图神经网络中的过平滑问题

 于 2021-07-06 12:00:00 发布
于 2021-07-06 12:00:00 发布
 阅读量2.2k
阅读量2.2k
 收藏
31
收藏
31


 点赞数
10
点赞数
10
图神经网络图解指南
图神经网络或简称 GNN 是用于图数据的深度学习 (DL) 模型。这些年来它们变得很热。这种趋势在 DL 领域并不新鲜:每年我们都会看到一个新模型的脱颖而出,它要么在基准测试中显示最先进的结果,要么是一个全新的机制/框架到已经使用的模型中(但是你阅读论文时会感到很简单)。这种反思让我们质疑这种专门用于图形数据的新模型存在的原因。

为什么我们需要GNN ?
图表无处不在:图表数据非常丰富,我认为这是展示我们每天产生或消费的材料最自然、最灵活的方式。从大多数公司和Facebook或Twitter等社交网络中使用的关系数据库,到科学和文学中连接知识创造的引文图表,我们不需要费力地列举一系列图表数据的例子。甚至图像也可以被看作是图表,因为它们的网格结构。

对于关系数据库,实体是节点,而关系(一对一,一对多)定义了我们的边。对于图像,像素是节点,可以用相邻的像素来定义边缘
模型能够捕获图中所有可能的信息:正如我们所见,图数据无处不在,并且采用具有特征向量的互连节点的形式。是的,我们可以使用一些多层感知器模型来解决我们的下游任务,但是我们将失去图拓扑为我们提供的连接。至于卷积神经网络,它们的机制专用于图的一种特殊情况:网格结构的输入,其中节点完全连接而没有稀疏性。话虽如此,唯一剩下的解决方案是一个模型,它可以建立在两个给出的信息之上:节点的特征和我们图中的局部结构,这可以减轻我们的下游任务;这就是 GNN 所做的。
GNN 训练哪些任务?
既然我们已经适度地证明了这些模型的存在,我们将揭示它们的用法。事实上,我们可以在很多任务上训练 GNN:大图中的节点分类(根据用户的属性和关系对社交网络中的用户进行细分),或全图分类(对药物应用的蛋白质结构进行分类)。除了分类之外,回归问题还可以在图数据之上制定,不仅适用于节点,也适用于边。
总而言之,图神经网络的应用是无穷无尽的,取决于用户的目标和他们拥有的数据类型。为简单起见,我们将专注于唯一图中的节点分类任务,我们尝试将以特征向量为首的节点图子集映射到一组预定义的类别/类。
该问题假设存在一个训练集,其中我们有一组标记的节点,并且图中的所有节点都有一个我们注意到 x 的特定特征向量。我们的目标是预测验证集中特征节点的标签。

节点分类示例:所有节点都有一个特征向量;
彩色节点已标记,而白色节点未标记
GNN的本质
现在我们已经设置了我们的问题,是时候了解 GNN 模型将如何训练以输出未标记节点的类。事实上,我们希望我们的模型不仅要使用我们节点的特征向量,还要利用我们处理的图结构。
使 GNN 独一无二的最后一条语句必须包含在某个假设中,该假设声明相邻节点倾向于共享相同的标签。GNN通过使用消息传递形式化来整合这一点,本文将进一步讨论这一概念。我们将介绍一些我们将在后面考虑的瓶颈。
上面说的非常的抽象,现在让我们看看 GNN 是如何构建的。事实上,GNN 模型包含一系列通过更新的节点表示进行通信的层(每一层为每个节点输出一个嵌入向量,然后将其用作下一层的输入以在其上构建)。
我们模型的目的是构建这些嵌入(对于每个节点),集成节点的初始特征向量和围绕它们的局部图结构的信息。一旦我们有了很好的嵌入,我们将经典的 Softmax 层提供给这些嵌入以输出相关类。
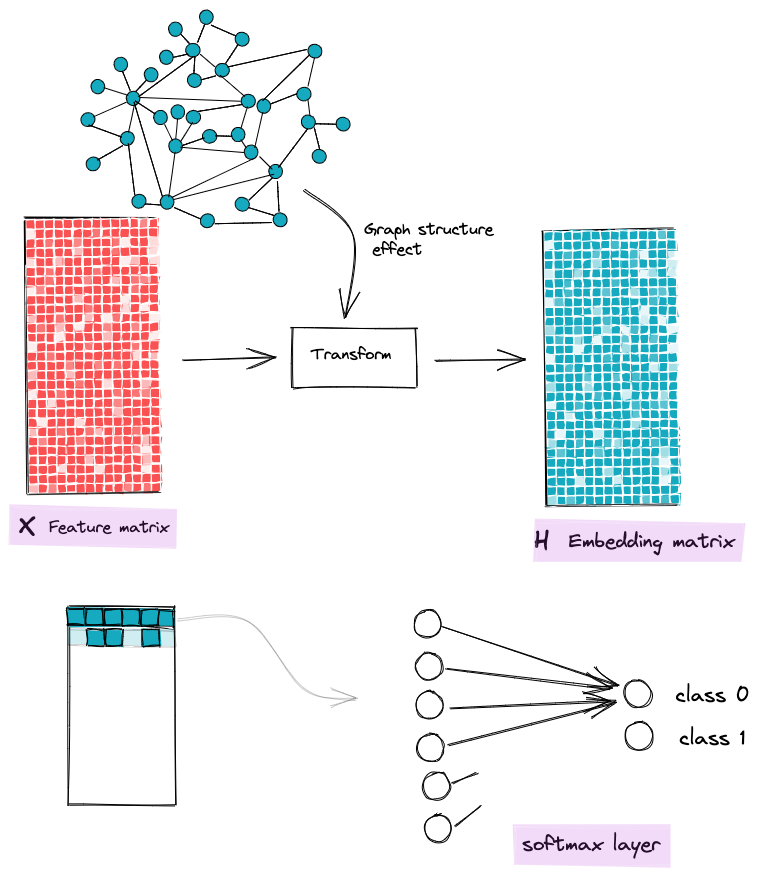
GNN的目标是将节点特征转换为能够感知图结构的特征
为了构建这些嵌入,GNN层使用了一种称为消息传递的简单机制,它帮助图节点与它们的邻居交换信息,从而一层接一层地更新它们的嵌入向量。
消息传递框架
这一切都从一些节点开始,向量 x 描述它们的属性,然后每个节点通过置换等变函数(均值、最大值、最小值……)从其邻居节点收集其他特征向量。换句话说,一个对节点排序不敏感的函数。这个操作叫做聚合,它输出一个消息向量。
第二步是Update函数,节点将从它的邻居(消息向量)收集到的信息与它自己的信息(特征向量)结合起来,构造一个新的向量h: embedded。
该聚合和更新函数的实例化在不同的论文中有所不同。您可以参考GCN[1]、GraphSage[2]、GAT[3]或其他,但消息传递的思想保持不变。

我们的 GNN 模型第一层从特征向量 x0 到其新嵌入 h 的插图
这个框架背后的直觉是什么?好吧,我们希望我们节点的新嵌入能够考虑到本地图结构,这就是我们从邻居节点聚合信息的原因。通过这样做,人们可以直观地预见聚合后的一组邻居节点将具有更相似的表示,这将减轻我们最终的分类任务。在我们的第一个假设(邻居节点倾向于共享相同的标签)的情况下,所有这些都是成立的。
GNN 中的层组合
现在我们已经了解了消息传递的主要机制,是时候了解层在 GNN 上下文中的含义了。
回想上一节,每个节点使用来自其邻居的信息来更新其嵌入,因此自然扩展是使用来自其邻居(或第二跳邻居)的邻居的信息来增加其感受野并变得更加了解 图结构。这就是我们 GNN 模型的第二层。
我们可以通过聚合来自 N 跳邻居的信息将其推广到 N 层。

一层接一层,节点可以访问更多的图节点,并具有更多的图结构感知嵌入
在这一点上,您对 GNN 的工作原理有了一个高层次的了解,并且您可能能够发现为什么这种形式主义会出现问题。首先,在深度学习的背景下谈论 GNN 假设存在深度(许多层)。这意味着节点将可以访问来自距离较远且可能与它们不相似的节点的信息。一方面,消息传递形式主义试图软化邻居节点之间的距离(平滑),以便稍后简化我们的分类。另一方面,它可以通过使我们所有的节点嵌入相似来在另一个方向上工作,因此我们将无法对未标记的节点进行分类(过度平滑)。
在下一节中,我将尝试解释什么是平滑和过度平滑,我们将平滑作为增加 GNN 层的自然效果进行讨论,我们将了解为什么它会成为一个问题。
我还将尝试对其进行量化(从而使其可跟踪),并在此量化的基础上使用已发表论文中关于此问题的解决方案来解决它。
GNN 中的过度平滑问题
虽然消息传递机制帮助我们利用封装在图形结构中的信息,但如果结合 GNN 深度,它可能会引入一些限制。换句话说,我们对更具表现力和更了解图结构的模型的追求(通过添加更多层,以便节点可以有一个大的感受野)可以转化为一个模型,该模型对待节点都一样(节点表示收敛到不可区分的向量[4])。
这种平滑现象既不是错误也不是特例,而是 GNN 的基本性质,我们的目标是缓解它。
为什么会发生过度平滑?
消息传递框架使用了前面介绍的两个主要函数 Aggregate 和 Update,它们从邻居那里收集特征向量并将它们与节点自己的特征结合起来更新它们的表示。此操作的工作方式使交互节点(在此过程中)具有非常相似的表示。
我们将尝试在我们模型的第一层中说明这一点,以说明为什么会发生平滑,然后添加更多层以显示这种表示平滑如何随层增加。
注意:过度平滑表现为节点嵌入之间的相似性。所以我们使用颜色,其中不同的颜色意味着向量嵌入的不同。此外,在我们的示例中,为了简单起见,我们将仅更新突出显示的 4 个节点。

GNN的第一层
正如您在第一层中看到的,节点可以访问单跳邻居。例如,您还可以观察到,节点 2 和节点 3 几乎可以访问相同的信息,因为它们相互链接并具有共同的邻居,唯一的区别是它们的最后一个邻居(紫色和黄色)。我们可以预测它们的嵌入会略有相似。对于节点 1 和节点 4,它们彼此交互但具有不同的邻居。所以我们可以预测他们的新嵌入会有所不同。
我们通过为每个节点分配新的嵌入来更新我们的图,然后移动到第二层并执行相同的过程。

GNN的第二层
在我们 GNN 的第二层,节点 1,4 和 2,3 的计算图分别几乎相同。我们可能期望我们为这些节点更新的新嵌入将更加相似,即使对于以第一层的方式“幸存”的节点 1 和节点 4 现在也将具有相似的嵌入,因为额外的层使他们可以访问更多 图的部分,增加了访问相同节点的可能性。
这个简化的例子展示了过度平滑是 GNN 深度的结果。公平地说,这与真实案例相去甚远,但它仍然提供了这种现象发生背后的原因。
为什么这真的是一个问题?
现在我们了解了为什么会发生过度平滑,以及为什么它是设计好的,这是 GNN 层组合的影响,是时候强调我们为什么应该关心它,并激励解决方案来克服它。
首先,学习嵌入的目标是最后将它们提供给分类器,以预测它们的标签。考虑到这种过度平滑的效果,我们最终会为没有相同标签的节点得到类似的嵌入,这将导致错误标记它们。
有人可能认为减少层数会降低过度平滑的效果。是的,但这意味着在复杂结构数据的情况下不利用多跳信息,因此不会提高我们的最终任务性能。
示例:为了强调最后一句,我将用一个在现实生活中经常出现的例子来说明。想象一下,我们正在处理一个具有数千个节点的社交网络图。一些新用户刚刚登录该平台并订阅了他们朋友的个人资料。我们的目标是找到主题建议来填充他们的提要。

考虑到这个假想的社交网络,在我们的GNN模型中只使用1或2层,我们将只知道我们的用户关心连接的话题,但我们错过了其他多样化的话题,他可能会喜欢他的朋友的互动。
综上所述,过度平滑作为一个问题,我们遇到了一个低效率模型和一个更有深度但在节点表示方面更缺乏表现力的模型之间的权衡。
我们如何量化它?
现在我们已经明确表示过度平滑是一个问题并且我们应该关心它,我们必须对其进行量化,以便我们可以在训练 GNN 模型时对其进行跟踪。不仅如此,量化还将为我们提供一个指标,通过将其作为正则化项添加到我们的目标函数中(或不......),用作数值惩罚。
根据我最近的阅读,很多论文都处理了 GNN 中的过度平滑问题,他们都提出了一个度量来量化它,以证明他们对这个问题的假设并验证他们的解决方案。
我从处理这个问题的两篇不同论文中选择了两个指标。
MAD 和 MADGap [5]
Deli Chen 等人引入了两个量化指标 MAD 和 MADGap,来衡量图节点表示的平滑度和过度平滑度。
一方面,MAD 计算图中节点表示(嵌入)之间的平均平均距离,并使用它来表明平滑是向 GNN 模型添加更多层的自然效果。基于此度量,他们将其扩展到 MADGap,该度量度量不同类别节点之间表示的相似性。这种概括是建立在主要假设之上的,即在节点交互时,它们可以访问来自同一类的节点的重要信息,或者通过与来自其他类的节点交互来获取噪声。

当节点访问图的更多部分时,我们可能访问影响最终嵌入的嘈杂节点
在这篇文章中引起我兴趣的是作者对建立消息传递形式的主要假设的质疑方式(邻居节点可能有类似的标签)。事实上,他们的测量MADGap不仅仅是一个过度平滑的测量,而是一个相对于我们的节点收集的信号的信息噪声比的测量。因此,观察到这个比例一层接着一层地减小,就证明了图拓扑与下游任务目标之间的不一致。
群距离比 [6]
Kaixiong Zhou 等人引入了另一个应变前向度量,但与 MADGap 具有相同的目标,即组距离比。该指标计算两个平均距离,然后计算它们的比率。我们首先将节点放在相对于它们的标签的特定组中。然后,为了构建我们的比率的提名者,我们计算每两组节点之间的成对距离,然后对所得距离求平均值。至于分母,我们计算每个组的平均距离,然后计算平均值。

说明如何计算群距离比图例
比例小意味着嵌入不同分组的节点之间的平均距离较小,因此我们可能会在分组的嵌入方面进行混合,这就是过平滑的证明。
我们的目标是保持一个高的组距离比,以在节点的嵌入方面有不同的类别,这将简化我们的下游任务。
有解决方案来克服过度平滑吗?
一个直接的监管规则?
现在我们已经量化了过度平滑问题,你可能会认为我们的工作被终止了,在我们的损失目标中添加这个度量作为一个规则就足够了。剩下的问题是,在我们的训练会话的每次迭代中计算这些度量(上面提到的)可能会耗费计算成本,因为我们需要访问我们的图中的所有训练节点,然后进行一些距离计算,处理二次缩放的节点对(C(2,n) = n * (n -1) / 2 = O(n²))
一个间接的解决方案?
因此,所有讨论过平滑问题的论文都考虑用其他更容易实现和对过平滑有影响的间接解决方案来克服这个计算问题。我们不会广泛讨论这些解决方案,但您将在下面找到其中一些参考资料。
至于我们的例子,我们将讨论Kaixiong Zhou 等人提出的可微群归一化[6]。DGN将节点分组,并对其进行独立归一化,输出新的下一层嵌入矩阵。
这个额外的层是用来优化前面定义的组距离比或Rgroup。实际上,在一个组内嵌入节点的归一化使得它们的嵌入非常相似(减少了Rgroup的分子),而这些使用可训练参数的缩放和移动使得来自不同组的嵌入不同(增加了Rgroup的分子)。
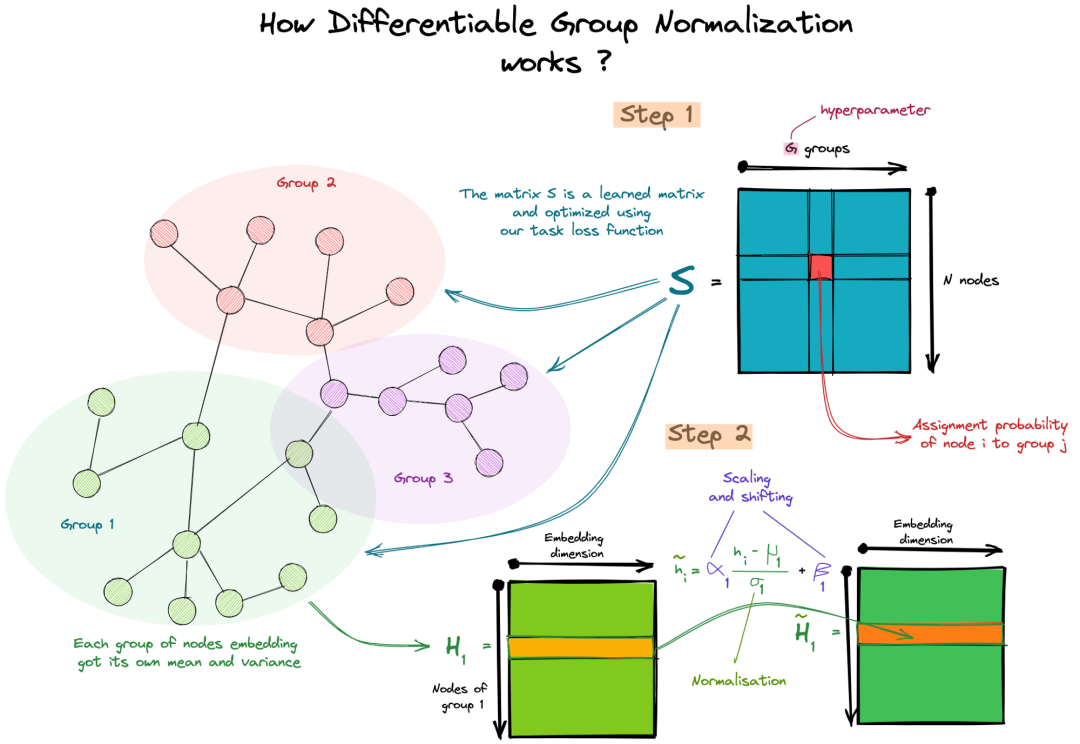
为什么有效?第一次看论文,没看到加入这个归一化层和优化Rgrou比之间的联系,后来我观察到这一层一方面使用了一个可训练的分配矩阵,因此它有来自我们的损失函数,因此指导将完美情况下的节点分配给它们的真实类。另一方面,我们还有平移和缩放参数,它们也由我们的损失函数引导。那些用于将一组嵌入到另一组的不同嵌入的参数因此有助于下游任务。
总结
这篇文章可能很长,但它只触及了图神经网络及其问题的表面,我试图从 GNN 的小探索开始,并展示它们如何 - 使用如此简单的机制 - 解锁我们无法想到的潜在应用其他 DL 架构的上下文。这种简单性受到许多阻碍其表达能力的问题的限制(至少目前来说),研究人员的目标是克服它,以寻求利用图数据的全部力量。
至于我,我阅读了不同的论文,讨论了一些 GNN 的限制和瓶颈,但将它们统一起来的一个共同点是,所有这些问题都可以与我们用来训练图模型的主要机制相关联,即消息传递。我可能不是专家,但我必须提出一些问题。继续列举这些问题并试图解决它们真的值得吗?既然我们仍处于这样一个有趣领域的第一次迭代中,为什么不考虑一种新机制并尝试一下呢?
引用
[1] Kipf, T. N. (2016, September 9). Semi-Supervised Classification with Graph Convolutional Networks. ArXiv.Org. https://arxiv.org/abs/1609.02907
[2] Hamilton, W. L. (2017, June 7). Inductive Representation Learning on Large Graphs. ArXiv.Org. https://arxiv.org/abs/1706.02216
[3] Veličković, P. (2017, October 30). Graph Attention Networks. ArXiv.Org. https://arxiv.org/abs/1710.10903
[4] Oono, K. (2019, May 27). Graph Neural Networks Exponentially Lose Expressive Power for Node Classification. ArXiv.Org. https://arxiv.org/abs/1905.10947
[5] Chen, D. (2019, September 7). Measuring and Relieving the Over-smoothing Problem for Graph Neural Networks from the Topological View. ArXiv.Org. https://arxiv.org/abs/1909.03211
[6] Zhou, K. (2020, June 12). Towards Deeper Graph Neural Networks with Differentiable Group Normalization. ArXiv.Org. https://arxiv.org/abs/2006.06972
作者:Anas AIT AOMAR
原文地址:https://towardsdatascience.com/over-smoothing-issue-in-graph-neural-network-bddc8fbc2472
翻译(转自):DeepHub IMBA
欢迎加入Imagination GPU与人工智能交流群

群已满200人,入群请加小编拉进群,
小编微信号:eetrend89(添加请备注公司名和职称)
推荐阅读

END
Imagination Technologies是一家总部位于英国的公司,致力于研发芯片和软件知识产权(IP),基于Imagination IP的产品已在全球数十亿人的电话、汽车、家庭和工作场所中使用。获取更多物联网、智能穿戴、通信、汽车电子、图形图像开发等前沿技术信息,欢迎关注 Imagination Tech !
长按识别二维码
关注我们

















 15
15
























 到【灌水乐园】发言
到【灌水乐园】发言










雾行@: 如果每个节点有四个策略,选择效益最高的策略的信息,逐个节点寻优,最终达到终点。 因为每个节点情况不一样,比如说到A点B-C之间通行时间是2,在F点B-C通行时间可能是5,每经过一个节点,所有路段的通行时间都会变化。所以它一次只能优化一个节点,达到终点后迭代结束 这种情况适合哪个算法呢
雾行@: 无模型,非策略是什么意思呢
CSDN-Ada助手: Python入门 技能树或许可以帮到你:https://edu.csdn.net/skill/python?utm_source=AI_act_python
赤赤333: ChatGPT
CSDN-Ada助手: 不知道 Python入门 技能树是否可以帮到你:https://edu.csdn.net/skill/python?utm_source=AI_act_python