2.3汇编
- 2.4 链接(连接)
- 2.5 多个代码的编译过程
- 2.6 检错
- 2.7库文件连接
- 总结
前言
gcc 是我们在进行Linux编程时常用的编译工具,可支持多种编程语言,本文将讨论gcc编译代码的具体步骤
一、以一个熟悉的代码为例子
我们以最熟悉的“hello world”代码为例
代码如下
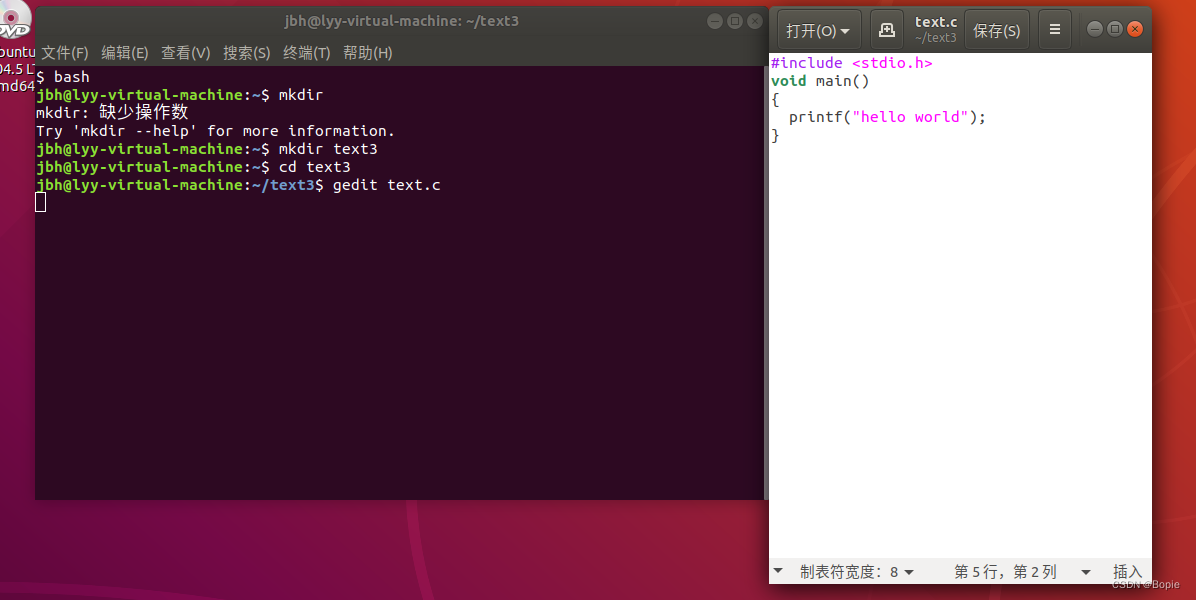
1、一步到位的编译
代码如下
gcc text.c -0 text

2.代码的编译过程
2.1 预处理
预处理的过程包括:
(1)将所有的#define删除,并且展开所有的宏定义,并且处理所有的条件预编译指令,比如#if #ifdef #elif #else #endif 等。
(2)处理#include预编译指令,将被包含的文件插入到该预编译指令的位置。
(3)删除所有注释“//”和“/**/”。
(4)添加行号和文件标识,以便编译时产生调试用的行号及编译错误警告行号(5)保留所有的#pragma编译器指令,后续编译过程需要使用它们。
代码如下
gcc -E text.c 或gcc -E text.c -o text,i
若选择输出后者,可以发现打开的 text.i 文件存放的是text.c预处理后的代码
``
gcc -E 表示编译过程在预处理后停止
2.2 编译为汇编代码
代码如下
gcc -s text.i -o text.s

2.3汇编
代码如下:
gcc -c text.s -o text.o

2.4 链接(连接)
链接分为静态链接和动态链接。
(1)静态链接是指在编译阶段直接把静态库加入到可执行文件中去,这样可执行文件会比较大。链接器将函数的代码从其所在地(不同的目标文件或静态链接库中)拷贝到最终的可执行程序中。为创建可执行文件,链接器必须要完成的主要任务是:符号解析(把目标文件中符号的定义和引用联系起来)和重定位(把符号定义和内存地址对应起来然后修改所有对符号的引用)。
(2)动态链接则是指链接阶段仅仅只加入一些描述信息,而程序执行时再从系统中把相应动态库加载到内存中去。
代码如下
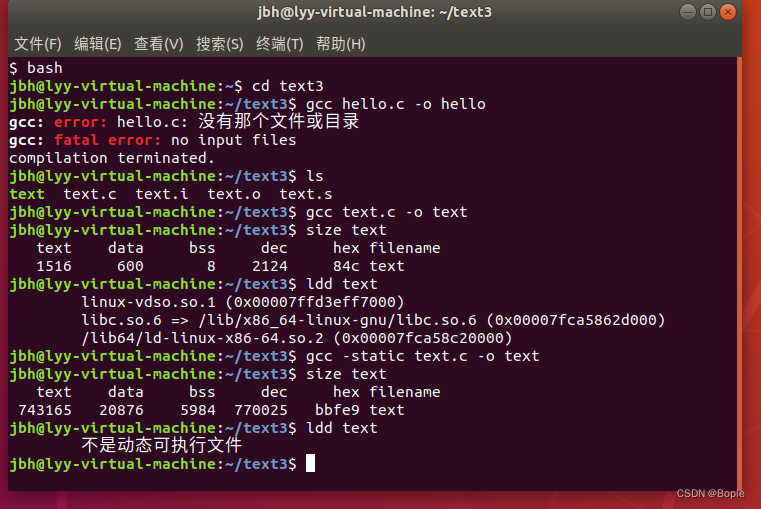
(静态链接)

(动态链接)
2.5 多个代码的编译过程
若存在 text1.c text2.c 等多个源文件 gcc也是可以十分有效的完成编译的
代码如下
gcc text1.c text2.c -c text
或者
gcc -c text1.c -o text1.o
gcc -c text2.c -o text2.o
gcc text1.o text2.o text
2.6 检错
-pedantic编译选项并不能保证被编译程序与ANSISOC标准的完全兼容,它仅仅只能用来帮助Linux程序员离这个目标越来越近。或者换句话说,-pedantic选项能够帮助程序员发现一些不符合ANSISO C标准的代码,但不是全部,事实上只有ANSIISo C语言标准中要求进行编译器诊断的那些情况,才有可能被GCC发现并提出警告。
具体代码如下
gcc -pedantic illcode,c -oi llcode
还有一些- W开头的检错命令
gcc -wall illcode.c -o illcode
gcc -werror test.c -o test
这些命令可以让gcc产生更多的警告信息
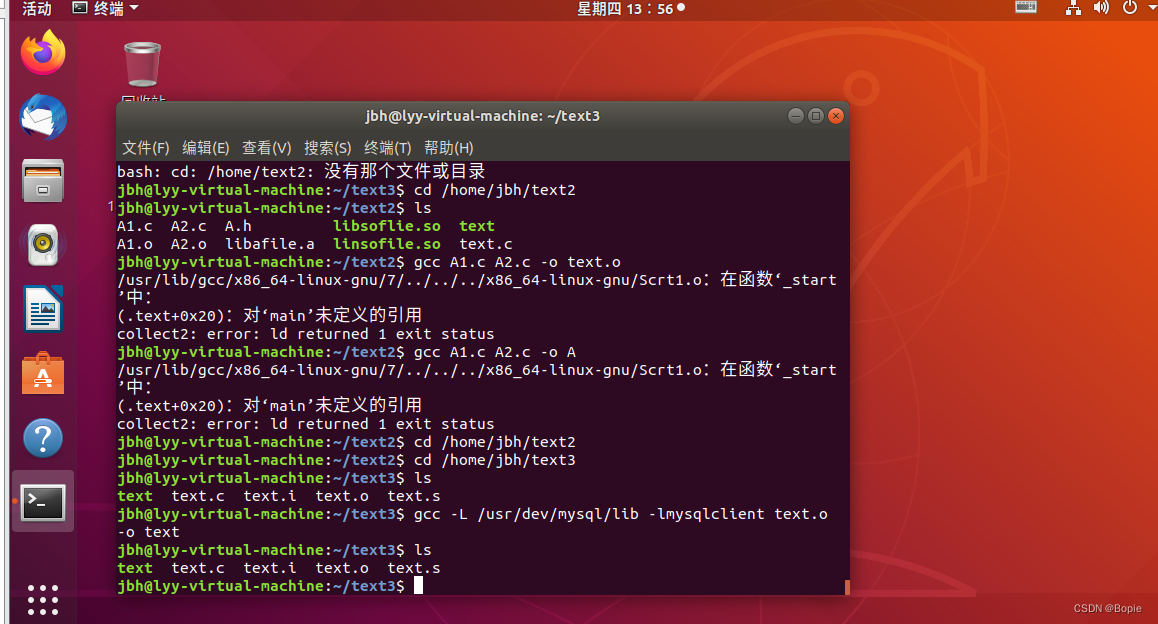
2.7库文件连接
开发软件时,我们通常需要许多的库函数,而在Linux下,这些库函数的目录通常不统一。我们需要自己想办法查找这些库函数。具体步骤如下
1.编译成可执行文件
代码如图
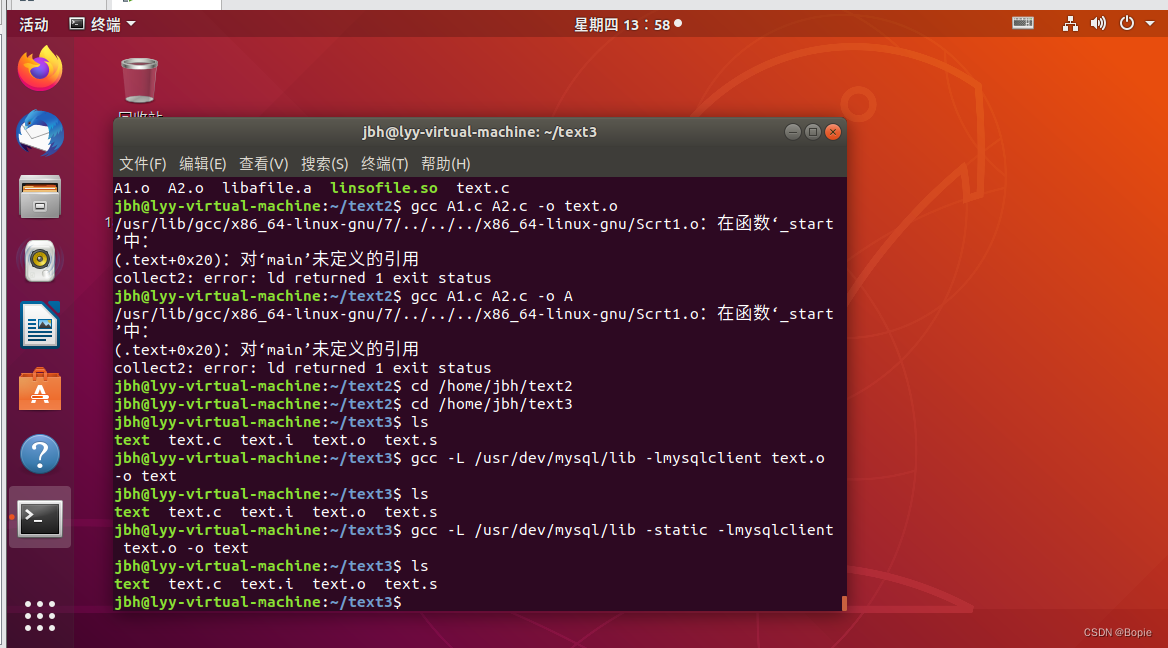
2.链接
代码如图
总结
以上内容就是有关gcc编译过程的完整环节,从中我们不难看到代码的工作时一个严谨而又层次分明的过程。这次学习遇到的问题很多,当大多属于小而杂的类型,所以还是比较顺利的。















 902
902










 暂无认证
暂无认证










 到【灌水乐园】发言
到【灌水乐园】发言










CSDN-Ada助手: 恭喜作者第15篇博客的发布!虽然标题是“【无标题】”,但内容肯定是精彩的。希望作者能够继续保持创作的热情和勤奋,不断提升自己的写作技巧和表达能力。建议下一步可以尝试给博客起一个富有吸引力的标题,让读者在第一眼就被吸引过来。期待作者更加出色的作品!加油!
Cstupidme: 请问选择引脚时空白是怎么回事?
linlh11: 前面已经算过了,一次定时中断的时间是0.005秒,所以200次中断的时间是0.005*200=0.5秒。这句话中计算有错误,怎么能算出来是0.5秒呢,应该是0.005*200=1秒才正确。