cs61b-sp21笔记

 最新推荐文章于 2024-04-25 23:22:54 发布
最新推荐文章于 2024-04-25 23:22:54 发布
 阅读量1.5k
阅读量1.5k
 收藏
13
收藏
13


 点赞数
7
点赞数
7

Week01
Reading 1.1 Hello World
Reading 1.2 Defining and Using Classes
1.1 课程总结
介绍课程+基本的java语法,如果java零基础,可先阅读 A Java Crash Course(optional)
1.2 课后实践
1.2.1 注册gradescope且加入sp21的课程
gradescope网址:https://www.gradescope.com/
sp21课程代码:MB7ZPY
注意:作业只需修改文件中的代码,确保提交文件目录框架不变,否则评测系统识别不到文件。
1.2.2 使用Git管理代码
主要是需要将skeleton中的代码拷贝到本地,同时再将本地仓库与远程自己的仓库连接。
我是直接通过idea来使用git,里面都是可视化操作。具体步骤如下:
- 首先下载 Git
- 在idea中将Git程序路径加入
- 在github中
Fork即克隆一个 skeleton,名字换成自己的。比如cs61b-sp21 - 通过idea中的git来
pull刚刚创建的远程仓库。
1.2.3 完成 Lab1中的Collatz.java
1.2.4 完成 Project0中的Model.java
2048小游戏的三条规则如下:
- 两个相同数字的瓷砖合并,会产生一个双倍数字的瓷砖
- 一个瓷砖每次移动只能合并一次
- 三个相同方向的相同数字的瓷砖合并时,合并该方向的前两个瓷砖
在 Google Form quiz中检测自己是否理解了规则。
游戏中的Board,下标从左往右递增,从下往上递增,具体需要实现Model.java中的如下方法:
emptySpaceExists:如果面板上有一个瓷砖是null,返回true
使用Board中的title方法和size方法遍历每个瓷砖,如果有一个为null则返回true,用TestEmptySpace.java来调试,全部8个通过说明没问题。
maxTileExists:如果有任何一个瓷砖值为MAX_PIECE(2048),返回true
注:尽量使用Model中定义的常量MAX_PIECE,方便以后修改。
atLeastOneMoveExists:存在至少一个有效移动,返回true
有效移动是指操作面板的四个方向,有一个方向可以使至少一个瓷砖移动。有效移动可以分为以下两种情况:
- 存在至少一个空格
- 相邻两块瓷砖有相同数字
tilt:实现面板的倾斜(Hard)
除了要完成面板状态的更新,还需要改变以下两个状态:
score变量需要改变,例如,两个4合并成8,score需要加8- 设置一个
changed局部变量,如果面板状态改变了,则需要设为true,用来告诉其它方法,例如setChanged(),面板状态已经改变了使用
Borad中的move方法来实现瓷砖的移动。先考虑向上移动,顶行方块不需要移动,倒数第二行方块向上移动有两种情况:1)上面没有方块。2)上面方块数字相同,可以合并。
Week02
Reading 3.1 Testing and Selection Sort
Reading 2.1 Lists
Reading 2.2 SLLists
2.1 课程总结
2.1.1 Testing and Selection Sort
如何编写测试程序,以及要如何使用JUnit来简化测试流程。介绍选择排序,将其拆分成三个helper function,并编写和测试了它们。
2.1.2 Lists
希望可以实现一个大小可变动的列表。
- 先介绍了简化版的计算机存储机制,以及java中的类如何表示和存储,了解到老师的Golden Rule of Equals,也就是java中的按值传递
- 编写了裸板
IntList,里面包含了get(),size()方法
2.1.3 SLLists
因为裸板IntList对用户操作不友好,引入了SLList来进行包装。
- 编写
addFirst()和addLast()方法 - 引入了
private和Nested(内部)类的概念 - 编写和优化了
size()方法 - 通过完善
addLast()方法,引入了sentinel节点
2.2 课后实践
2.2.1 完成 Lab 2 Setup
- 下载课程需要的 javalib
- 将javalib复制到本地目录的
.library-sp21中 - 按照Lab 2 Setup中的步骤配置即可

注意: 如果是在项目下进行配置,以后每个项目都需要进行配置。
2.2.2 完成 Lab 2
2.2.2.1 使用debugger来调试代码
前置知识:
- Debbuger的重要性和科学性,以及对比使用
print来调试的优势。 Breakpoints,Step Into,Step OverandStep Out的功能。
任务:修复DebugExercise2中的两个bug,以及编写新的正确的函数来替代bug函数,不能step into到max和add函数中。
2.2.2.2 JUnit
了解JUnit,使用其调试ArithmeticTest.java中的代码,并修复bug
2.2.2.3 IntLists
修复IntListsExercises.java中的三个方法的bug,介绍了of()和toString()函数来简化测试。三个方法分别是:
addConstant:给列表中每个元素加一个常量值
setToZeroIfMaxFEL:以该节点作为作为开头时,List中最大值的首位位数相同,就将该节点值设为0。其中涉及到一个单行多函数的step into问题,将其改成多行更容易调试。
squarePrimes:将List中的质数平方,如果至少有一个质数,返回true,否则返回false。任务是在SquarePrimesTest.java中编写JUnit测试函数,找到bug并修复。其中的Prime.isPrime()函数可以确定正确,调试时可以over step。
Week03
3.1 课程总结1
Reading 2.3 DLLists
Reading 2.4 Arrays
3.1.1 DLLists
addLast()方法需要遍历所有的节点,考虑添加last节点,指向列表的末尾。
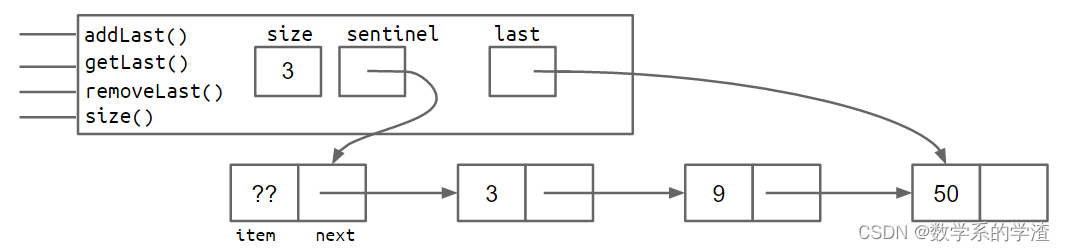
addLast和getLast方法会变快,但removeLast方法会变慢,因为当删除最后一个节点时,很难找到倒数第二个节点来更新last节点。很自然可以想到每个节点增加一个前向指针。

还有一个问题需要解决,last节点有可能指向哨兵节点,也有可能指向真实的节点,在代码实现时需要增加额外的判断条件,比如removeLast需要判断是否指向哨兵节点,这会使代码不够美观。代码的具体实现将在Project 1中,下面提供两种解决思路:
- 在末尾增加一个哨兵节点

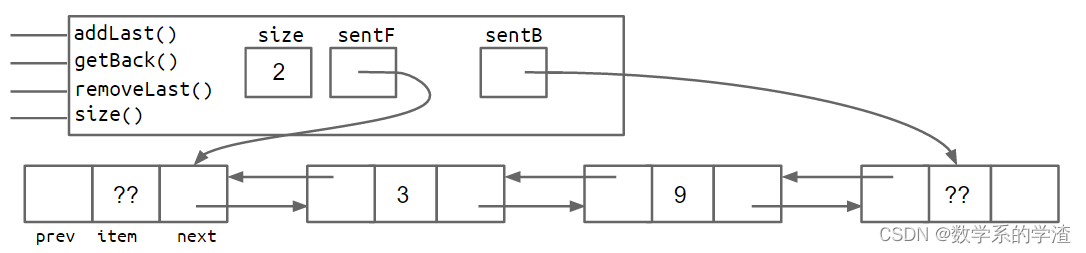
- 使用循环结构,
first和last共用一个哨兵节点
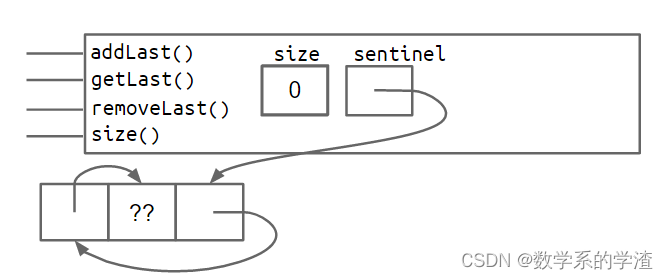

下面还介绍了Java中的泛型(省略)
3.1.2 Arrays(省略)
介绍Java中的一维和多维数组,包括存储、声明和使用,并对比了数组和类之间的区别。数组和类之间的不同带来的主要影响是,数组可以在程序运行期间通过[]指定需要访问的地址,而类不可以。
3.2 课程总结2
Reading 2.5 ALists
3.2.1 AList
由于基于链表的List在实现get(int i)方法需要
O
(
n
)
O(n)
O(n)的时间复杂度,下面实现基于数组的List,实现addLast, getLast, get, size, removeLast,涉及两方面的优化:
- 时间优化:关于
addLast超出数组大小后,进行倍数扩容(Geometric Resizing)。 - 空间优化:当数组空间利用率很低时,需要调整数组大小;在
removeLast方法中,AList被设置为泛型后,不仅仅将size - 1,还需要将items[size - 1]置为null,避免对象“游荡”(loitering)。
3.3 课程总结3
Reading 4.1 Interface
介绍接口、接口的继承(what)、实现继承(how)
关于Animal X = new Dog()中的X方法调用规则,分成两步:

- 静态类型(编译时期):在声明时指定的类型。确定我们需要调用方法的名字。
- 动态类型(运行时期):在实例化时指定的类型,等于指向对象的类型。调用动态类型中有该名字的方法,可能使用
Dog**重写(override)**过的方法。
3.4 完成 Lab3
坑:此项目之后需要jdk14之后的版本
3.4.1 Timing Tests
测试AList中的addLast方法和SLList中的getLast方法所需时间。分别在TimeAList和TimeSLList中编写代码,结果打印为如下图:

N表示list中元素个数;time为总时间;ops为调用次数;microsec/op为平均每次调用时间,此结果已经自动计算好了。计算时间需要用到Stopwatch类,可以在stopwatchDemo看到使用实例,之后将结果作为参数放入此方法中即可printTimingTable(AList<Integer> Ns, AList<Double> times, AList<Integer> opCounts)。
3.4.2 Randomized Comparison Tests
在BuggyAList和AListNoResizing之间进行对比测试,通过随机调用两个类之间不同的方法,同样的参数,对比它们的返回结果是否相同来判断所编写类是否有漏洞,最后在BuggyAList中找到bug。期间用到的调试工具有:resume button,condition to a breakpoint,execution breakpoint。
3.5 完成部分 Project 1 Data Structures
3.5.1 Linked List Deque
链表结构的Deque,在LinkedListDeque中编写实现Deque接口,具体API要求可在链接中查找,在LinkedListDequeTest提供其函数的测试。
3.5.2 Array Deque
CHEAT
通过循环队列实现Deque(双端队列)。同时在LinkedListDequeTest中仿造lab3中编写对比测试和其它测试(可选)。
3.5.3 Extra Credit: Checkpoint(可选)
额外任务,编写测试。
Week04
4.1 课程总结
4.1.1 继承、强制转换、高阶函数
Reading 4.2 Extends, Casting, Higher Order Functions
继承和强制转换(略),其中继承会破坏封装性,在Reading 4.2中有举例说明。高阶函数是将其他函数视为数据的函数,Java7及更早版本中,不像python支持将函数作为函数的参数,这意味着我们不能编写具有“Function”类型的函数,因为函数根本没有类型。通过如下方式实现高阶函数:
public interface IntUnaryFunction {
int apply(int x);
}
public class TenX implements IntUnaryFunction {
/* Returns ten times the argument. */
public int apply(int x) {
return 10 * x;
}
}
public static int do_twice(IntUnaryFunction f, int x) {
return f.apply(f.apply(x));
}
4.1.2 子类多态、类的比较
Reading 4.3 Subtype Polymorphism vs. HoFs
介绍了Java的多态性,编译时看静态类型,运行时看动态类型。又介绍了通过Java中已经提供的接口,实现Comparable接口或者实例化Comparator接口来实现类之间的比较。Comparable只有compareTo()方法可以重写,如果一个类想要多个对比方法,则需要借助Comparator接口。
import java.util.Comparator;
public class Dog implements Comparable<Dog> {
...
public int compareTo(Dog uddaDog) {
return this.size - uddaDog.size;
}
private static class NameComparator implements Comparator<Dog> {
public int compare(Dog a, Dog b) {
return a.name.compareTo(b.name);
}
}
public static Comparator<Dog> getNameComparator() {
return new NameComparator();
}
}
4.1.3 异常、迭代器、Object类中的方法
Reading 6.1~6.4
在编写ArraySet类中介绍以上内容。其中抛出异常可省略,迭代器的构建使得ArraySet可以使用增强for循环来遍历的代码如下:
private class ArraySetIterator implements Iterator<T> {
private int wizPos;
public ArraySetIterator() {
wizPos = 0;
}
public boolean hasNext() {
return wizPos < size;
}
public T next() {
T returnItem = items[wizPos];
wizPos += 1;
return returnItem;
}
}
最后介绍重点介绍Object类中的toString()和equals()方法,代码如下:
public String toString() {
StringBuilder returnSB = new StringBuilder("{");
for (int i = 0; i < size - 1; i += 1) {
returnSB.append(items[i].toString());
returnSB.append(", ");
}
returnSB.append(items[size - 1]);
returnSB.append("}");
return returnSB.toString();
}
public boolean equals(Object other) {
if (this == other) {
return true;
}
if (other == null) {
return false;
}
if (other.getClass() != this.getClass()) {
return false;
}
ArraySet<T> o = (ArraySet<T>) other;
if (o.size() != this.size()) {
return false;
}
for (T item : this) {
if (!o.contains(item)) {
return false;
}
}
return true;
}
其中有关toString()和of()方法的更优实现在 bonus视频中。
至此,有关这门课的Java语法部分基本学完,接下来是数据结构和算法这门课的精华部分。
4.2 完成 Lab 4: Git and Debugging
4.2.1 Git(略)
4.2.2 Debugging
调试Flik.java中的bug,函数功能是比较两个整数是否相等,当超过128后,Integer地址发生变化,使用==判断不相等,改为用equals即可。
4.3 完成 Project 1 Data Structures
4.3.1 MaxArrayDeque
MaxArrayDeque除了有ArrayDeque中的所有方法,同时还有额外的两个方法和一个构造器,这里采用继承的方式编写,减少代码的冗余。同时编写了关于其的测试。
4.3.2 GuitarString
完成GuitarString类,按照里面的TODO实现方法即可。其中的tic()方法需要实现Karplus-Strong算法,算法步骤如下:
- 用-0.5到0.5之间的随机数填充数组
- 移除第一个数,在末尾添加一个新的值,该值是第一和第二个数的平均数乘以给定的衰退因子(0.996)
- 演奏第二步中移除的值,重复第二步

完成GuitarString类之后可以通过TestGuitarString去测试。最后运行TTFAF来享受听觉盛宴!
Week05
5.1 课程总结
5.1.1 命令行、Git
slides
主要介绍Git,将在之后的Project 2中实现Git。首先介绍Git,个人认为讲的不是很清楚,可参考 猴子都能懂的Git入门;课程深度分析了Git底层的实现逻辑,如何避免存储的冗余,使用Hash的方法来管理不同的版本;同时还介绍了在Java中实现Serializable来存储对象。
5.1.2 渐进分析Ⅰ
slides
通过介绍两个程序,都实现了判断数组中是否有相同值的功能,来引入算法实现效率的概念。用数学方式来计算程序中不同操作在给定N下的最少执行次数和最大执行次数。
for (int i = 0; i < A.length; i += 1) {
for (int j = i+1; j<A.length; j += 1) {
if (A[i] == A[j]) {
return true;
}
}
}
return false;
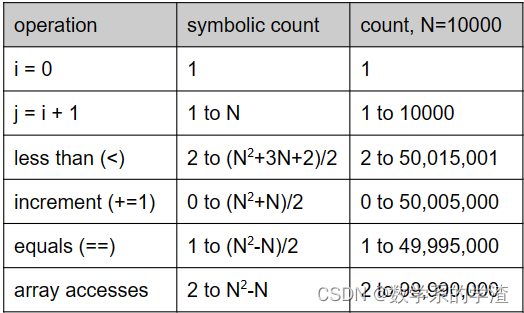
当N取极大值时,程序的运行时间取决于增长阶数(Order of growth)的运行时间,可以通过以下4步进行上表的简化:
- 只考虑最坏情况
- 选择一个代表性的操作(损失函数)
- 忽略低阶符号
- 忽略常数
然后就可以得到最坏情况下的增长阶数运行时间: N 2 N^2 N2。由于上表的计算过程过于复杂,可以适当简化分析过程,如下:
- 选择代表性的操作(损失函数)
- 计算其增长阶数
引入Big-Theta(
Θ
\Theta
Θ),
R
(
N
)
∈
Θ
(
f
(
N
)
)
R(N)\in\Theta(f(N))
R(N)∈Θ(f(N))指存在正数
k
1
,
k
2
,
N
0
k_1, k_2, N_0
k1,k2,N0,对于所有大于
N
0
N_0
N0的
N
N
N,满足以下条件:
k
1
f
(
N
)
≤
R
(
N
)
≤
k
2
f
(
N
)
k_1f(N)\le R(N)\le k_2f(N)
k1f(N)≤R(N)≤k2f(N)。简单来说就是表示同阶函数,之前的增长阶数都可以使用Big-Theta表示,例如:
N
3
+
3
N
4
∈
Θ
(
N
4
)
1
/
N
+
N
3
∈
Θ
(
N
3
)
1
/
N
+
5
∈
Θ
(
1
)
N
e
N
+
N
∈
Θ
(
N
e
N
)
40
s
i
n
(
N
)
+
4
N
2
∈
Θ
(
N
2
)
\begin{aligned} & N^3 + 3N^4 ∈ Θ(N^4) \\ & 1/N + N^3 ∈ Θ(N^3) \\ & 1/N + 5 ∈ Θ(1) \\ & Ne^N + N ∈ Θ(Ne^N) \\ & 40 sin(N) + 4N^2 ∈ Θ(N^2) \end{aligned}
N3+3N4∈Θ(N4)1/N+N3∈Θ(N3)1/N+5∈Θ(1)NeN+N∈Θ(NeN)40sin(N)+4N2∈Θ(N2)
引入Big-O(O),和Big-Theta类似,
O
(
f
(
N
)
)
O(f(N))
O(f(N))表示增长阶数小于等于
f
(
N
)
f(N)
f(N),即
R
(
N
)
≤
k
2
f
(
N
)
R(N)\le k_2f(N)
R(N)≤k2f(N)。
Week06
6.1 课程总结
6.1.1 Disjoint Sets(并查集)
slides
需要实现两个函数:connect()和isConnected(),思路历程如下:
-
不考虑每个值之间的单个连接,将连接的所有元素看成一个整体。

-
ListOfSetsDS:使用
List<Set<>>来存储,但是低效且复杂。 -
QuickFindDS:使用ids来标识每个元素所属集合,在查询是否连接时可以做到 Θ ( 1 ) \Theta(1) Θ(1)复杂度,但是更新连接复杂度较高。
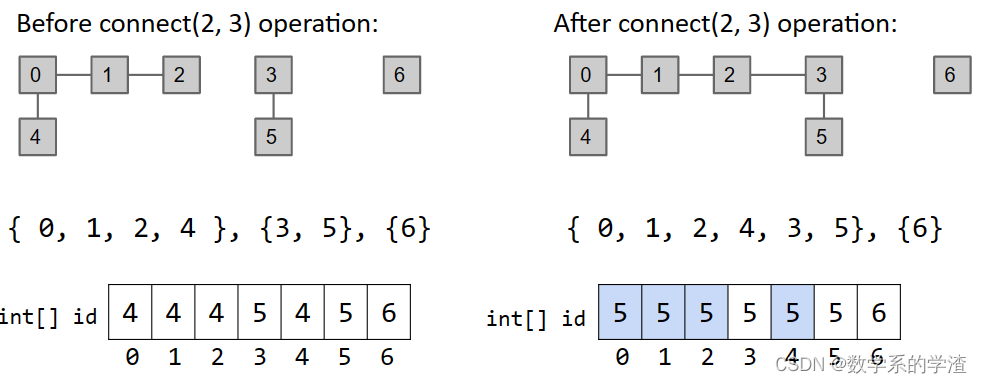
-
QuickUnionDS:使用树的结构来存储连接关系。
-
WeightedQuickUnionDS:跟踪每个set的大小,将size(集合包含的元素数量)小的树的根节点连接到大的树的根节点上,避免树过高而导致的查询根节点低效。使用size而不用height是因为,二者复杂度相同,但height实现难度更大。

-
WeightedQuickUnionWithPathCompressionDS:在上面的基础上使用路径压缩,在几乎不改变算法复杂度的情况下,提高下一次查找效率。
-
-
以上实现方法的时间复杂度如下:

6.1.2 Asymptotics Ⅱ
slides
关于算法复杂度的分析,需要跟着老师思路去一步步分析,介绍了5个例子,通过例子分析其算法的时间复杂度,例子为:
- 两个双重循环
- 基础的递归函数
- 二分查找
- 归并排序
6.1.3 ADTs, Sets, Maps, BSTs
Reading 10.2 Binary Search Trees
介绍 Abstract Data Type(抽象数据类型),Sets 和 Maps。(略)
重点介绍 Binary Search Trees(二分查找树 BST):
- 性质:对于二叉树的所有节点X
- X左边子树的所有元素都小于X
- X右边子树的所有元素都大于X
- 操作:
- 查找
static BST find(BST T, Key sk) { if (T == null) return null; if (sk.equals(T.key)) return T; else if (sk ≺ T.key) return find(T.left, sk); else return find(T.right, sk); } - 插入
static BST insert(BST T, Key ik) { if (T == null) return new BST(ik); if (ik ≺ T.key) T.left = insert(T.left, ik); else if (ik ≻ T.key) T.right = insert(T.right, ik); return T; } - 删除:对于删除的节点分三种情况
- 没有子节点,让父节点的指向
null - 有一个子节点,让父节点指向其子节点
- 有两个子节点,找左子树中最靠右的节点或者右子树中最靠左的节点,来替换该节点,因为该节点满足BST的性质,该方法称作Hibbard deletion
- 没有子节点,让父节点的指向
- 查找
可以使用BST来作为Set和Map的存储结构,对于其中的contains方法相比较使用ArraySet结构,如果二叉树平衡的话,可以将时间减少到只需要
l
o
g
(
n
)
log(n)
log(n)。
6.2 完成 Lab 6: Getting Started on Project 2
6.2.1 实验主要内容:
- 学会用命令行的形式来运行Java程序和测试
Capers - 在Java中操作文件和路径
- 序列化Java类来存储和读取
注意:下面6.2.2~6.2.6都是前置知识,虽然很多,但很重要。
6.2.2 Java的编译和运行(Windows在git bash中运行)
javac *.java
java capers.Main # java代码中包含“packge”的声明,返回包的最外层目录运行
6.2.3 Make的安装和使用
由于JUnit测试不适用接下来的lab和proj2,所以使用工具make来测试。
安装教程
安装完成后输入如下命令行来检查是否安装成功
make
make check [PYTHON=py] # 本电脑不使用 PYTHON=py 会报错
make clean # 清除所有的.class文件
6.2.4 当前路径、相对路径和绝对路径(略)
6.2.5 Java中的文件和目录操作
FIle(文件)
File f = new File("dummy.txt"); // 创建指向dummy.txt的指针
f.createNewFile(); // 创建文件
f.exists(); // 判断是否存在
Utils.writeContents(f, "Hello World"); // 使用Utils往文件中写入内容
Directories(路径)
File d = new File("dummy");
d.mkdir();
6.2.6 Serializable(序列化)
不使用Utils来读写Java对象
import java.io.Serializable;
public class Model implements Serializable {
...
}
Model m = ....;
File outFile = new File(saveFileName);
try {
ObjectOutputStream out =
new ObjectOutputStream(new FileOutputStream(outFile));
out.writeObject(m);
out.close();
} catch (IOException excp) {
...
}
Model m;
File inFile = new File(saveFileName);
try {
ObjectInputStream inp =
new ObjectInputStream(new FileInputStream(inFile));
m = (Model) inp.readObject();
inp.close();
} catch (IOException | ClassNotFoundException excp) {
...
m = null;
}
使用Utils来方便的读写Java对象
Model m;
File outFile = new File(saveFileName);
// Serializing the Model object
writeObject(outFile, m);
Model m;
File inFile = new File(saveFileName);
// Deserializing the Model object
m = readObject(inFile, Model.class);
6.2.7 完成 Canine Capers
以上都是完成Lab 6的前置知识,下面正式开始编写,按照Lab 6推荐的顺序实现就可以轻松完成,需要实现的命令有三个:
story [text]:将 text + 换行 添加到story.txt文件中,需要保留先前的文本。dog [name] [breed] [age]:持久化(储存)创建的Dog,同时输出其toString()方法,假设狗的名字是唯一的。birthday [name]:实现Dog年龄的持久化,打印庆祝生日信息。
Week07
7.1 课程总结
7.1.1 B-Trees(2-3, 2-3-4 Trees)
slides
了解正常的BST的一些缺陷,例如当以某些顺序插入时,BST会变得很稀疏,这会导致BST的性能变差。
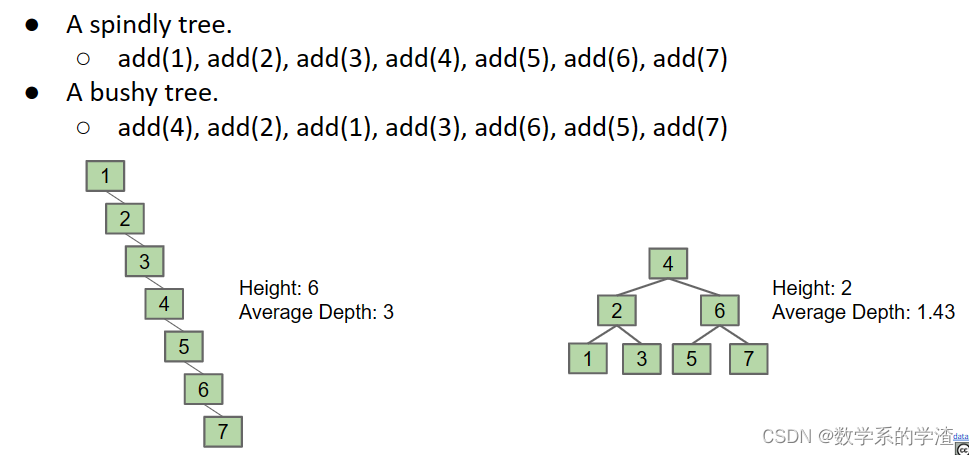
在此,先了解一些关于BST性能的术语:
- depth(深度):节点到根节点的距离
- height(高度):树最大的depth
- average depth(平均深度):树的平均depth。计算公式为 ∑ i = 0 D d i n i N \frac{\sum^D_{i=0}d_i n_i}{N} N∑i=0Ddini,其中 d i d_i di是depth, n i n_i ni是该深度的节点个数。
height决定了树最坏情况下的运行时间,average depth决定了平均运行时间。
引入B-Trees,不添加叶子节点,只将值添加到现有的叶子节点中。再限制节点中值数量的大小为L(通常为2或3),如果大于L节点将会分裂,这样就可以构建一个平衡的树。查看B-Trees的插入演示过程可以点击 这里。
B-Trees具有如下不变量来确保树永远是平衡的:(证明不清楚)
- 所有的叶节点都必须相同的距离。
- 具有 k 个值的非叶节点必须正好具有 k+1 个子节点。
B-Trees的contains()和add()方法运行时间都是
Θ
(
l
o
g
N
)
\Theta(log N)
Θ(logN),具体的分析过程可以查看slides。
7.1.2 Red Black Trees
slides
引言:B-Trees实现难度大,用BST结构+节点旋转实现红黑树来代替。
先了解树的旋转,旋转可以缩短树的长度,同时又保留了搜索二叉树的属性,节点的左旋和右旋如下图所示:

左倾红黑树:用一个左连接来表示相连的两个值,有如下特点:
- 结构上是一个正常的BST。
- LLRB(Left-Leaning Red Black Binary Search Tree)和 2-3Trees是一个一一对应的关系。
- 红色的链接只是为了方便说明
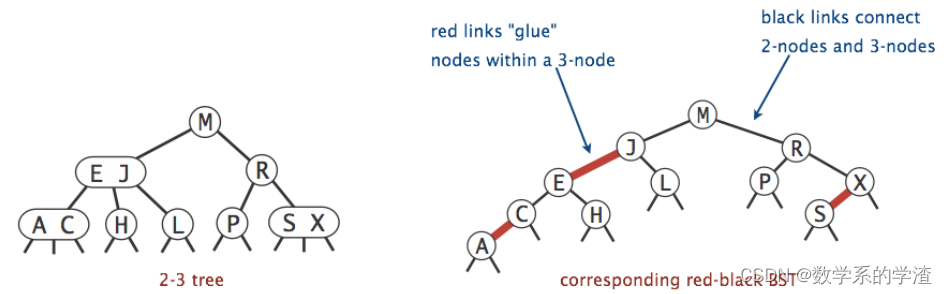
关于LLRB的高度,假设2-3Trees高度是H,那么LLRB的最大高度是H (black) + H + 1 (red) = 2H + 1(可以想象满2-3Trees对应的LLRB高度)。
关于LLRB的特征:
- 没有节点有两个红色连接(否则对应的2-3Trees就会有一个节点有四个子节点)
- 叶节点到根节点都用相同数量的黑色连接(否则对应的2-3Trees就不平衡)
使用旋转来保持2-3Trees和LLRB之间的一一对应关系:
- 插入时,使用红色连接
- 如果是右倾的连接,由于LLRB有左倾的限制,左旋。
- 如果是两个连续的红色左连接,违反了2-3Trees结构,右旋。
- 如果有节点有两个红色连接,将两个红色连接转换到其父节点连接上。
LLRB运行时间分析:
- LLRB高度为 O ( l o g N ) O(logN) O(logN)
contains()方法是 O ( l o g N ) O(logN) O(logN)insert()方法是 O ( l o g N ) O(logN) O(logN)- O ( l o g N ) O(logN) O(logN)添加新节点
- O ( l o g N ) O(logN) O(logN)旋转和颜色转换
LLRB抽象代码的实现:
private Node put(Node h, Key key, Value val) {
if (h == null) { return new Node(key, val, RED); }
int cmp = key.compareTo(h.key);
if (cmp < 0) { h.left = put(h.left, key, val); }
else if (cmp > 0) { h.right = put(h.right, key, val); }
else { h.val = val; }
if (isRed(h.right) && !isRed(h.left)) { h = rotateLeft(h); }
if (isRed(h.left) && isRed(h.left.left)) { h = rotateRight(h); }
if (isRed(h.left) && isRed(h.right)) { flipColors(h); }
return h;
}
7.1.3 Hashing
slides
目前为止,关于BST仍有两个问题需要解决:
- 节点值需要可比较的
- 有比复杂度 Θ ( l o g n ) \Theta(logn) Θ(logn)更好的数据结构
下面就是课程的思路历程:
- DataIndexedIntegerSet:用整数下标来表示items
- 浪费空间,需要储存每个item对应的下标
- 只能表示整数类型,无法插入一个String类型值
- DataIndexedEnglishWordSet:使用26进制算法来表示每个英语字符串,例如:
"
c
a
t
"
=
"
c
"
×
2
6
2
+
"
a
"
×
2
6
1
+
"
t
"
×
2
6
0
=
3
×
2
6
2
+
1
×
2
6
1
+
20
×
2
6
0
=
2074
"cat"="c"\times26^2+"a"\times26^1+"t"\times26^0=3\times26^2+1\times26^1+20\times26^0=2074
"cat"="c"×262+"a"×261+"t"×260=3×262+1×261+20×260=2074
- 目前可以插入数字和英语句子,同样的方法使用ASCII就可插入其它字符
- 有整数溢出风险,或者说,无法用
Integer范围内的值来表示所有items - 仍然十分浪费空间
- HashCodes:将Object转换为一个整数值,即转化为Hash codes,有如下特征:
- 必须是一个整数
- 两次计算结果相同
- 相等的Object计算结果相同
- Hash Table:分离链接法 + 取模
- 数据先通过hash函数映射成一个hash code
- 然后将hash code减少成一个给定范围内的值,通常使用取模操作
- 运行复杂度取决于链表的长度
Q
Q
Q

- 自动增长的Hash Table:假设其总共有 M M M个桶(有效下标)和 N N N个items,则负载因子为 N / M N/M N/M,这也是理想链表长度 Q Q Q。给负载因子取一个阈值,如1,当大于阈值时,扩充桶的数量,这样可以确保运行时间为 O ( 1 ) O(1) O(1)。
在Java中,Hash Table结构被经常使用,例如HashMap和HashSet,当使用它们的时候有两个注意点:
- 不要储存可以改变的类,这可能导致items丢失。
- 在没有重写
hashCode方法时,不要重写equals方法。
一个好的hash code生成方法:(Extra)
希望将data均匀的映射到整数上,可以考虑将数据乘以某个基数的幂,以确保所有数据都打乱成一个看似随机的整数。下面时Java8中String类的hash code方法:
@Override
public int hashCode() {
int h = cachedHashValue;
if (h == 0 && this.length() > 0) {
for (int i = 0; i < this.length(); i++) {
h = 31 * h + this.charAt(i);
}
cachedHashValue = h;
}
return h;
}
通常选取小的质数作为基数:
- 可以尽量避免溢出问题。
- 哈希代码结果与存储桶数量有不良关系的可能性较低。
- 计算量更小。
7.2 完成 Lab 7: BSTMap
除了remove, iterator和keySet为可选择实现的额外方法,实现Map61B接口的其它方法。对于没有实现的方法,抛出UnsupportedOperationExceptions异常即可。强烈建议参考lab7代码里提供的ULLMap.java来编写BSTMap。由于Map的Key需要是可比较的,所以在编写类时参考以下格式:
public class BSTMap<K extends Comparable<K>, V> {
...
}
7.3 完成 HW2: Conceptual Review
当作复习看一看即可。
Week08
8.1 课程总结
8.1.1 Heaps and Priority Queue
slides
Reading 13.1~13.3
Reading 14.1 Data Structures Summary
先介绍优先队列(PQs),下面是最小优先队列的接口:
/** (Min) Priority Queue: Allowing tracking and removal of
* the smallest item in a priority queue. */
public interface MinPQ<Item> {
/** Adds the item to the priority queue. */
public void add(Item x);
/** Returns the smallest item in the priority queue. */
public Item getSmallest();
/** Removes the smallest item from the priority queue. */
public Item removeSmallest();
/** Returns the size of the priority queue. */
public int size();
}
目前所学过的结构来实现优先队列的时间复杂度如下:
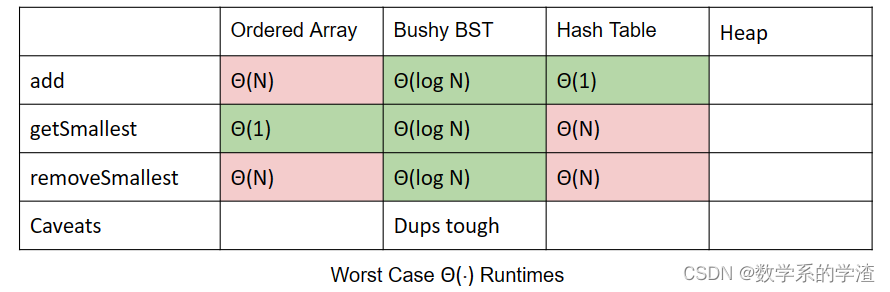
下面介绍Heap,关于二分最小堆的定义,需要是完全的且满足最小堆的属性:
- min-heap(最小堆):所有节点小于等于子节点
- complete(完全的):只在树的最底部缺少节点,且尽量靠左
使用堆实现的优先队列,其中的方法描述如下
add:将节点添加到堆的底部,让该节点上浮。 Θ ( l o g N ) \Theta(log\ N) Θ(log N)getSmallest:返回根节点。 Θ ( 1 ) \Theta(1) Θ(1)removeSmallest:将堆中最后一个节点替换到根节点上,该节点下沉。 Θ ( l o g N ) \Theta(log\ N) Θ(log N)
关于树的实现方法有很多种
- 创建到子节点的映射,有如下三种方法
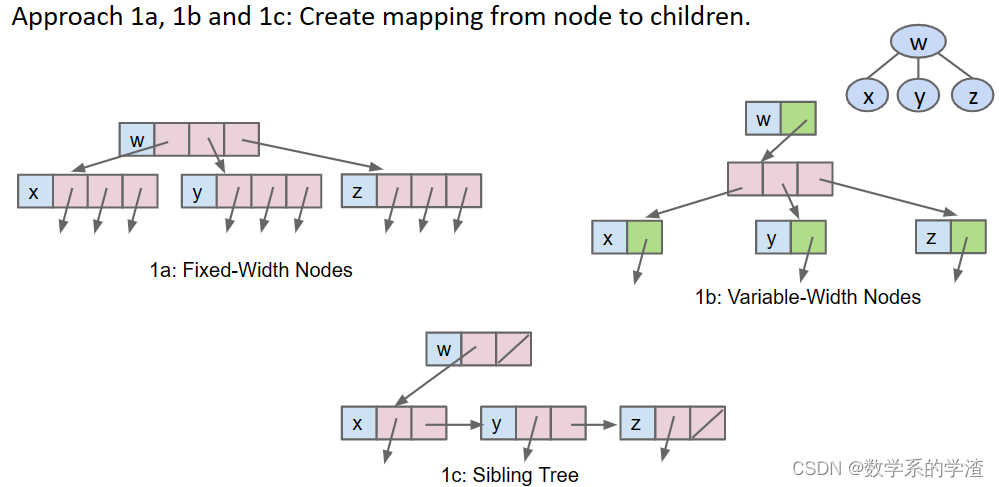
- 将keys和parentIDs存储在数组中

- 只储存keys在数组中,其父节点的下标可以简单计算得出, p a r e n t ( k ) = ( k − 1 ) / 2 parent(k) = (k-1)/2 parent(k)=(k−1)/2
关于数据结构的总结,数据结构是一种特定的组织数据的方法,某一种抽象的数据结构,例如Set、Map等,都有多种抽象结构的实现,这种层层抽象的想法,直到最后一层来具体实现。下图是部分目前所学的联系图谱,将所学的东西串联起来

8.1.2 Tree and Traversals
slides
树的定义:由节点(或顶点)和边组成,在两个节点之间有唯一的路径。
有根树的定义:有指定根节点的树,引申出以下两个概念
- A parent:除了根节点之外的每个节点都只有一个父节点
- A child:一个节点可以有0或多个孩子
树的遍历:

- Level Order Traversal(层序遍历):DBFACEG
- Pre-order Traversal(先序遍历):DBACFEG
- In-order Traversal(中序遍历):ABCDEFG
- Post-order Traversal(后序遍历):ACBEGFD
图(Graph)的定义:由节点(或顶点)和边组成,但没有其它限制条件。本节课讨论的都为简单图,即不存在重复边;不存在顶点到自身的边。详细分类可以参考以下 链接。
关于图的问题有很多,例如欧拉回路、汉密尔顿回路等。下面通过解决顶点(节点)s 和 t 之间是否相连来引出depth-first traversal方法( 演示)。

- DFS Preorder:先序深度优先遍历,在调用邻居节点之前先执行。上图遍历结果为 012543678
- DFS Postorder:后序深度优先遍历,在调用完邻居节点之后再执行。347685210
- BFS order:广度优先遍历,下节介绍。0 1 24 53 68 7
8.1.3 BFS and Graph Implementations
slides
BFS(Breadth First Search):广度优先遍历( 演示),其伪代码如下:
初始化fringe (一个包含开始节点的队列) 同时标记初始节点。
重复直到fringe为空:
从fringe中移除节点v。
对于每个未被标记的v的邻接点n:
标记n。
将n添加到fringe中。
Set edgeTo[n] = v.
Set distTo[n] = distTo[v] + 1.
fringe是一个术语,用来储存周围节点的数据结构。edgeTo[...]用来记录路径,distTo[...]用来记录距离。
下面讨论如何在代码层面实现图的结构和其算法的表示。
整数节点的图的API如下,可以通过调用API中提供的方法实现关于图的算法:
public class Graph {
public Graph(int V): // Create empty graph with v vertices
public void addEdge(int v, int w): // add an edge v-w
Iterable<Integer> adj(int v): // vertices adjacent to v
int V(): // number of vertices
int E(): // number of edges
...
关于图底层的存储结构有以下几种:
- Adjacency Matrix(邻接矩阵)
- Edge Sets(边的集合):一个储存所有边的集合。
- Adjacency Lists(邻接链表)
不同存储结构实现图的API的时间复杂度如下,其中V是节点的数量,E是边的数量:

同时,不同的存储结构对实现图的算法的时间和空间复杂度也不同,例如:
- 使用邻接链表实现DFS和BFS: O ( V + E ) O(V + E) O(V+E)
- 使用邻接矩阵实现DFS和BFS: O ( V 2 ) O(V^2) O(V2)
使用图的API来实现DFS的代码如下:
public class DepthFirstPaths {
private boolean[] marked;
private int[] edgeTo;
private int s;
public DepthFirstPaths(Graph G, int s) {
...
dfs(G, s);
}
private void dfs(Graph G, int v) {
marked[v] = true;
for (int w : G.adj(v)) {
if (!marked[w]) {
edgeTo[w] = v;
dfs(G, w);
}
}
}
...
}
8.2 完成 Lab 8: HashMap
和Lab 7类似,还是需要实现Map61B接口,但这次底层存储结构从BST改成了Hash表,且这次需要实现除了remove()外的所有方法,包括keySet 和iterator方法。
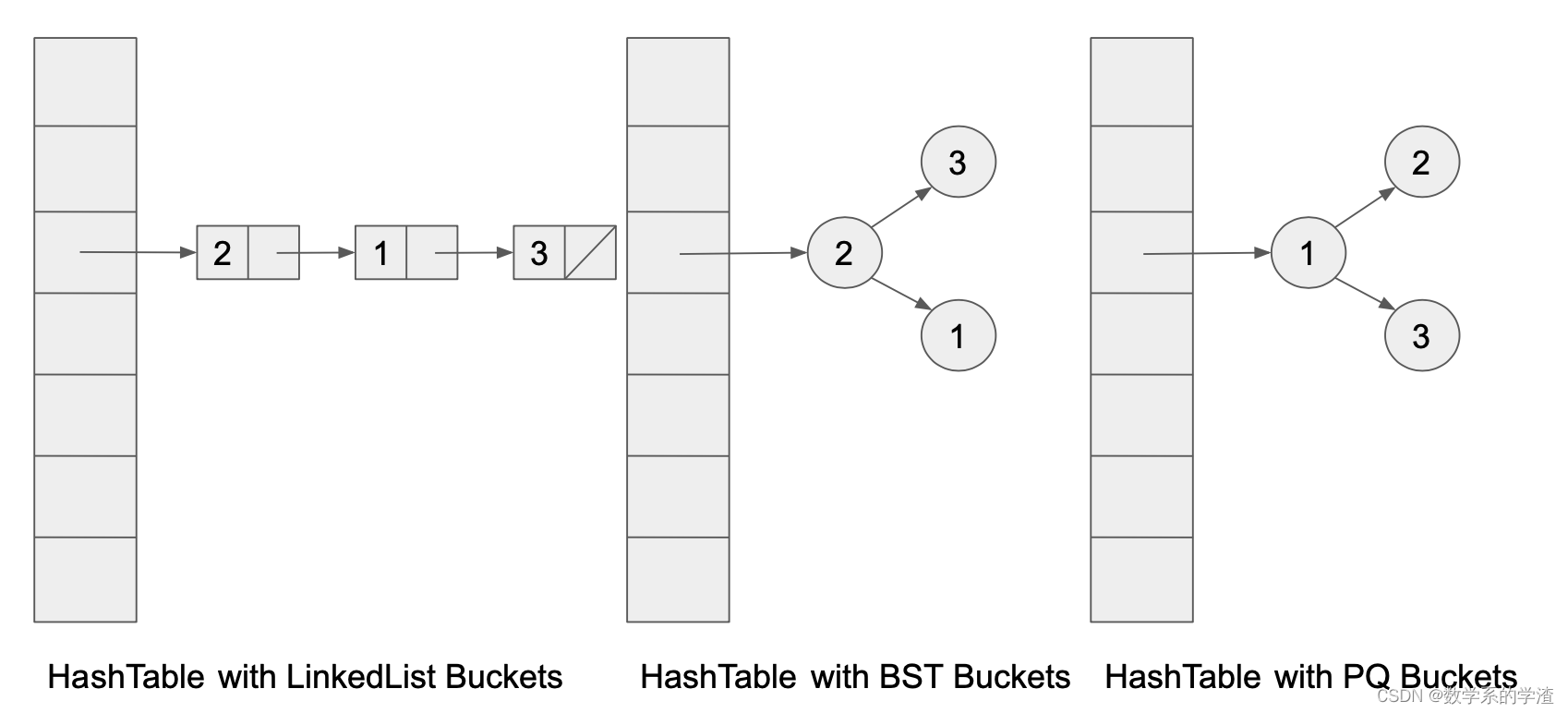
对于Hash表中的每个桶,本次实验尝试使用不同的储存结构,包括LinkedList等集合类,并测试不同存储结构的速度。
实现代码细节如下:
-
变量
private Collection<Node>[] buckets; // 储存所有桶的数组。 private int size; // items数量。 private double loadFactor; // 负载因子,(# items / # buckets)需要<=loadFactor private Set<K> ks = new HashSet<>(); // 储存所有keys的集合 -
构造器
public MyHashMap(); public MyHashMap(int initialSize); public MyHashMap(int initialSize, double loadFactor); -
工厂函数
// 创建Node private Node createNode(K key, V value) // 创建桶,子类重写此方法即可更换底层存储结构 protected Collection<Node> createBucket() // 创建Hash表,初始大小为tableSize private Collection<Node>[] createTable(int tableSize) -
实现接口函数
public void clear() public boolean containsKey(K key) public V get(K key) public int size() public void put(K key, V value) public Set<K> keySet() public Iterator<K> iterator() -
helper函数
// 返回对应key的节点 private Node getNode(K key) // 根据给定的桶数量num求k的映射下标,使用了Math.floorMod private int getIndex(K k, int num) // 改变Hash表的大小 private void resize(int x)
Week09
9.1 课程总结
9.1.1 Shortest Paths
Reading 19.1~19.3
Dijkstra’s Algorithm
迪杰斯特拉算法可以返回从给定顶点
s
s
s到其它顶点的最短距离(最短路径树)。具体实现步骤如下:
- 创建一个优先队列
- 将 s s s添加进优先队列,并优先级设为 0 0 0,其它顶点添加设为 ∞ \infty ∞
- 当队列不为空时,弹出一个顶点,松弛所有该顶点的边
注:松弛指从该顶点出发的边,到其它顶点的结果更好(对路径来说就是比优先队列的值小),则更新优先队列的值并将路径改为更好的结果。但不会松弛已经访问过的点,即不在优先队列中的点。
伪代码如下:
def dijkstras(source):
PQ.add(source, 0)
For all other vertices, v, PQ.add(v, infinity)
while PQ is not empty:
p = PQ.removeSmallest()
relax(all edges from p)
def relax(edge p,q):
if q is visited (i.e., q is not in PQ):
return
if distTo[p] + weight(edge) < distTo[q]:
distTo[q] = distTo[p] + w
edgeTo[q] = p
PQ.changePriority(q, distTo[q])
Dijkstra算法证明
A Star(A*)
寻找确定起点和终点之间的最短路径,相比较迪杰斯特拉算法是找到所有点到起始点的最短路径,对于特定场景效率更高,具体可查看 链接。
9.1.2 Minimum Spanning Trees
Reading 20.1~20.2
最小生成树表示图中连接所有顶点的且权重最小的边的集合。它是一个树,满足相连且无循环的特征。探究如何生成一个最小生成树。
Cut Property(切分定理)
给定的任意切分(cut),最小横切边(crossing edge)是最小生成树的一部分。
- cut:将图切割成两个独立的非空子图。
- crossing edge:连接两个子图的边。
切分定理证明:假设最小横切边e不在MST(最小生成树)中,存在其它的边f使得其是最小生成树。那么f肯定是横切边,否则两子图无法相连。那可以用e替换f得到一个权重更小的树,矛盾。
Prim算法
寻找最小生成树的算法。步骤如下:
- 选择任意顶点作为初始生成树。
- 重复添加距离生成树最小的点加入生成树。
- 直到V - 1个边为止。(V表示节点数)
简短证明:将当前生成树看作一个集合,其余的顶点看成另一个集合,则根据切分定理,每次添加的都是最小边,该边肯定为最小生成树的一部分。
Kruskal算法
另一个寻找最小生成树的算法。步骤如下:
- 将所有边按照权重从小到大排序。
- 每次尝试添加最小边加入当前生成树结构中,如果不构成树(成环)就跳过。
- 直到当前生成树有V - 1个边为止。
简短证明:每次添加的边都会连接两个子图,该边是横切边,且是连接两子图中最小的横切边,则根据切分定理,该边肯定为最小生成树的一部分。
算法复杂度对比:

以上复杂度分析过程用Kruskal算法举例,其余分析过程相同:

9.1.3 Range Searching and Multi-Dimensional Data
Reading 16.1~16.3
对于一维检索问题,二叉树可以很好的解决,但对于二维甚至更高维,二叉树无法很好解决,抛出如下两个问题:
- 2D范围检索:在给定范围的内存在多少物体?
- 最近相邻物体:在空间中离某一物体最近的物体是什么?
解决方案:
-
HashTable:将所有物体存储到HashTable中。需要遍历所有的bucket,复杂度为 O ( N ) O(N) O(N)。
-
Uniform Partitioning:将平面均匀切分成 4 × 4 4\times4 4×4的表格,每次寻找物体时只需要在指定几个方框中寻找即可。但复杂度仍为 O ( N ) O(N) O(N)。
-
QuadTrees:每个点都将平面分割为四块,有四个方向。对于2维的平面够用了。
- X-Based Trees or Y-Based Tree:只考虑X维度或Y维度来构建二叉树,会有信息丢失问题,在考虑的维度上,时间复杂度为 O ( l o g N ) O(logN) O(logN),但在另一维度上就为 O ( N ) O(N) O(N),例如在X-based树上寻找上下方向最近的物体。

-
K-D Trees:对于更高维度可以使用K-D树,树的每一层都会更换维度,以2-D为例, 这里为演示链接,第一层像X-based树,第二层像Y-based树,然后第三层又像X-based树,不断重复。

使用K-D树来找最近邻物体,步骤如下,演示点击 这里
- Start at the root and store that point as the “best so far”. Compute its distance to the query point, and save that as the “score to beat”. In the image above, we start at A whose distance to the flagged point is 4.5.
- This node partitions the space around it into two subspaces. For each subspace, ask: “Can a better point be possibly found inside of this space?” This question can be answered by computing the shortest distance between the query point and the edge of our subspace (see dotted purple line below).
- Continue recursively for each subspace identified as containing a possibly better point.
- In the end, our “best so far” is the best point; the point closest to the query point.
9.2 完成 Project 2: Gitlet
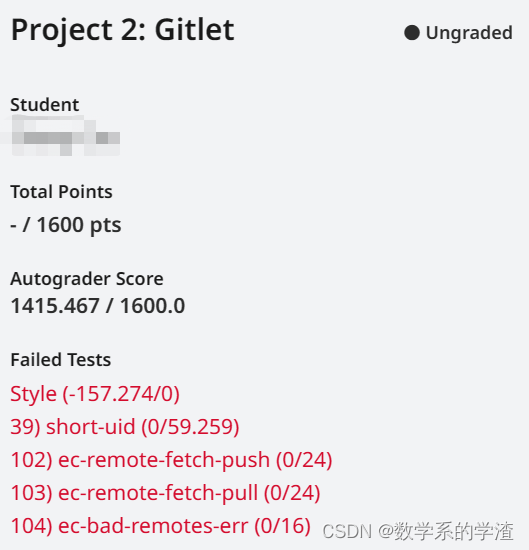
上图为将代码上传到gradescope上的得分。格式问题主要因为自己编写的测试文件内中有很多TODO,commitID前缀识别功能没有实现,远程连接功能没有实现。后续考虑发布Gitlet设计思路。
Week11
11.1 课程总结
11.1.1 Tries and Prefix Operations(前缀操作)
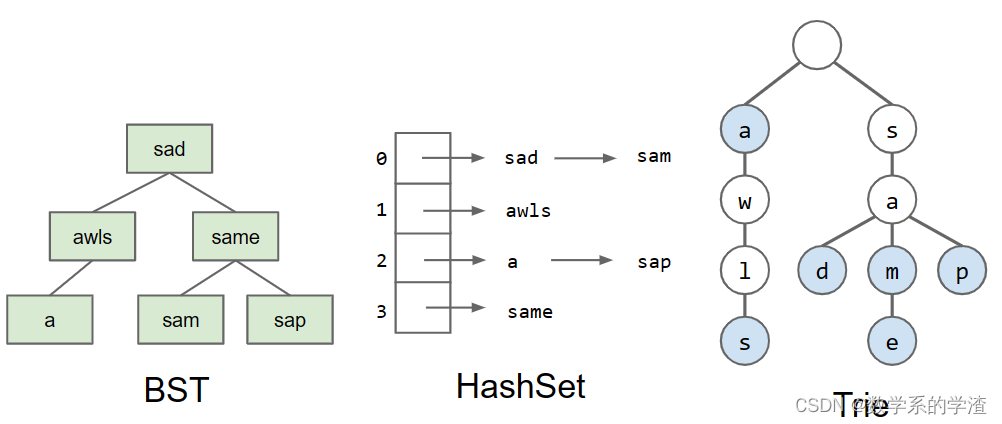
Trie是专门用于字符串的Set和Map的一种实现,对于get,add和一些特定的字符串操作有很好的性能。Trie的基本实现如下:
public class DataIndexedCharMap<V> {
private V[] items;
public DataIndexedCharMap(int R) {
items = (V[]) new Object[R];
}
public void put(char c, V val) {
items[c] = val;
}
public V get(char c) {
return items[c];
}
}
public class TrieSet {
private static final int R = 128; // ASCII
private Node root; // root of trie
private static class Node {
private boolean isKey;
private DataIndexedCharMap next;
private Node(boolean blue, int R) {
isKey = blue;
next = new DataIndexedCharMap<Node>(R);
}
}
}
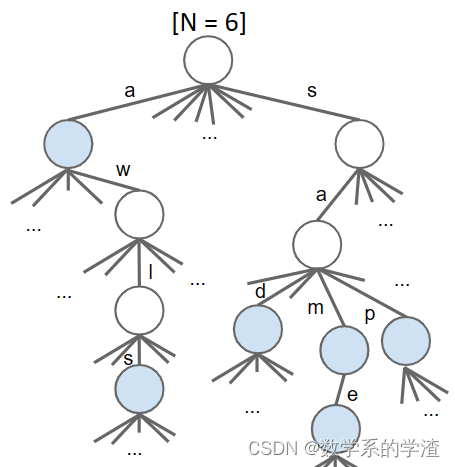
add和contains方法的时间复杂度都为
O
(
1
)
O(1)
O(1),或者说是
O
(
L
)
O(L)
O(L),
L
L
L是字符串的长度。我们可以看出,使用DataIndexedCharMap结构去存储其子节点有大量的空值,可以考虑用BST和HashTable来替代。不同结构的Trie时间和空间的复杂度分析如下:
- DataIndexedCharMap
空间:每个节点128个连接
时间: Θ ( 1 ) \Theta(1) Θ(1) - BST(二叉搜索树)
空间:每个节点 C C C个连接, C C C表示子节点的数量
时间: O ( l o g R ) O(logR) O(logR), R R R是字母表大小 - Hash Table
空间:每个节点 C C C个连接, C C C表示子节点的数量
时间: O ( R ) O(R) O(R), R R R是字母表大小
R
R
R是个固定的数字,比如128,所以可以考虑时间复杂度为常数级别。
Trie比其它结构在add和contains方法上好一点,但不一定在其它方面更好,比如要遍历每个字符串,Trie需要遍历其所有的字符,而BST就可以直接获取整个字符串。但Trie结构的优势在于可以高效地执行一些特定的字符串操作,比如前缀匹配。下面是collect方法的伪代码,collect方法返回Trie的所有keys:
collect():
Create an empty list of results x
For character c in root.next.keys():
Call colHelp(c, x, root.next.get(c))
Return x
colHelp(String s, List<String> x, Node n):
if n.isKey:
x.add(s)
For character c in n.next.keys():
Call colHelp(s + c, x, n.next.get(c))
上面的colHelp方法递归的将指定前缀s的所有字符串存入到List中,然后keysWithPrefix方法的伪代码就可以实现如下:
keysWithPrefix(String s):
Find the node of the prefix, alpha
Create an empty list x
For character c in alpha.next.keys():
Call colHelp(s + c, x, alpha.next.get(c))
Return x
Autocomplete方法经常被用于搜索引擎中,自动补全你当前输入在输入框中的字符串s。可以考虑用Trie结构,每次返回keysWithPrefix(s)排名靠前的几个字符串。这样如果Trie中储存了很多keys,会导致需要遍历所有的keys来选出排名靠前的几个,复杂度过高,可以考虑在每个节点上储存一个子树最高排名值,具体实现就不探究了。(就是将下图中第一个图变成第二个图)

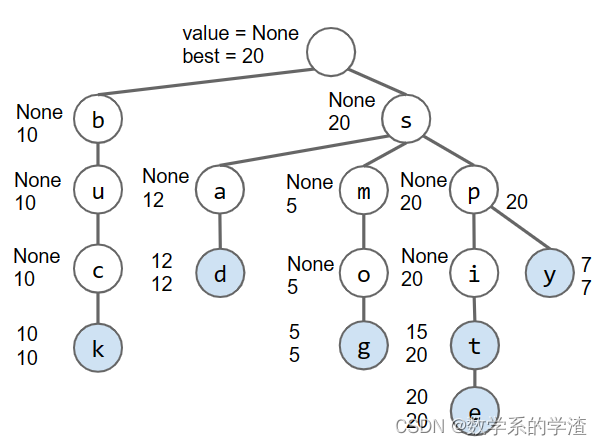
11.1.2 软件工程Ⅰ
没太懂,就总结以下几点:
- 减少代码冗余
- 时间复杂度控制
- 代码理解复杂度和所花时间的权衡,尽量减少理解上的难度,方便后期维护
- 项目的可拓展性,在设计时需要考虑项目未来会进行那些方面的提升和改变
11.1.3 拓扑排序
Reading 21.1~21.4
拓扑序列定义:有向图的拓扑序是其顶点的线性排序,使得若存在从顶点
u
u
u 到顶点
v
v
v 的有向边,
u
u
u 在序列中都在
v
v
v 之前。
限制:拓扑排序只适用于有向的,无环的图(DAGs)。

拓扑排序算法:
- 使用DFS算法遍历图节点
- 记录DFS后序遍历的结果
- 后序遍历的结果翻转就是一个拓扑排序
证明:每个顶点
v
v
v 只有在考虑了
v
v
v 的所有后代后,才会添加到后序列表的末尾。因此,当任何
v
v
v 被添加到后序列表中时,它的所有后代都已经在列表中。因此,反转此列表就是一个拓扑排序。
拓扑排序伪代码:
topological(DAG):
initialize marked array
initialize postOrder list
for all vertices in DAG:
if vertex is not marked:
dfs(vertex, marked, postOrder)
return postOrder reversed
dfs(vertex, marked, postOrder):
marked[vertex] = true
for neighbor of vertex:
dfs(neighbor, marked, postOrder)
postOrder.add(vertex)
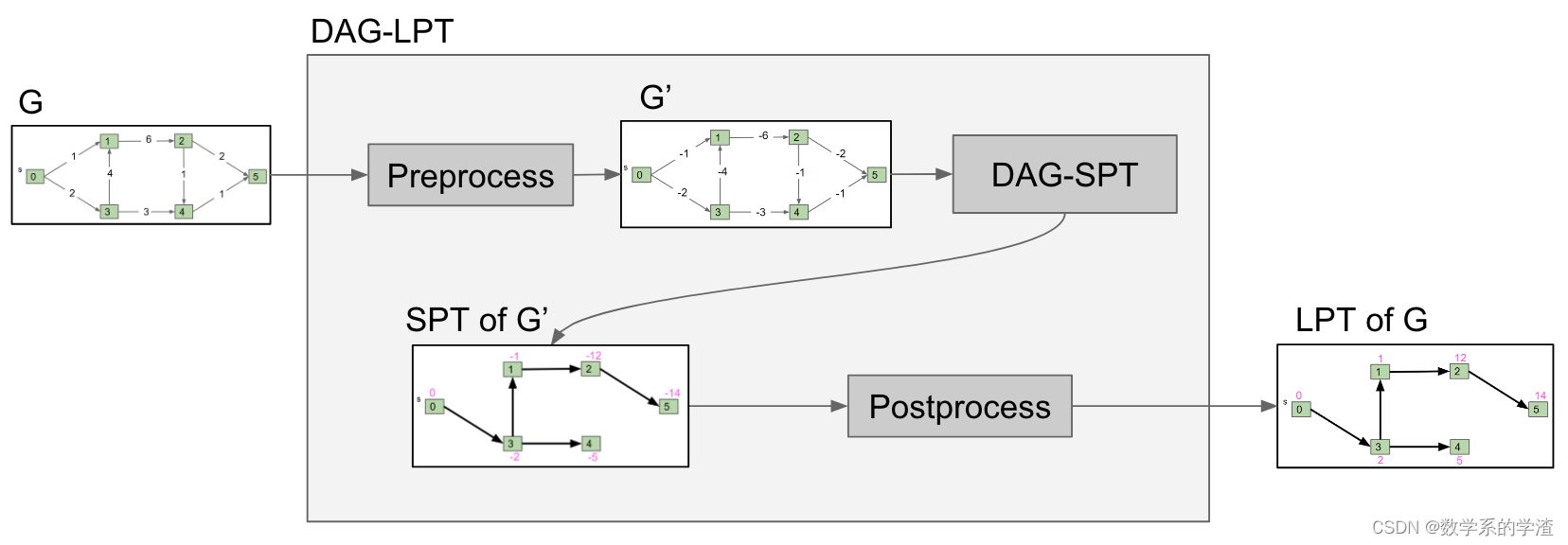
拓扑排序的应用:Dijkstra算法无法解决含负数边的最短路径问题,而在DAG上可以简单使用拓扑排序来解决。按照拓扑排序的顺序遍历节点,更新当前节点的最短距离即可(证明略)。该算法的复杂度只有
O
(
V
+
E
)
O(V + E)
O(V+E),
V
V
V 是节点数,
E
E
E 是边数。如果不是在DAG上,可以用 Bellman Ford 算法解决含负数边的最短路径问题。
解决了在DAG上的最短路径问题,最长路径问题可以看出将每条边转换为负数的最短路径问题。下图为最长路径问题和最短路径问题的转换:
Week12
12.1 课程总结
12.1.1 Sort(排序)
slide
-
Select Sort(选择排序)
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。重复直到所有元素均排序完毕。
时间复杂度: Θ ( N 2 ) \Theta(N^2) Θ(N2)
空间复杂度: Θ ( 1 ) \Theta(1) Θ(1) -
Heapsort(堆排序)
用所有元素建一个最大堆,找到最大元素(堆顶),添加至结果,删除堆顶,重复 N 次。可以用原地堆排序来节省空间,不需要创建新的数组来储存结果。
时间复杂度:最坏 Θ ( N l o g N ) \Theta(NlogN) Θ(NlogN),最好 Θ ( N ) ∗ \Theta(N)^* Θ(N)∗
空间复杂度: Θ ( 1 ) \Theta(1) Θ(1) -
Mergesort(归并排序)
算法步骤:- 分解(Divide):将n个元素分成个含n/2个元素的子序列。
- 解决(Conquer):用合并排序法对两个子序列递归的排序(递归算法)。
- 合并(Combine):合并两个已排序的子序列已得到排序结果。
时间复杂度: Θ ( N l o g N ) \Theta(NlogN) Θ(NlogN)
空间复杂度: Θ ( N ) \Theta(N) Θ(N) -
Insertion Sort(插入排序)
创建一个空的输出数组,依次将输入数组的元素正确的插入输出数组中。
对于具有少量反转的数组上(基本排好序的数组),插入排序非常快。
时间复杂度:最坏 Θ ( N ) \Theta(N) Θ(N),最好 Θ ( N 2 ) \Theta(N^2) Θ(N2)
空间复杂度: Θ ( 1 ) \Theta(1) Θ(1)
12.1.2 Quick Sort
slide
算法步骤:
- 先从数列中取出一个数作为基准数。
- 分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
- 再对左右区间重复第二步,直到各区间只有一个数。
时间复杂度:最坏
Θ
(
N
2
)
\Theta(N^2)
Θ(N2),最好
Θ
(
N
l
o
g
N
)
\Theta(NlogN)
Θ(NlogN)
快排和BST的插入有异曲同工之妙。虽然最坏情况不如归并排序,但是快排的期望复杂度是
Θ
(
N
l
o
g
N
)
\Theta(NlogN)
Θ(NlogN),有极大概率是最好的情况。想了解更过关于这方面的证明,可以看 这里。
12.1.3 Software Engineering Ⅱ
slides
参考 《软件设计的哲学》
介绍 proj3:Build Your Own World

- 世界生成:根据给定的随机种子,随机生成一个世界。
- 互动性:根据键盘键入来将虚拟世界的角色移动。
代码的复杂度来源
- 依赖关系:一段代码无法独立读取、理解和修改。比如重复代码过多,修改时需要修改多处地方。
- 晦涩难懂:重要信息不明显。
在写项目时,需要更有策略的编程,尽量减少代码的复杂度,一个有效的方法就是多写 helper function。
模块设计
我们可能会将一个大的系统分割成一个个模块,模块并不特指某个类或包,我们的目标是让模块之间的依赖度最小。
- 接口和实现:接口尽量简单,实现尽量高效。
- 信息隐藏:每个模块应封装一些知识,这些知识代表设计决策。该知识嵌入在模块的实现中,但不会出现在其界面中,因此其他模块不可见。
- 注意信息泄露:信息隐藏的反面是信息泄漏。当一个设计决策反映在多个模块中时,就会发生信息泄漏。
团队合作
简单来说就是降低对队友的期望,多沟通,大家都是人,难免会犯错误。
11.2 完成 Lab 12: Getting Started on Project 3
更新中…















 406
406










 暂无认证
暂无认证


















 到【灌水乐园】发言
到【灌水乐园】发言










泥人十四: 请问还会更新吗?
泥人十四: 特别好
2301_80359429: 很棒的笔记
Para Que La Vida: 膜拜大佬
膜拜大佬
数学系的学渣: 推荐看一下原题解:https://www.acwing.com/solution/content/13191/,或者看y总的视频讲解:https://www.acwing.com/video/314/