第 2 部分:使用 LitmusChaos 2.0 进行容器化和混沌工程的初学者实用指南
第 2 部分:混沌工程 101,使用 LitmusChaos 2.0 进行自定义工作流混沌实验 本博客是两个博客系列的第二部分,详细介绍了如何开始使用 Docker 和 Kubernetes 进行容器化进行部署,以及稍后如何使用 LitmusChaos 2.0 执行混沌工程。在此处](https://dev.to/neelanjan00/part-1-a-beginner-s-practical-
 weixin_0010034 ·
weixin_0010034 · 第 2 部分:混沌工程 101,使用 LitmusChaos 2.0 进行自定义工作流混沌实验
本博客是两个博客系列的第二部分,详细介绍了如何开始使用 Docker 和 Kubernetes 进行容器化进行部署,以及稍后如何使用 LitmusChaos 2.0 执行混沌工程。在此处](https://dev.to/neelanjan00/part-1-a-beginner-s-practical-guide-to-containerisation-and-chaos-engineering-with-litmuschaos-2-0-3h5c)找到博客[的第 1 部分。
假设您已经使用 Kubernetes 部署了电子商务应用程序,并且您对应用程序部署的灵活性和稳定性非常满意。在应用程序的测试过程中,它已经检查了所有的方框,您非常有信心您的应用程序部署都将面临下周的销售高峰期,届时全国各地的客户都将尝试使用以下方式购买产品你的申请。但可惜,就在销售高峰时段,您的客户面临服务中断。什么地方出了错?你不知道,因为从表面上看,似乎没有什么不正常的。这种不合理的情况可以避免吗?是的,使用混沌工程。
在这篇博客中,我们将从根本上探索混沌工程;从什么是混沌工程开始,为什么需要混沌工程,它与混沌工程的测试、流程和原理有什么不同,云原生混沌工程介绍,LitmusChaos 鸟瞰图,最后,我们将进行在我们在上一篇博客中部署的应用程序上使用自定义混沌工作流程进行 pod-delete 混沌实验。
什么是混沌工程?
正如维基百科定义的那样:
混沌工程是在生产环境中对软件系统进行试验的学科,目的是建立对系统抵御动荡和意外条件的能力的信心。
在我们之前的电子商务应用程序示例中,由于尝试同时访问应用程序的用户数量急剧增加,该应用程序面临服务停机,通过确定导致服务停机的因素,可以避免这种情况.
混沌工程强调实验,也称为假设,然后将结果与定义的稳态进行比较。它也被认为是“故意破坏事物”的科学,以在系统对生产造成严重破坏之前识别出系统的不可预见的弱点。混沌工程不仅仅是故障注入,它还试图理解导致系统不稳定性的因素,并从系统整体的行为中获得洞察力,当它屈服于不利情况时,其最终目标是使系统在生产环境中更具弹性。
例如,可以通过随机禁用负责系统运行的服务并分析其对整个系统的影响来检查分布式系统的弹性。
为什么是混沌工程?
-
认识到危险和后果:通过允许您创建实验并量化它如何影响您的业务,混沌工程允许您了解湍流条件对重要应用程序的影响。公司可以在了解风险后做出明智的判断并主动做出反应,以避免或防止损失。
-
对事件的反应:因为分布式系统非常复杂,所以有几种方法会出错。灾难恢复和业务连续性的概念对于处于高度监管环境中的公司(例如金融行业)至关重要,因为即使是单次中断都可能造成高昂的代价。这些行业可能会通过进行混乱的实验来为现实生活中的情况排练、准备和建立机制。当事件发生时,混沌工程允许团队拥有正确的意识、计划和可见性水平。
-
应用程序安全性和可观察性:混沌实验可帮助您找出系统的监控和可观察性能力不足的地方,以及您的团队应对危机的能力。混沌工程将帮助您确定需要改进的领域并激励您使您的系统更加可见,从而产生更好的遥测数据。
-
系统可靠性:混沌工程使公司能够创建可靠和容错的软件系统,同时增加团队对它们的信任。您的系统越可靠,您对它们按预期执行的能力就越有信心。
和测试一样吗?
一言以蔽之,没有。
失败测试着眼于单一情况并确定属性是否为真。像这样的测试以预定的方式破坏系统。结果通常是二元的,不会透露有关程序的任何其他信息,这对于了解问题的根本原因至关重要。
混沌工程的目的是在系统遭遇逆境时生成有关系统的新信息。人们可以更多地了解系统的行为、属性和性能,因为范围更广,结果是不可预测的。因此,它使我们能够更好地了解我们系统的局限性并采取行动。
进行混沌工程的过程
总的来说,混沌工程可以抽象为以下一组过程:
-
定义稳态假设:您应该从想象可能出错的地方开始。从失败的注入开始,并预测注入时会发生什么。
-
确认稳态并执行多个真实模拟:使用真实场景测试您的系统,观察它对不同压力源和事件的反应。
-
收集数据并监控仪表板:您必须评估系统的可靠性和可用性。使用与消费者成功或使用相关的关键绩效指标是理想的。我们想看看失败与我们的假设相比如何,因此我们将查看延迟和每秒请求数等内容。
-
应该解决的变化和问题:在进行实验之后,你应该对什么是有效的以及需要改变什么有一个很好的概念。我们现在可以预测什么会导致中断,以及什么会导致系统失败。
混沌工程原理
混沌原则宣言对此进行了详尽的描述,其中描述了混沌工程应解决的核心问题:
-
了解系统的正常状态:定义系统的稳定状态。任何混沌实验都使用系统的常规行为作为参考点。如果您了解系统处于健康状态时,您将更好地了解故障和故障的影响。
-
使用真实的错误和失败:所有实验都应该基于合理和现实的设置。当现实生活中的故障被注入时,哪些流程和技术需要升级就变得很清楚了。
-
生产级测试:只有在生产环境中运行测试,您才能看到中断如何影响系统。如果您的团队很少或根本没有混乱测试的经验,请允许他们在开发环境中进行试验。生产环境准备好后,进行测试。
4.控制爆炸半径:混沌测试的爆炸半径应始终保持尽可能小。由于这些测试是在现场环境中进行的,因此它们可能会对最终用户产生影响。
- 自动化混沌:混沌实验的自动化程度可能与您的 CI/CD 管道相同。持续的混乱使您的团队能够不断改进当前和未来的系统。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--8fZXby1b--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/mvqfixjc9igak8vza0bt.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--8fZXby1b--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/mvqfixjc9igak8vza0bt.png)
云原生混沌工程简介
企业热爱云:公司约三分之一的 IT 预算用于云服务,全球公共云计算市场将在 2021 年超过 3300 亿美元。向云原生软件产品的突破性转变需要辅以合适的工具,以确保它们能够抵御生产中可能出现的所有不利情况。
进入云原生混沌工程,两全其美。从本质上讲,这一切都是关于以云原生或 Kubernetes 优先的方式执行混沌工程。有四个主要原则定义了混沌工程工具或框架的云原生方式:
-
混沌管理的 CRD:为了协调 Kubernetes 上的混沌,框架应该明确定义 CRD。这些 CRD 提供标准 API,用于在大规模生产系统中配置和管理混乱。这些是构成混乱的工作流编排系统的元素。
-
开源:为了实现更大的社区参与和审查,框架必须在 Apache License 2.0 下完全开源。迁移到 Kubernetes 平台的应用程序数量不计其数。只有 Open Chaos 模型才能蓬勃发展并在如此广泛的范围内获得必要的采用。
-
可扩展和可插拔:该框架应该与大量现有的云原生应用程序集成,本质上构建为一个组件,可以轻松插入应用程序中的混沌工程,也可以轻松插入。
-
广泛的社区采用:混乱将针对众所周知的基础设施(如 Kubernetes)、应用程序(如数据库)以及基础设施组件(如存储和网络)进行。这些混沌实验可以再次使用,大型社区可以帮助识别和贡献更多的高价值场景。因此,混沌工程系统应该有一个中心枢纽或锻造中心,可以共享开源混沌实验并可以进行基于代码的协作。
LitmusChaos 是一个适用于 Kubernetes 的云原生混沌工程框架,它满足上面列出的所有四个标准。
[!.s3.amazonaws.com/uploads/articles/enowfqhju80euqy5ghni.jpeg)
鸟瞰LitmusChaos
什么是石蕊
Litmus 是用于进行云原生混沌工程的工具集。它可以帮助开发人员和 SRE 在 DevOps 管道的不同阶段(如开发、CI/CD 和生产中)自动化混沌实验。修复弱点可以提高系统的弹性。
Litmus 采用“Kubernetes-native”方法,通过自定义资源以声明性方式定义混沌意图。它将 Kubernetes 混沌实验大致定义为两类:应用程序或 pod 级别的混沌实验和平台或基础设施级别的混沌实验。前者包括pod-delete、container-kill、pod-cpu-hog、pod-network-loss等,后者包括node-drain、disk-loss、node-cpu-hog等。在项目级别的 Apache 许可证 2.0 许可证下。
在我们了解 Litmus 的架构之前,让我们了解一些术语:
-
混沌实验:混沌实验是 Litmus 架构的基石。用户可以通过从免费提供的混沌实验中进行选择或创建新的实验来开发所需的混沌工作流程。
-
混沌工作流程:混沌工作流程不仅仅是混沌实验。它帮助用户定义预期结果、观察结果、分析整体系统行为,并决定是否需要更改系统以提高弹性。对于普通的开发或运营团队,LitmusChaos 提供了设计、使用和管理混乱工作流所需的基础设施。 Litmus 的团队协作和 GitOps 功能极大地有助于协作控制团队或软件组织内的混乱流程。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--NxI_Pvie--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://loadsdev_880/up .s3 .amazonaws.com/uploads/articles/io0odhjvmbj12bizzr1t.jpeg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--NxI_Pvie--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://loadsdev_880/up .s3 .amazonaws.com/uploads/articles/io0odhjvmbj12bizzr1t.jpeg)
石蕊架构
石蕊成分可分为两部分:
1.门户
- 代理
Portal 是一组 Litmus 组件,它们充当跨云混沌控制平面 (WebUI),用于编排和观察代理上的混沌工作流。
Agent 是一组 Litmus 组件,它使用 K8s 集群组件上的混沌工作流来引发混沌。
门户组件
-
Litmus WebUI:Litmus UI提供了一个Web用户界面,用户可以在其中轻松构建和观察混沌工作流。这也充当了一个跨云混沌控制平面,即
-
Litmus Server:Litmus Server 充当中间件,用于处理来自用户界面的 API 请求,将配置和结果存储到数据库中。这也充当了在请求之间进行通信并将工作流调度到代理的接口。
-
Litmus DB:Litmus DB 充当混沌工作流程及其结果的配置存储。
代理组件
-
Chaos Operator:Chaos-Operator 监视 ChaosEngine CR,执行 CR 中提到的 Chaos-Experiments。 Chaos-Operator 是命名空间范围的。默认情况下,它在
litmus命名空间中运行。 -
CRD:安装过程中,Kubernetes集群上安装了以下三个CRD:
chaosexperiments.litmuschaos.io、chaosengines.litmuschaos.io、chaosresults.litmuschaos.io。 -
Chaos Experiment:Chaos Experiment 是一个 CR,在 Chaos Hub 上以 YAML 文件的形式提供。
-
Chaos Engine:ChaosEngine CR 将实验连接到应用程序。用户必须通过提供应用标签和实验以及 CR 来构建 ChaosEngine YAML。
-
Chaos Results:具有命名空间范围的 ChaosExperiment 的结果存储在 ChaosResult 资源中。实验本身在运行时创建或更新它。它包含关键信息,例如 ChaosEngine 参考、实验状态、实验结果(完成时)和关键应用程序/结果属性。它也可以用来收集指标。
-
Chaos Probes:Litmus 探针是可插入的测试,可以为 ChaosEngine 中的任何混沌实验定义。这些检查由实验 pod 基于它们定义的模式执行,并且它们的成功用于确定实验的判断(以及标准的“内置”检查)。
-
Chaos Exporter:如果需要,可以将指标导出到 Prometheus 数据库。 Prometheus 指标端点由 Chaos-Exporter 实现。
-
Subscriber:Subscriber是Agent端的一个组件,它与Litmus Server组件通信,获取Chaos进程数据并返回结果。
演示:在 Kubernetes 部署上使用自定义混沌工作流执行 pod-delete 实验
让我们通过一个非常简单的混沌实验来了解 Litmus:pod-delete实验。本质上,我们想看看我们在上一篇博客中的 Kubernetes 部署是否能够抵御意外 pod 删除事件。
这就是我们要做的;首先,我们将安装 Litmus,然后定义自定义工作流程,最后分析实验结果。很简单,不是吗?
可以使用kubectl get deployments命令查看我们的应用部署:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--YIuzX9jg--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/i0813rggh4sqa19f9qrn.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--YIuzX9jg--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/i0813rggh4sqa19f9qrn.png)
并且可以使用kubectl get pods查看关联的 pod:
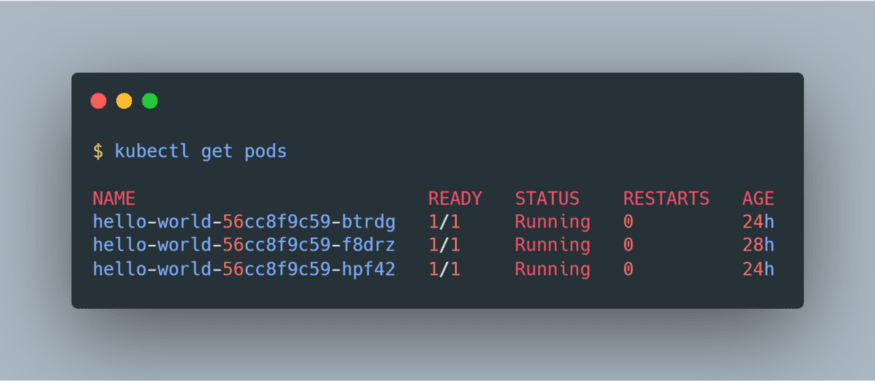 -uploads.s3 .amazonaws.com/uploads/articles/02d5mgjiivdajdnwo0bt.png)
-uploads.s3 .amazonaws.com/uploads/articles/02d5mgjiivdajdnwo0bt.png)
在安装 Litmus 之前,让我们检查一下先决条件:
-
Kubernetes 1.15 或更高版本
-
20GB的持久卷(推荐)
-
Helm3 或 Kubectl
一旦我们熟悉这些,让我们按照安装步骤进行操作。 Litmus 可以使用 Helm 或 Kubectl 安装。让我们尝试使用 Helm 安装它:
第 1 步:在 Kubernetes 中创建 Litmus 命名空间
Litmus 安装在 litmus 命名空间中。所以让我们使用命令创建命名空间:kubectl create namespace litmus
第 2 步:添加 Litmus Helm 图表
使用以下命令克隆石蕊仓库并移至克隆目录:git clone https://github.com/litmuschaos/litmus-helm && cd litmus-helm
第 3 步:安装 Litmus
helm chart 将安装核心服务和门户运行所需的所有 CRD、所需的服务帐户配置和 chaos-operator。使用命令helm install litmuschaos — namespace litmus ./charts/litmus-2–0–0-beta/
就是这样,你们都准备好使用 Litmus 了!您可以通过使用kubectl get all -n litmus命令查看安装在litmus命名空间下的所有资源来验证安装:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--cdzQJ0DD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cwdev_880/https://loads_dev_880/up s3。 .amazonaws.com/uploads/articles/lyt7ro8t0z2pacsglnqg.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--cdzQJ0DD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cwdev_880/https://loads_dev_880/up s3。 .amazonaws.com/uploads/articles/lyt7ro8t0z2pacsglnqg.png)
所有资源可能需要一段时间才能准备好,最终您会看到如上图所示的内容。在这里,我们可以观察到我们运行了三个 pod:litmus-frontend、litmus-backend和mongo。如前所述,它们分别包括 Litmus WebUI、Litmus Server 和 Litmus DB。
我们还为我们的应用程序提供了三个服务,即litmusportal-frontend-service、litmusportal-backend-service和mongo-service。这些服务维护我们之前看到的 Pod 的端点。
这些 pod 是使用两个部署创建的,即litmusportal-frontend和litmusportal-backend,它们还负责指定相同的副本集。
最后,作为有状态资源的 Mongo DB 数据库使用名为mongo的 statefulset 来持久化数据库中包含的数据,即使mongopod 死掉并重新启动也是如此。
一旦所有这些资源都准备好,我们就可以进入 Litmus 门户。为此,我们将尝试访问 NodePort 服务litmusportal-frontend-service。在我的机器中分配给litmusportal-frontend-service的 nodePort 具有9091:30628的映射,其中9091是指定的targetPort,而30628是分配的nodePort。
如果您使用 Minikube,您可以将您选择的任何未使用的端口端口转发到litmusportal-frontend-service,以便在该端口访问它。例如,如果我希望在3000端口访问litmusportal-frontend-service,我会使用命令kubectl port-forward svc/litmusportal-frontend-service 3000:9091 -n litmus。完成后,只需访问http://127.0.0.1:3000的 Litmus 门户。
如果您使用任何其他 Kubernetes 平台,您可以直接访问位于nodePort的 Litmus 门户,前提是您有防火墙规则允许在该端口进入。例如,我有一个nodePort的30628,因此我可以在http://127.0.0.1:30628直接访问 Litmus 门户。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--Wd1h0qH4--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/8g2vl1qokjowgyn1vunu.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Wd1h0qH4--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/8g2vl1qokjowgyn1vunu.png)
默认用户名是admin,默认密码是litmus。登录后,系统会提示您输入新密码。完成后,您会发现自己在仪表板中:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--w_cOuif2--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/ikzyxc3bfuygckop5y7n.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--w_cOuif2--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/ikzyxc3bfuygckop5y7n.png)
让我们快速浏览一下门户。您可以在仪表板中查看当前正在执行或之前已执行的不同工作流、连接到门户的代理数量以及项目和协作邀请的数量。在 Workflows 中,您将能够详细了解正在运行和过去的工作流,以及它们各自的分析和日志。 ChaosHubs 是您可以访问混沌实验的地方,默认情况下,您可以访问 Litmus 的 ChaosHub 下列出的所有实验,但您也可以使用自己的集线器进行设置。在分析下,您将能够使用图表对混沌工作流程的不同方面进行生动的分析。最后,设置允许您修改个人信息、使用 GitOps 自动化工作流程等。
让我们继续为我们的 pod-delete 实验创建工作流。在 Dashboard 中,单击 Schedule a Workflow 按钮并选择 self-agent,因为我们的目标应用程序部署在同一个 Kubernetes 集群中。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--DROD6TZ1--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/0v3q9udr3y3u5wbyo0sz.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--DROD6TZ1--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/0v3q9udr3y3u5wbyo0sz.png)
点击下一步。选择“使用 MyHub 中的实验创建新工作流”,然后从下拉列表中选择“Chaos Hub”。这是因为我们在这里尝试执行的实验,即 pod-delete 实验,是 Chaos Hub 的一部分,我们可以直接使用它,而无需自己定义。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--05DVVS3S--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_to880/https://devloads/.s3。 amazonaws.com/uploads/articles/xvixohrti6j000wpx68n.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--05DVVS3S--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_to880/https://devloads/.s3。 amazonaws.com/uploads/articles/xvixohrti6j000wpx68n.png)
点击下一步。在工作流程设置下,将您的工作流程重命名为您选择的任何名称。不要更改命名空间,因为我们的 Litmus 安装应该只使用litmus命名空间。添加您自己选择的描述。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--p3Z9oMXF--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw/https://dev..s3。 amazonaws.com/uploads/articles/27sjlyuojr5xcohznsh0.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--p3Z9oMXF--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw/https://dev..s3。 amazonaws.com/uploads/articles/27sjlyuojr5xcohznsh0.png)
点击下一步。目前,在 Tune Workflow 中,您只能查看流程图中列出的一个步骤,即“install-chaos-experiments”。
[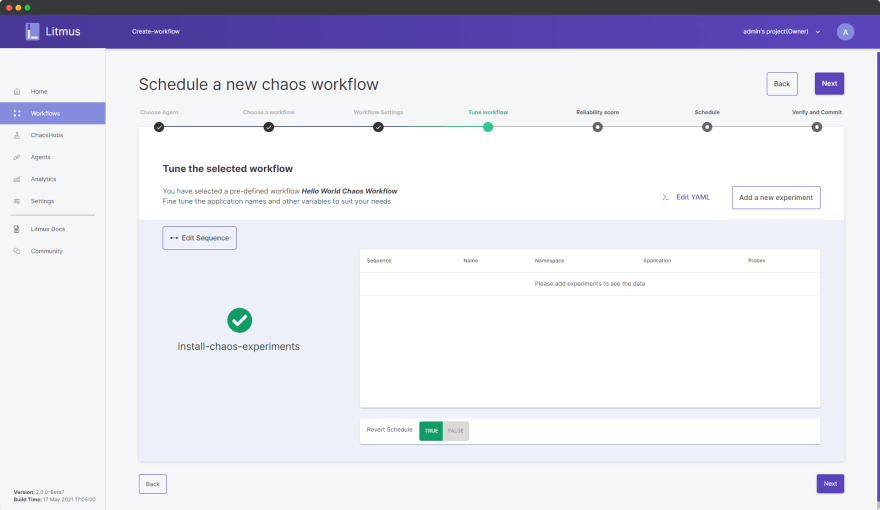 ](https://res.cloudinary.com/practicaldev/image/fetch/s--KV93V-CN--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev .-to-uploads.s3.amazonaws.com/uploads/articles/092axjpr07l9ekd5wvik.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--KV93V-CN--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev .-to-uploads.s3.amazonaws.com/uploads/articles/092axjpr07l9ekd5wvik.png)
单击添加新实验并选择通用/pod-delete。
[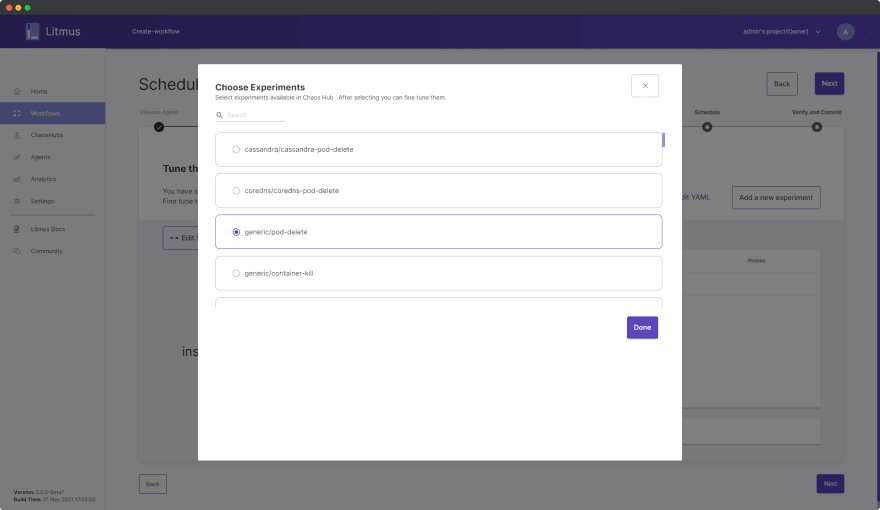 ](https://res.cloudinary.com/practicaldev/image/fetch/s--mReTsZHB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/2w53693b6i9nlg6bhe5d.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--mReTsZHB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/2w53693b6i9nlg6bhe5d.png)
单击完成。
[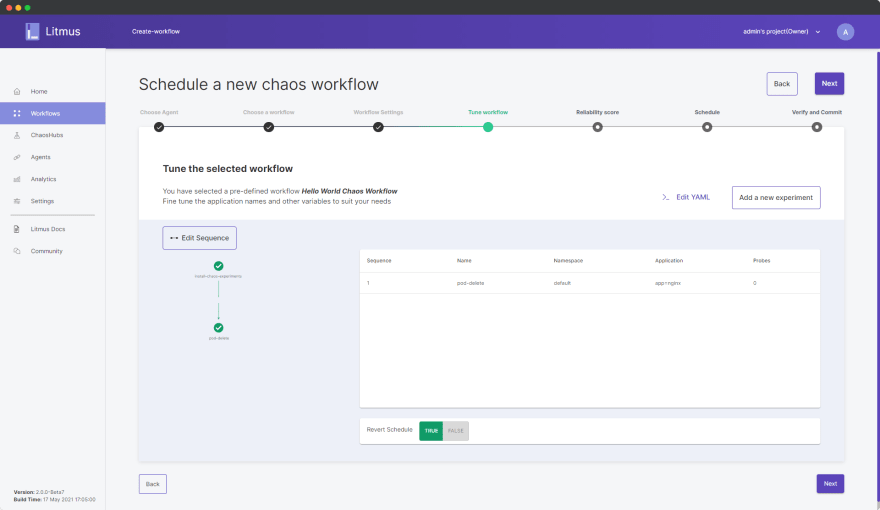 ](https://res.cloudinary.com/practicaldev/image/fetch/s--FOXUSH5D--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/sqnpxhnjtxp10dvqiz2i.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--FOXUSH5D--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/sqnpxhnjtxp10dvqiz2i.png)
如您所见,现在在流程图中列出了第二步“pod-delete”。尽管出于本演示的目的,我们只使用一个实验来保持工作流程的简单性,但可以通过按照所需顺序添加更多实验来设计整个工作流程。就这么简单!
现在,我们将指定执行混沌工作流的目标部署。单击 Edit YAML 并向下滚动到编辑器中的第 134 行。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--Ts8692Bs--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/cizl54vao1tbxyiwqxve.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Ts8692Bs--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/cizl54vao1tbxyiwqxve.png)
在这里,我们需要通过覆盖默认值app=nginx来指定我们的 hello-world 应用程序的appLabel。要检查我们部署的标签,我们可以使用kubectl get deployments --show-labels命令:
[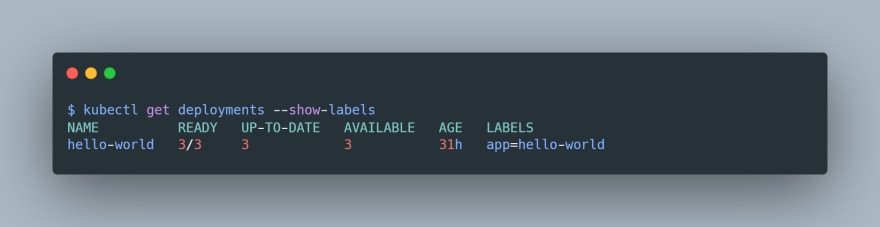 ](https://res.cloudinary.com/practicaldev/image/fetch/s--JzfYkb4s--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/8ei2mu7iz16trjf4fijl.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--JzfYkb4s--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/8ei2mu7iz16trjf4fijl.png)
我们部署的标签是app=hello-world,所以我们只需将app=nginx替换为app=hello-world。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--2sJoqPQ6--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/h9f1yf9esxs1hzdzz5st.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--2sJoqPQ6--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/h9f1yf9esxs1hzdzz5st.png)
单击保存更改。返回门户,将 Revert Schedule 保持为 TRUE。这确保了在工作流执行期间对系统所做的所有更改都将在工作流完成后恢复。点击下一步。
在可靠性分数中,我们可以为每个实验添加一个介于 1 到 10 之间的数字分数。 Litmus 将在工作流结束时计算弹性分数时简单地使用此权重。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--eQi69bRj--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/2i5foud53topw8g4opto.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--eQi69bRj--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/2i5foud53topw8g4opto.png)
点击下一步。在 Schedule 内部,我们可以安排我们的工作流以确定的频率执行,或者我们可以简单地安排它立即执行。选择“立即安排”。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--xHHb39fg--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2https://dev_880-to/2Cw_880 -uploads.s3.amazonaws.com/uploads/articles/pyzfx9jt0lho9an7re3x.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--xHHb39fg--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2https://dev_880-to/2Cw_880 -uploads.s3.amazonaws.com/uploads/articles/pyzfx9jt0lho9an7re3x.png)
点击下一步。在验证和提交中,您可以在最终执行工作流之前查看工作流详细信息并根据需要进行更改。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--m7gQF5y9--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/ah886brxa39ewmsxk2zs.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--m7gQF5y9--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/ah886brxa39ewmsxk2zs.png)
对配置满意后,单击完成。您现在已经成功启动了混沌工作流:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--l_fqYBQa--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/nk547apz0ixh65n3wp1a.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--l_fqYBQa--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/nk547apz0ixh65n3wp1a.png)
单击 Go to Worklow 并从 Workflows 仪表板中选择当前正在运行的工作流。您可以查看工作流的图形视图,因为它正在我们部署的应用程序上主动执行 pod-delete 实验。
[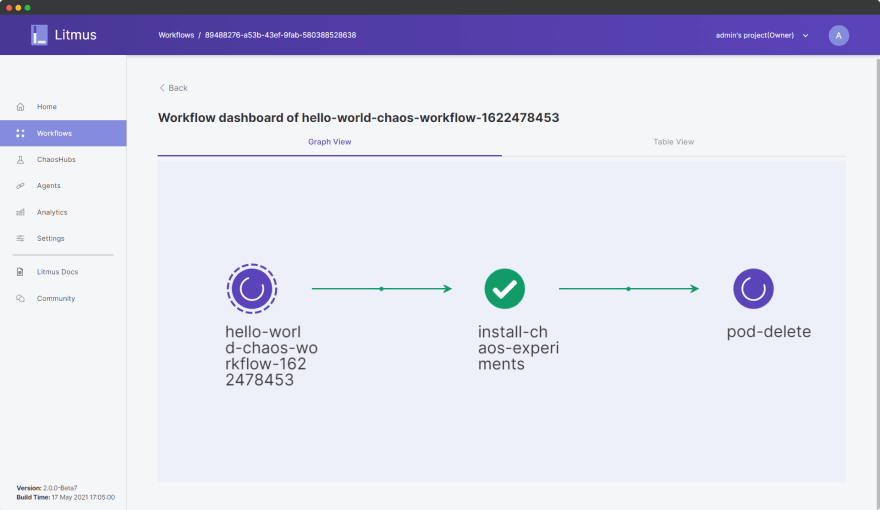 ](https://res.cloudinary.com/practicaldev/image/fetch/s--r-RJIWHB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev_880/- uploads.s3.amazonaws.com/uploads/articles/pzqgem795o3s2wsnr8gk.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--r-RJIWHB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev_880/- uploads.s3.amazonaws.com/uploads/articles/pzqgem795o3s2wsnr8gk.png)
实际上,这个实验会首先在集群中安装混沌实验资源,导致我们应用部署中的三个 pod 中的一个被随机选择和删除,最后进行混沌实验资源的清理。
因此,应用程序部署预计将启动一个新的 pod 来替换被强制删除的 pod,以使实验成功。否则,如果一个新的 pod 无法启动,那么我们的系统肯定是没有弹性的。
几分钟后,您将能够看到实验已成功完成:
[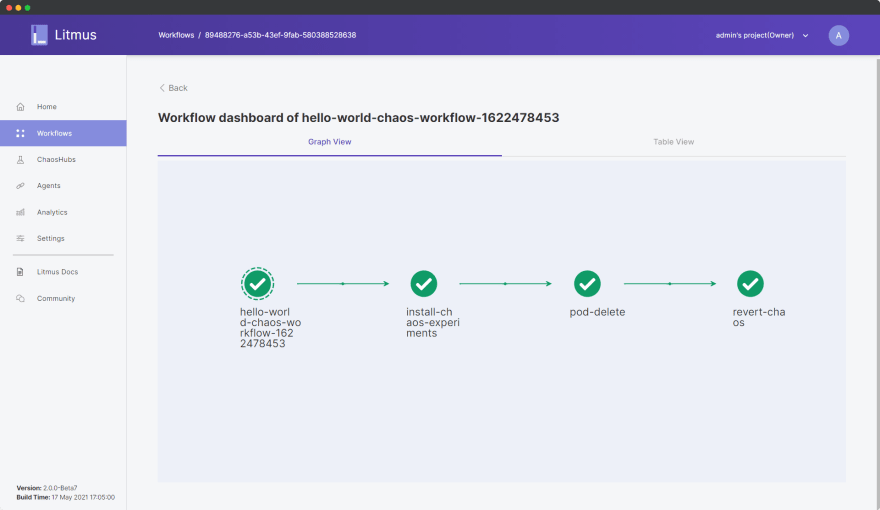 ](https://res.cloudinary.com/practicaldev/image/fetch/s--CzToOjEq--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/5t9mo83ikdo05xvjrm24.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--CzToOjEq--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/5t9mo83ikdo05xvjrm24.png)
实验的所有步骤都是成功的,即使在强制删除 pod 的情况下,我们的系统也能够成功应对。我们可以在表格视图中进一步分析有关实验的详细信息:
[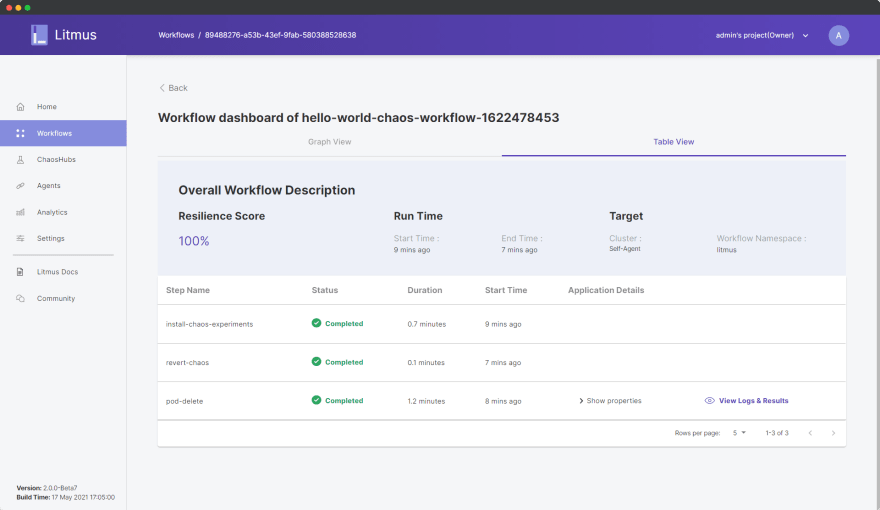 ](https://res.cloudinary.com/practicaldev/image/fetch/s--mXCpR1ku--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/cqnx579bhyp3shlsfssd.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--mXCpR1ku--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/cqnx579bhyp3shlsfssd.png)
正如我们所见,我们获得了 100% 的弹性分数,我们实验的其他信息也在这里可见。此外,我们可以分析工作流分析,以更好地了解工作流对我们系统的影响。单击返回,然后在工作流仪表板中,单击选项省略号图标:
[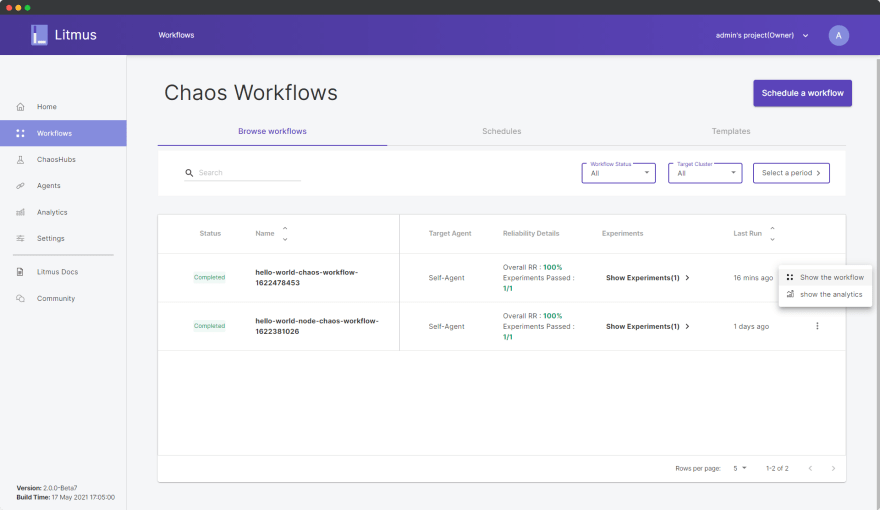 ](https://res.cloudinary.com/practicaldev/image/fetch/s--uWjMrMxE--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/jawl50snh3y2yr3x46ot.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--uWjMrMxE--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/jawl50snh3y2yr3x46ot.png)
选择显示分析。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--Nj6WZ7Wr--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/fl1ybqpannidufkcb5x9.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Nj6WZ7Wr--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/fl1ybqpannidufkcb5x9.png)
分析图显示了混沌实验的序列、弹性分数和其他参数在工作流执行时间线上的状态。
在这个博客系列的结尾,让我们欣赏一下我们是如何从容器到混沌工程的,从学习如何 Dockerize 一个 Node.js 应用程序开始,使用 Kubernetes 部署我们的 Docker 容器,最后使用 LitmusChaos 执行一个 pod - 删除我们应用程序的混沌实验。
再次欢迎来到容器和混沌工程的世界。来加入我的Litmus 社区,为每个人开发混沌工程贡献自己的一份力量。通过 KubernetesSlack频道(查找#litmus 频道)随时了解最新的 Litmus 趋势。
不要忘记与您认为可能从中受益的人分享这些资源。谢谢你。 🙏

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0


 已为社区贡献4375条内容
已为社区贡献4375条内容

所有评论(0)