Pytorch-基于RNN的不同语种人名生成模型

 最新推荐文章于 2024-05-23 07:42:40 发布
最新推荐文章于 2024-05-23 07:42:40 发布
 阅读量499
阅读量499
 收藏
3
收藏
3


 点赞数
1
点赞数
1

一、RNN背景介绍
循环神经网络(Recurrent Neural Networks, RNN) 是一种常用的神经网络结构,它源自于1982年由Saratha Sathasivam提出的霍普菲尔德网络。 其特有的循环概念及其最重要的结构——长短时记忆网络——使得它在处理和预测序列数据的问题上有着良好的表现。
RNN是一种特殊的神经网络结构,它是根据"人的认知是基于过往的经验和记忆"这一观点提出的。它与DNN,CNN不同的是: 它不仅考虑前一时刻的输入,而且赋予了网络对前面的内容的一种'记忆'功能
【循环神经网络】5分钟搞懂RNN,3D动画深入浅出
RNN的特点有以下几点:
- RNN是一种递归神经网络,它可以处理序列数据,如时间序列、文本等。
- RNN具有记忆功能,可以记住前面的信息,从而更好地处理序列数据。
- RNN的结构相对复杂,包括输入层、隐藏层和输出层。
- RNN的训练相对于其他神经网络来说比较困难。
RNN的缺点主要有以下几点:-RNN的训练相对于其他神经网络来说比较困难,因为它们容易出现梯度消失或梯度爆炸的问题(梯度反向传播中的连乘效应导致的)。
- RNN的结构相对复杂,包括输入层、隐藏层和输出层,这使得它们在处理大规模数据时容易出现过拟合的问题。
- RNN的时间序列预测精度不高,这是因为RNN对于长期依赖关系的建模效果不佳(RNN适合捕捉到短时间片依赖,但训练长了之后一些重要信息会被后续输入给覆盖。)。
1、典型的RNN结构如下图所示
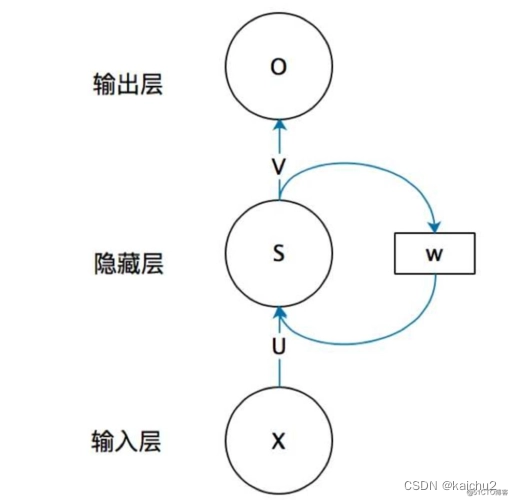
一个典型的RNN结构包含一个输入x,一个输出O和一个神经网络单元S,同时RNN的S不仅与输入和输出存在联系,其与自身也存在一个回路W,这就表示上一时刻的信息会作用给下一时刻;
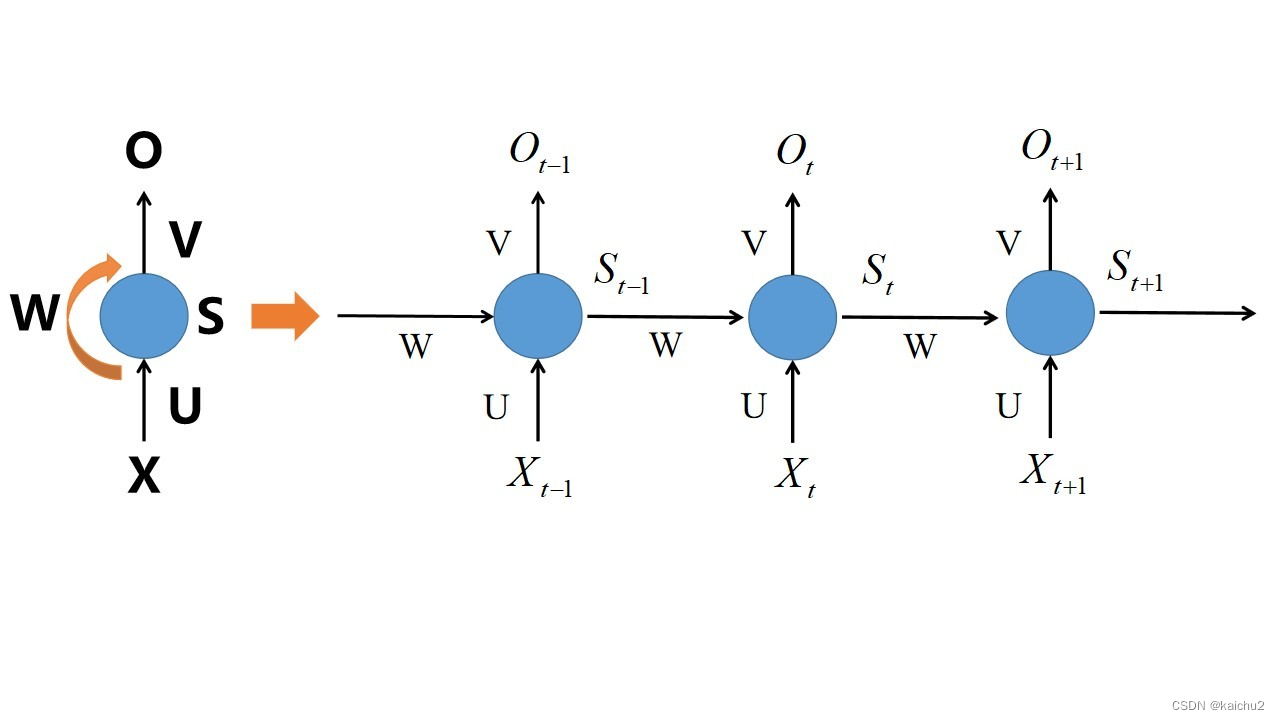
2、计算过程如下图所示
计算过程:其中U、V表示参数矩阵,bias表示偏置项参数,f对应的是激活函数,经典的RNN中经常采用tanh作为激活函数。同时在计算每一步时U,W,V,bias都是一样的,即参数共享。隐藏状态计算结果为:S,输出状态计算结果为:O,c对应的是新的参数,然后采用softmax函数将输出转换成各个类别的概率(类别最大的那个为模型的预测),同时当前的输入和输出的序列必须是等长的。
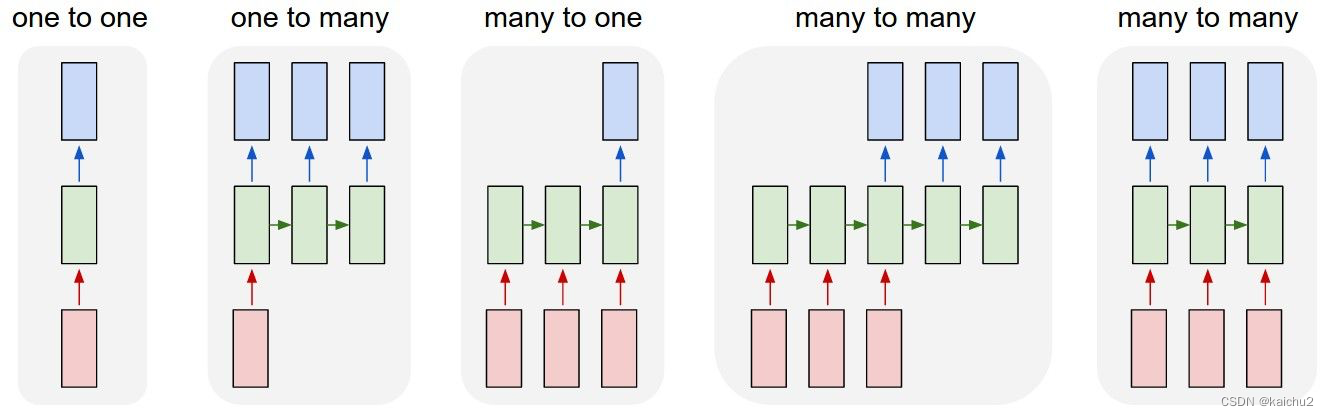
RNN的结构类型有N对N结构、One to one、One to many、Many to one、Many to many等。其中,N对N结构是最常见的一种,它的输入输出序列是等长的。而其他类型的RNN则是在N对N结构的基础上进行改进,以解决N对N结构中存在的一些问题,例如长距离依赖问题等。
下面是每种结构的详细介绍:
- N对N结构:输入输出序列相等,可以用于信息抽取中的命名实体识别,或者对视频的每一帧的分类标签进行分类等。
- One to one结构:每个元素只能和一个元素相邻,可以用于文本自动纠错等。
- One to many结构:每个元素可以和多个元素相邻,可以用于语音识别等。
- Many to one结构:每个元素只能和一个元素相邻,可以用于文本自动纠错等。
- Many to many结构:每个元素可以和多个元素相邻,可以用于图像识别等。
RNN如何应用于图像分类?
RNN的结构非常适合处理序列化的数据,而图像分类任务也有着序列化的特征,例如像素排列等。它可以以序列的形式处理图像,记录像素之间的关系,用于提取图像的特征,最终用于图像分类。
在图像分类中,通常会将图像转换为一个固定大小的矩阵,然后将其作为输入传递给RNN。RNN会在每个时间步上提取特征,并将其传递到下一个时间步。最终,RNN的输出将被用于分类。大家可以参考下transformer
针对RNN问题的改进有很多,其中一些主要的改进包括:这里就暂时不过多解释。
- 长短时记忆网络(LSTM):LSTM是一种特殊的RNN,它通过引入门控机制来解决梯度消失和梯度爆炸问题,从而改进了RNN的性能。
- GRU:GRU是另一种特殊的RNN,它也是通过引入门控机制来解决梯度消失和梯度爆炸问题,从而提高了RNN的性能。
- 双向循环神经网络(Bi-RNN):双向RNN可以同时处理序列中的顺序和逆序信息,从而提高了RNN的性能。
- 卷积神经网络(CNN):CNN可以自动提取图像中的特征,并将其转换为向量形式,然后使用RNN进行处理。这种方法可以充分利用图像中的信息,并提高RNN的性能。
二、任务介绍
当前数据集含有18个txt文本,每个文本代表一种语言,文本中的内容表示该语言下常见的一些名字,按照这种格式也可以自己构建一些数据集,本次任务主要是通过给定一种语言和首字母,生成该语言下的以首字母为开头的文字:
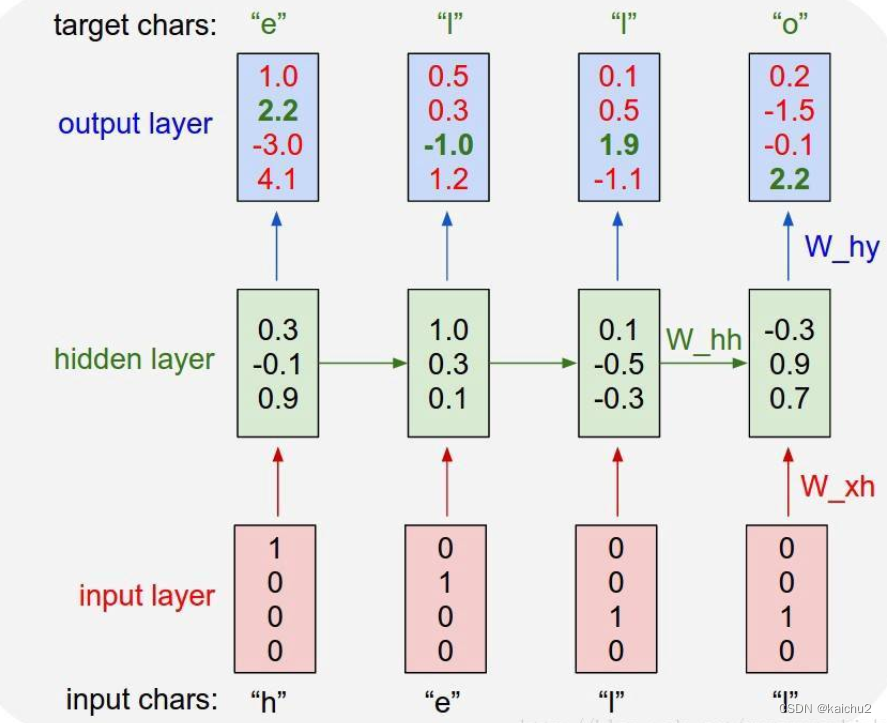
下面构建字符级RNN来进行文本生成,字符级RNN训练是指将单词作为一系列字符读取,在每一步输出预测和“隐藏状态”,将其先前的隐藏状态输入至下一时刻,每一个时刻都会输出一个字母,最终把所有的字母拼在一起就得到最终的结果。
简单来说就是给定某个语种的训练样本,RNN从中学到该语言的特性,当给定一个首字符时,最大可能生成符合这种语言特性的名字。
1、RNN字符级训练具体过程
对于每个语种,将当前字母作为输入,下一个字母作为目标,遍历该单词的所有字母,从而学习到该单词的特性,再遍历该语种下的所有单词就可以学习到该语言的特性。输入和输出是等长的:如当前的输入序列是{"h","e","l","l"},输出序列是{“e”,"l","l","o"},同时会在单词的末端增加一个!表示结束的标志,可以在训练的过程中告诉我们什么时候停止。
三、数据模块构建
这段代码的功能是读取一个文件夹中的所有文本文件,将每个文件中的Unicode编码转换成ASCII编码,并将每个文件的内容保存为一个列表。然后,将这些列表存储在一个字典中,其中每个键对应一个类别,每个值对应一个语种的语料。最后,输出总类别数和所有类别的名称。
from __future__ import unicode_literals,print_function,division
from io import open
import glob
import os
import unicodedata
import string
import torch
# 用于过滤掉unciode字符串中不属于英文字符的字符
all_letters = string.ascii_letters+".,;'-"
def findFiles(path):
return glob.glob(path)
findFiles("E:\Pytorch_21\\02_CIFAR10\data\hymenoptera_data\\train")
# 将Unicode编码转换成ASCII编码
def unicodeToAscii(s):
# 'Mn'表示非间距组合记号
return ''.join(c for c in unicodedata.normalize('NFD',s) if unicodedata.category(c) != 'Mn' and c in all_letters)
# 读取文件并分成几行
def readLines(filename):
lines = open(filename,encoding="utf-8").read().strip().split("\n")
return [unicodeToAscii(line) for line in lines]
# 构建category_lines字典,列表中的每行是一个类别
category_lines = {}
all_categories = []
for filename in findFiles("./data/names/*.txt"):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
# 保存成字典:key对应类别,value对应的语种的语料
category_lines[category] = lines
n_categories = len(all_categories)
print(n_categories) # 语种数量
if n_categories == 0:
raise RuntimeError("Please download your data!")
print(f"Total categories:{n_categories}:{all_categories}")
输出:
18
Total categories:18:['Arabic', 'Chinese', 'Czech', 'Dutch', 'English', 'French', 'German', 'Greek', 'Irish', 'Italian', 'Japanese', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Scottish', 'Spanish', 'Vietnamese']注意:
因为不同语种的名字存在不同,需要统一转换成ASCII编码,才能方便统一进行模型训练。
One-hot编码:
是一种将分类变量转换为机器学习算法易于处理的数值型变量的方法。在one-hot编码中,每个分类变量都被表示为一个二进制向量,其中只有一个元素为1,其余元素为0。例如,对于三个类别A、B和C,如果某个样本属于类别A,则将其表示为[1,0,0];如果属于类别B,则表示为[0,1,0];如果属于类别C,则表示为[0,0,1]。
在自然语言处理中,one-hot编码通常用于将单词转换为数字序列,以便输入到神经网络模型中进行训练和预测。例如,假设有一个包含五个单词的句子"cat dog bird fish",其中"bird"出现了一次,"fish"出现了两次,其他单词只出现了一次。使用one-hot编码后,可以将其表示为以下数字序列:
[1,0,0,0,1,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1]
其中,第一个元素代表单词"cat",第二个元素代表单词"dog",第三个元素代表单词"bird",以此类推。这样,机器学习算法就可以通过这些数字序列来识别文本中的不同单词了。
当前模块为构建一个训练集,其中包含随机抽取的语言和名字。具体来说,它实现了以下功能:
1. 定义了一个函数randomChoice(l),用于从列表l中随机选择一个元素并返回。
2. 定义了一个函数randomTrainingPair(),用于随机抽取一个语言和一个名字,并将它们作为元组返回。
3. 定义了一个函数categoryTensor(category),用于将输入的类别转换成one-hot张量。
4. 定义了一个函数inputTensor(line),用于将输入的名字转换成one-hot张量。
5. 定义了一个函数targetTensor(line),用于将输入的名字转换成目标张量。
6. 定义了一个函数randomTrainingExample(),用于随机生成一个训练样本,包括类别、名字、类别张量、输入张量和目标张量。
7. 最后,通过调用randomTrainingPair()函数随机选择类别和名字,然后使用上述函数构建训练集。
import random
# 列表中的随机项
def randomChoice(l):
return l[random.randint(0,len(l)-1)]
def randomTrainingPair():
# 随机抽取语言
category = randomChoice(all_categories)
# 对语言随机抽取名字
line = randomChoice(category_lines[category])
#print(f"{category}:{line}")
return category,line
# 类别的one-hot张量
def categoryTensor(category):
# 获得语种列表中对应语种的索引值
index = all_categories.index(category)
# 构造one-hot张量:除了对应语种的值为1,其余都为0
tensor = torch.zeros(1,n_categories)
tensor[0][index] = 1
return tensor
# 构造成对数据:(A,B)(B,C)(C,D)(D,<EOS>)
# 用于输入的从头到尾字母(不包含EOS)的one-hot张量
n_letters = len(all_letters)+1 # 添加EOS结束位
def inputTensor(line):
# 第二维度代表逐个字母输入
tensor = torch.zeros(len(line),1,n_letters) # n_letters:58
# 对该单词line的每个字母遍历转换成one-hot张量
for li in range(len(line)):
letter = line[li]
tensor[li][0][all_letters.find(letter)] = 1
return tensor
# 用于生成目标张量
def targetTensor(line):
# 从第二个字母开始
letter_indexes = [all_letters.find(line[li]) for li in range(1,len(line))]
letter_indexes.append(n_letters-1) # 添加EOS结束位
return torch.LongTensor(letter_indexes)
# 构建训练集
def randomTrainingExample():
category,line = randomTrainingPair()
category_tensor = categoryTensor(category)
input_line_tensor = inputTensor(line)
target_line_tensor = targetTensor(line)
return category_tensor,input_line_tensor,target_line_tensor
category_tensor,input_line_tensor,target_line_tensor = randomTrainingExample()
#选择类别和对应的语料
category,line = randomTrainingPair()
# 将类别转成one-hot
cate_tensor = categoryTensor(category)
# 将输入数据转成one-hot
input_tensor = inputTensor(line)
print(input_tensor[0])
# 标签转换
target = targetTensor(line)
print(target.shape)四、RNN模型构建
这里模型的输入包括语言信息和输入的单词信息,先定义好隐藏状态,为模型学习该单词字母之间的特性,进而学习到对应语言的特性。
| i2h | 输入维度:n_categories+input_size+hidden_size,分别语言、输入、隐藏状态,输出维度为hidden_size用于更新当前的隐藏状态 |
| i2o | 由于每一步输入都是一个字母,但是模型实际接收的数据有语言、输入、隐藏状态,所有需要一个线性层将其转换为字母信息,这就是该模块的定义,输入和i2h保持一致,输出output_size和input_size相等,都表示字母的维度 |
| o2o | 利用隐藏状态和字母信息预测下一个字母:输入维度为hidden_size+output_size |
具体来说,该模型包含以下部分:
- 初始化函数
__init__():定义了模型的三层核心结构,包括输入层、隐藏层和输出层之间的线性变换,以及一个dropout层和一个softmax层,用于对输出进行归一化和防止过拟合。 - 前向传播函数
forward():将输入的字母、单词和隐藏状态合并起来,依次通过三层线性变换得到最终的隐藏状态和输出结果,并将它们合并后通过另一个线性变换得到最终的输出结果。 - 随机初始化隐藏状态函数
initHidden():返回一个大小为(1,hidden_size)的全零张量,作为RNN模型的初始隐藏状态。
# 构建模型
import torch
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size,output_size):
super(RNN,self).__init__()
self.hidden_size = hidden_size
# 三层核心结构
self.i2h = nn.Linear(n_categories+input_size+hidden_size, hidden_size)
self.i2o = nn.Linear(n_categories+input_size+hidden_size, output_size)
self.o2o = nn.Linear(hidden_size+output_size,output_size)
# 防止过拟合,softmax对输出归一化
self.dropout = nn.Dropout(0.1)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self,category,input,hidden):
# 合并所有输入
input_combined = torch.cat((category,input,hidden),1)
# 得到隐藏层
hidden = self.i2h(input_combined)
# 得到当前隐藏的字母信息
output = self.i2o(input_combined)
# 合并
output_combined = torch.cat((hidden,output),1)
output = self.o2o(output_combined)
output = self.dropout(output)
output = self.softmax(output)
return output,hidden
# 随机初始化h0
def initHidden(self):
return torch.zeros(1,self.hidden_size)
# 调用RNN模型
rnn = RNN(n_letters,128,n_letters)
print(rnn)输出:
RNN(
(i2h): Linear(in_features=204, out_features=128, bias=True)
(i2o): Linear(in_features=204, out_features=58, bias=True)
(o2o): Linear(in_features=186, out_features=58, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(softmax): LogSoftmax(dim=1)
)在PyTorch中,您可以使用torch.nn.RNN类来调用现有的RNN模块。该类接受以下参数:
- input_size:输入数据的特征维度。
- hidden_size:隐藏状态的维度。
- num_layers:RNN层数。
- batch_first:如果为True,则输入和输出张量的形状为(batch_size, seq, feature),否则为(seq, batch_size, feature)。例如,如果您想创建一个具有100个隐藏单元的RNN层,可以使用以下代码:
import torch.nn as nn
rnn = nn.RNN(input_size=100, hidden_size=100, num_layers=1)五、模型训练
这段代码是一个训练循环神经网络(RNN)模型的示例。并定义了一个train()函数来执行模型的训练过程。
在train()函数中,首先初始化了隐藏状态和损失变量。然后,对于输入序列中的每个单词,将该单词作为输入传递给RNN模型,并计算输出和损失。接下来,使用反向传播算法更新模型参数,并返回平均损失和准确率。在主程序中,创建了一个RNN模型实例,并指定了一些超参数,如学习率、迭代次数等。然后,在一个循环中调用train()函数进行训练,并在每500次迭代后打印一次损失值和准确率。最后,保存训练好的模型到文件中。
# 训练模型
import time
import math
import os
criterion = nn.NLLLoss()
learning_rate = 0.0005
def train(category_tensor,input_line_tensor,target_line_tensor):
# 在target最后添加一维
target_line_tensor.unsqueeze_(-1)
# 初始化隐藏状态
hidden = rnn.initHidden()
# 每输入一个单词,清理一次梯度累积
rnn.zero_grad()
loss = 0
# 遍历该单词的所有字母
for i in range(input_line_tensor.size(0)):
# 返回hidden用于循环的下一步骤
output,hidden = rnn(category_tensor,input_line_tensor[i],hidden)
l = criterion(output,target_line_tensor[i])
loss += l
loss.backward()
# 更新参数,这里实际上是SGD,和优化器同等作用,也可用optim.SGD
for p in rnn.parameters():
p.data.add_(-learning_rate,p.grad.data)
return output,loss.item() / input_line_tensor.size(0)
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s/60)
s -= m * 60
return f'%dm %ds' %(m,s)
rnn = RNN(n_letters,128,n_letters)
n_iters = 100000
print_every = 5000
plot_every = 500
all_losses = []
# 每500次保留平均损失loss值后重置为0
total_loss = 0
start = time.time()
for iter in range(1,n_iters+1):
output,loss = train(*randomTrainingExample())
total_loss += loss
if iter % print_every == 0:
print("%s (%d %d%%) %.4f" %(timeSince(start),iter,iter/n_iters*100,loss))
if iter % plot_every == 0:
all_losses.append(total_loss / plot_every)
total_loss = 0
model_dir = "./model"
if not os.path.exists(model_dir):
os.makedirs(model_dir)
# 保存模型
torch.save(rnn,"./model/model.pth")
# 绘制训练曲线
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
plt.figure()
plt.plot(all_losses)输出:
0m 9s (5000 5%) 3.2124
0m 18s (10000 10%) 2.3770
0m 27s (15000 15%) 2.8693
0m 36s (20000 20%) 2.5755
0m 45s (25000 25%) 2.6050
0m 54s (30000 30%) 2.3611
1m 3s (35000 35%) 1.7341
1m 12s (40000 40%) 1.3765
1m 21s (45000 45%) 1.5147
1m 30s (50000 50%) 1.8335
1m 39s (55000 55%) 2.7708
1m 48s (60000 60%) 2.3944
1m 57s (65000 65%) 1.9899
2m 6s (70000 70%) 2.1605
2m 15s (75000 75%) 2.4654
2m 24s (80000 80%) 2.4188
2m 33s (85000 85%) 1.9665
2m 42s (90000 90%) 3.1462
2m 51s (95000 95%) 2.1656
3m 0s (100000 100%) 2.0037 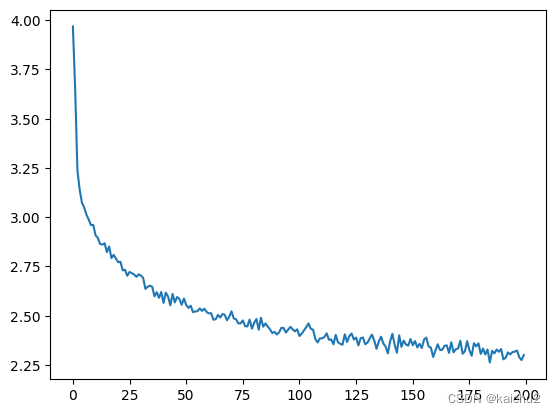
六、模型推理
# 测试
max_length = 20
# 来自类别和首字母的样本
def sample(category,start_letter="A"):
with torch.no_grad():
category_tensor = categoryTensor(category)
input = inputTensor(start_letter)
hidden = rnn.initHidden()
output_name = start_letter
for i in range(max_length):
output,hidden = rnn(category_tensor,input[0],hidden)
# top函数用来提取最大概率的值和索引,也可以用torch.max函数
# topv,topi = output.topk(1)
# topi = topi[0][0]
_,pred = torch.max(output.data,dim=1)
topi = pred
# 如果预测为EOS的索引,则跳出循环
if topi == n_letters -1:
break
else:
letter = all_letters[topi]
output_name += letter
# 当前预测的字母作为下一个时刻的输入
input = inputTensor(letter)
return output_name
# 从一个类别和多个首字母中获取多个样本
def samples(category,start_letters='ABC'):
for start_letter in start_letters:
print(sample(category,start_letter))
samples("Russian","CJE")
print("*"*10)
samples("Chinese","LCW")输出:
Charavev
Jarovov
Eakovov
**********
Lan
Chan
Wan参考链接: 史上最详细循环神经网络讲解(RNN/LSTM/GRU)















 916
916










 企业员工
企业员工








































 到【灌水乐园】发言
到【灌水乐园】发言












m0_64190807: 博主大大,求个数据集,非常非常感谢! 862714691@qq.com
kaichu2: 不好意思,fastfold没有用过
iiimZoey: 请问有fastfold的运行指南吗
本周也不服输的朱朱: 我想请问一下如果我想从一个被噪声污染的图片生成一个比较精细的未被污染的图片的话,增加采样的步数会有效果嘛?
kaichu2: 文中的例子图片本身就很模糊,而且举例的模型很简单