




一、摘要
简单介绍神经图灵机。
二、引入
同facebookAI团队的主菜记忆网络,Google DeepMind团队做出了神经图灵机模型。
2014年提出Neural Turing Machines [2],开篇之作。(引用数:565)
2015年提出Neural Random Access Machines [3],神经网络随机存取机。(引用数:45)
2015年提出Learning to Transduce with Unbounded Memory [4],使用诸如栈或(双端)队列结构的连续版本。(引用数:134)
2016年提出Neural GPUs Learn Algorithms [5],GPU版本。(引用数:106)
2016年提出Differentiable Neural Computer [9],改善了NTM的记忆读写机制。(引用数:528)
图灵机是现代计算理论的基础,简单来说,图灵机是对于人类使用纸笔进行数学计算的一种模拟。图灵机假设,只要有一个能够读写的无限长纸带和一个可以在纸带上自由移动的读写头,就能够模拟人类对所有可计算数的计算。
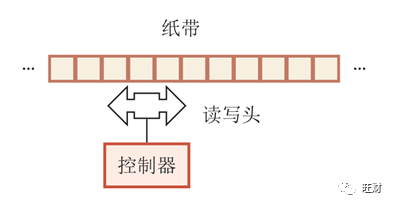
图灵机最有趣的地方在于其对“所有可计算数”的定义[1]:
图灵假设:
人类的记忆是有限的
那么我们总能找到一个足够大的集合M,认为人类所有的记忆都在这个M中
注意图灵研究早期,这个M的呈现形式是数组(直到今天编程语言还以“堆栈”的形式来表示M),而这种结构下可表示空间为其长度N
而我们现在的深度学习技术则可以将N延伸到多维中,以向量的形式来区分,那么可表示空间就到了N×N×N×...,动摇了基本盘
物理世界是有限的
那么我们可以定义一个足够大的集合S,认为世界的所有客观存在都在S中
早期我们使用的是二进制的编码,从8位机到如今的64位,数字表示范围急剧扩大,但是二进制编码的增量本身也是线性的
现在我们的向量空间是可以把这个编码空间的增量方式延伸到高维空间中,可表示的数据范围大幅增长
人类的操作是有限的
那么我们总可以定义人类的操作集合O,认为人类所有的操作都在O中
这个思路一直到今天,只不过我们对O进行了分层,底层是处理器的指令集,高一层是编程语言,最顶层是程序员创造的函数
和M不同的是,我们能够操作的O只有最顶层的创造函数
事实上,O是受限于symbol的
可计算数
图灵的定义是:所有小数可以用有限次方法计算的数字+一些特殊的数字如π和e
比如使用纸带读写头计算0101010101...数列[1],定义:
m-config,M包括:
b
c
e
f
symbol,S包括:
None:当symbol是None时,可以理解第三列和第四列的行为适用于任何扫描的symbol
0
1
operations,O包括:
L:向左移动
R:向右移动
E:删掉被扫描的符号
P:打印
那么计算可以定义为:

注意这个计算和纸带无关和状态有关(有记忆),即便纸带是一个空纸带,也能正确输出
如果(与§1中的描述相反)我们允许字母L、R在operations列中出现多次,可以简化表为:

注意这样计算就和读写头的状态无关(即无记忆),但和上一步输出到纸带上的值有关
这两种实现模式意味着,记忆和现实在解决问题中能够提供同等的作用。这意味着现实中实现的时候我们可以通过大量的现实来弱化对记忆的需求,这也是早期计算机在简陋的硬件条件下完成复杂计算的依据。而同样的,这种情况随着多维向量空间对记忆的表达的巨大冗余度的出现发生了改变。
所有今天的计算本质上都是这个模型的复杂化,因为根据图灵机的特点图灵定义了图灵完备的概念:
在可计算性理论里,如果一系列操作数据的规则(如指令集、编程语言、细胞自动机)可以用来模拟单带图灵机,那么它是图灵完全的。(来自维基百科[7])
事实上,进入深度学习的空间后,第一个尝试图灵机的模型是RNN。我一开始接触神经网络的时候认为RNN是CNN的序列化模型,后来发现RNN并不是CNN概念的延续,而是图灵机概念的延续,RNN的上代模型可以和HMM进行比较,甚至从理论上讲,我们能够训练RNN实现所有C语言的程序[8]。这一特点我们甚至能从LSTM和GRU的实现看出来,虽然这两个模型都进行了诸多改进,但依然保留了一个状态参数。
但是至今我们似乎还没有看到RNN编程语言的出现,不出意外的话,神经图灵机也许是这个领域的一个尝试?
三、神经图灵机
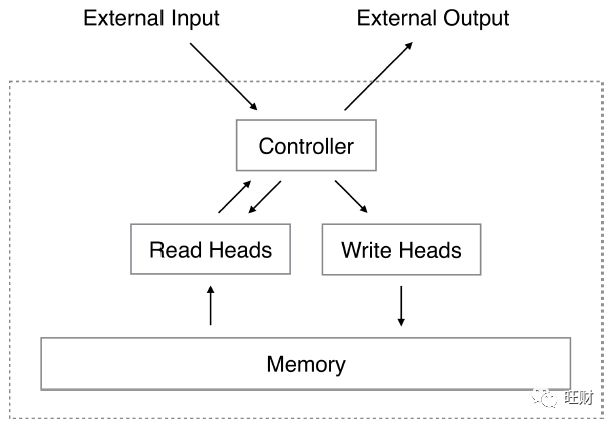
神经图灵机(NTM)结构包括两个基本组件:
Controller和Memory。
图1展示了NTM体系结构的高级图。
与大多数神经网络一样,控制器通过输入和输出向量与外部世界交互。
与标准网络不同,它还使用选择性读写操作与内存矩阵交互。
与图灵机类似,我们将参数化这些操作的网络输出称为“头”。
“至关重要的是,建筑的每一个组件都是可区分的,这使得用梯度下降训练变得很简单。”
我们通过定义“模糊”读写操作来实现这一点,这些操作或多或少地与内存中的所有元素交互(而不是像普通的图灵机器或数字计算机那样处理单个元素)。
模糊的程度由注意力“集中”机制决定,该机制限制每个读写操作与内存的一小部分交互,而忽略其余部分。
由于与内存的交互非常稀疏,NTM倾向于存储无干扰的数据。
进入注意焦点的记忆位置由头部发出的特殊输出决定。
这些输出定义了对内存矩阵(称为内存“位置”)中的行进行标准化加权。
每个权重(每个读或写头一个权重)定义头在每个位置读或写的程度。
因此,一个头可以敏锐地注意到一个位置的记忆,也可以微弱地注意到许多位置的记忆。
读:
M_t 是在 t 时候 N×M 记忆矩阵。
N 是记忆位置的总数
M 是每一个位置的向量长度
w_t 是在 t 时刻的N个位置的权重参数,由于所有的权重都需要归一化,所以 w_t 需要满足
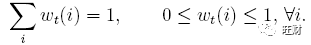
那么长为M的读向量 r_t 被定义为对于记忆中行向量 M_t(i) 凸合并:
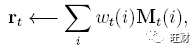
注意,在这个公式中记忆和权重都是可微的。
写:
从LSTM的输入门和遗忘门获得灵感,我们把每一次写分解为两个阶段:
先擦除
后增加
定义在时刻 t 时候写头的权重是 w_t ,且擦除向量是 e_t
因为M的参数都是0-1的值,那么基于 M_t-1 进行更新的操作定义为:
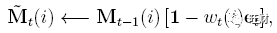
公式中1是所有1-s的行向量,使用点乘和记忆位置相乘。
因此,只有当位置权重和擦除权重均为1时,它们的乘积为1,M_t (i) 重置为零
如果位置权重和擦除权重为零,则 M_t (i) 保持不变。
当出现多个写头时,可以按任何顺序执行擦除操作,因为乘法是可交换的。
同样,由多个头执行加法的顺序无关紧要。
所有写头的合并擦除和添加操作在t时刻生成内存的最终内容。
由于擦除和添加都是可微的,所以复合写操作也是可微的。
注意,擦除向量和添加向量都有M个独立的组件,允许对每个内存位置中的哪些元素进行细粒度控制。
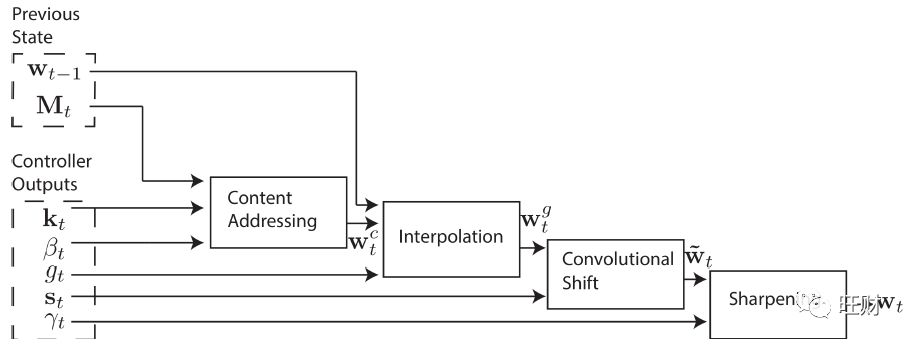
寻址机制
虽然我们现在已经展示了读写方程,但我们还没有描述权重是如何产生的。
这些权重是通过将两种寻址机制与互补的设施相结合而产生的。
第一种机制是“基于内容的寻址”,它基于当前值和控制器发出的值之间的相似性来关注位置。
这与Hopfield网络的内容寻址有关(Hopfield, 1982)。
基于内容寻址的优点是检索简单,只需要控制器生成对存储数据的一部分的近似,然后将其与内存进行比较,以生成准确的存储值。
然而,并不是所有的问题都适合基于内容的寻址。
在某些任务中,变量的内容是任意的,但是变量仍然需要一个可识别的名称或地址。
算术问题属于这一类:
变量x和变量y可以取任意两个值,但过程 f(x,y) = x × y。
该任务的控制器可以获取变量x和y的值,将它们存储在不同的地址中,然后检索它们并执行乘法算法。
在本例中,变量是根据位置而不是内容来寻址的,我们将这种寻址形式称为“基于位置的寻址”。
基于内容的寻址严格来说比基于位置的寻址更通用,因为内存位置的内容可以包含其中的位置信息。
然而,在我们的实验中,将基于位置的寻址作为一种基本操作被证明对于某些形式的一般化是必不可少的,因此我们同时使用了这两种机制。
图2给出了整个寻址系统的流程图,显示了读写时构造加权向量的操作顺序。
内容寻址
内容寻址下,无论是读头还是写头都要先生产一个长度M的关键向量 k_t 和每个向量 M_t 使用函数 K[·,·] 计算相似度。
这个 k_t 是根据输入数据计算得来的,用户可以自定义求 k_t 的方案
内容寻址基于相似度和相似度权重 β_t 的乘积计算出一个归一化的权重 w^c_t (softmax)
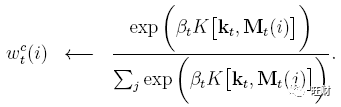
在本文中,相似度使用的是平方距离
位置寻址
基于位置的寻址机制的设计是为了方便跨内存位置的简单迭代和随机访问跳转。
它通过实现权重的旋转移位来实现这一点。
例如,如果当前权重完全集中于一个位置,则旋转1会将焦点转移到下一个位置。
负的偏移会使权重向相反的方向移动。
旋转前,每个磁头在(0,1)位置。
g的值用于混合上一步计算产生的 w_t-1 和根据本次内容系统产生的 w^c_t,定义为 w^g_t

如果 g=0,则完全忽略内容权重,使用前一个时间步骤的权重。相反,如果 g=1,则忽略前一个迭代的权重,系统应用基于内容的寻址。
插值后,每个磁头发出一个移位加权 s_t,s_t 定义了允许整数移位的正态分布。
例如,如果允许在-1和1之间移动,st有三个元素对应于执行-1、0和1移动的程度。
定义移位权重的最简单方法是使用附加到控制器上的适当大小的softmax层。
我们还试验了另一种技术,其中控制器发出一个标量,该标量被解释为宽度的下界,即移位上的均匀分布。
例如,如果移位标量是6.7,那么 s_t(6) = 0.3, s_t(7) = 0.7,其余的 s_t 为0。
如果我们将 N 个内存位置从 0 索引到 N-1,s_t 对 w^g_t 的旋转可以表示为如下的循环卷积:
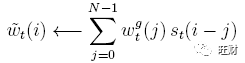
上式中的卷积运算,如果移位加权不明显,会导致权重随时间的泄漏或分散。
例如,如果 -1, 0 和 1 的偏移量的权值分别为 0.1, 0.8 和 0.1
那么旋转将把一个集中在一个点的权值转换为一个在三个点上稍微模糊的权值
为了解决这一问题,每个磁头再计算一个标量 γ_t ≥ 1,其效果是锐化最终权重:
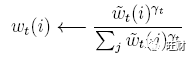
加权插值与基于内容和位置的寻址相结合的寻址系统可以在三种互补模式下运行:
第一,可以由内容系统选择权重,而不需要位置系统进行任何修改。
第二,可以选择由内容寻址系统产生的权重,然后进行移位。
这允许焦点跳转到内容访问的地址旁边的位置,但不能跳转到该地址上;在计算术语中,这允许头查找一个连续的数据块,然后访问该块中的特定元素。
第三,可以在不需要任何来自基于内容寻址系统的输入的情况下旋转前一个时间步长的权重。
这允许权重通过在每个时间步进相同的距离迭代一系列地址。
控制器网络
上面描述的NTM体系结构有几个自由参数,包括内存大小、读写头的数量和允许的位置偏移范围。
但也许最重要的架构选择是用作控制器的神经网络类型。
特别是,必须决定是使用递归网络还是前馈网络。
像LSTM这样的递归控制器有自己的内部内存,可以补充矩阵中较大的内存。
如果将控制器与数字计算机中的中央处理单元(尽管使用自适应指令而不是预定义指令)和内存矩阵与RAM进行比较,则递归控制器的隐藏激活类似于处理器中的寄存器,它们允许控制器跨多个操作时间步骤混合信息。
另一方面,前馈控制器可以通过每一步在内存中相同的位置读写来模拟递归网络。
此外,前馈控制器通常赋予网络运行更大的透明度,因为从内存矩阵读写的模式通常比RNN的内部状态更容易解释。
然而,前馈控制器的一个限制是并发读和写头的数量对NTM能够执行的计算类型造成了瓶颈。
对于单个读头,它在每个时间步长只能对单个内存向量执行一元变换,对于两个读头,它可以执行二进制向量变换,依此类推。
递归控制器可以在内部存储以前的时间步长的读向量,因此不受此限制。
四、实验
本节介绍一组简单算法任务的初步实验,如复制和排序数据序列。
我们的目标不仅是建立NTM能够解决这些问题,而且它能够通过学习紧凑的内部程序来解决这些问题。
这些解决方案的特点是,它们的普遍性远远超出了培训数据的范围。
例如,我们很想知道,一个经过训练复制长度不超过20的序列的网络,是否可以不经过进一步的训练就复制长度为100的序列。
在所有的实验中,我们比较了三种架构:
带前馈控制器的NTM
带LSTM控制器的NTM
标准LSTM网络
由于所有的任务都是情景性的,我们在每个输入序列的开始处重置了网络的动态状态。
对于LSTM网络,这意味着将之前的隐藏状态设置为一个学习偏差向量。
对于NTM,控制器的前一状态、前一读向量的值、内存的内容都重置为偏置值。
所有的任务都是带二进制目标的监督学习问题;所有网络均具有逻辑s形输出层,并采用交叉熵目标函数进行训练。
序列预测误差按每序列的位进行报告。
【复制】
输入:一串向量
输出:一串相同的向量
复制任务测试NTM是否能够存储和回忆一长串任意的信息。
该网络由随机二进制向量的输入序列和一个分隔符标志组成。
对于RNNs和其他动态体系结构来说,长时间的信息存储和访问一直存在问题。
我们特别感兴趣的是NTM是否能够比LSTM桥接更长的时间延迟。
这些网络被训练来复制8位随机向量的序列,其中序列长度被随机分配在1到20之间。
目标序列只是输入序列的副本(没有分隔符标志)。
请注意,当网络接收目标时,没有向它提供任何输入,以确保它在没有中间协助的情况下回顾整个序列。
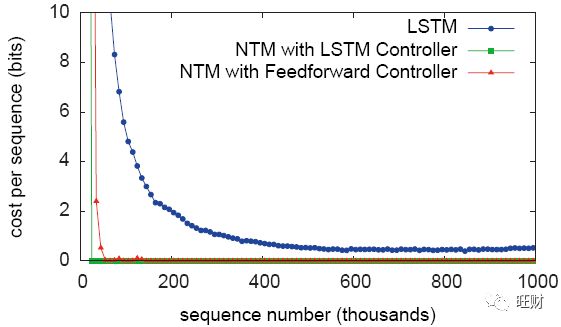
从图3可以看出,NTM(使用前馈控制器或LSTM控制器)的学习速度比单独使用LSTM要快得多,并且收敛到更低的成本。
NTM和LSTM学习曲线之间的差异非常显著,足以表明这两个模型在解决问题的方式上存在定性而非定量的差异。
我们还研究了网络泛化成比训练时更长的序列的能力(从训练误差可以明显看出,它们可以泛化成新的向量)。
前面的分析表明NTM不同于LSTM,它学习了某种形式的复制算法。
为了确定这个算法是什么,我们研究了控制器和内存之间的交互作用,如下图:
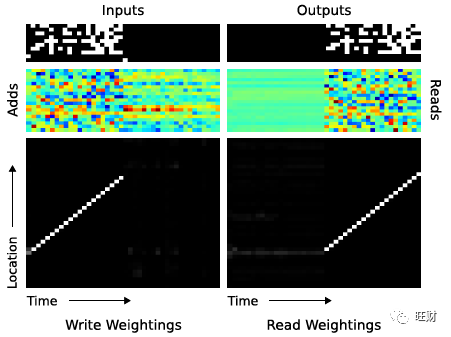
我们认为网络执行的操作序列可以用以下伪代码总结:

这本质上是人类程序员在低级编程语言中执行相同任务的方式。
在数据结构方面,我们可以说NTM已经学会了如何创建和迭代数组。
注意,该算法结合了基于内容的寻址(跳转到序列的开始)和基于位置的寻址(沿着序列移动)。
还需要注意的是,如果不能使用以前读写权重的相对变化(公式7),迭代就不能泛化为长序列,而且如果没有聚焦锐化机制(公式9),权重可能会随着时间的推移而失去精度。
【排序】
输入:一串key-value,-1≤key≤1,value是一个表示区分的向量
输出:一串按照key排序好的key-value
实验中称key为priority,value为inputs,如下图所示:

每个输入序列包含20个具有相应优先级的二进制向量,每个目标序列是输入序列中优先级最高的16个向量。
对NTM内存使用情况的检查使我们假设它使用优先级来确定每次写入的相对位置。
为了验证这一假设,我们拟合了一个线性函数,该函数优先考虑观察到的写入位置。
下图显示线性函数返回的位置与观察到的写位置非常匹配:
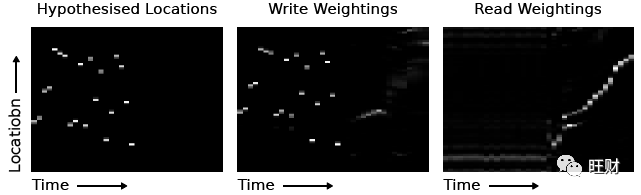
它还显示网络按递增的顺序从内存位置读取数据,从而遍历排序后的序列。
下图的学习曲线表明,在此任务上,前馈和LSTM控制器的NTM都明显优于LSTM:
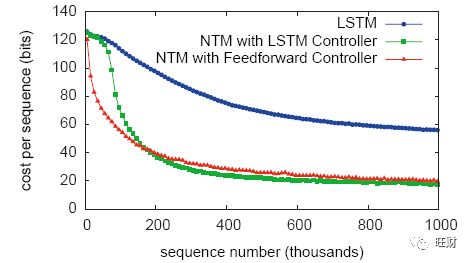
注意,在此任务上使用前馈控制器时,为了获得最佳性能,需要8个并行读和写头;这可能反映了仅使用一元向量操作对向量进行排序的难度。
五、总结
相比于图灵机本身,神经图灵机完全是对于计算过程的一种自学习,而且我们看到这种学习是无法人工干预的,这意味着在应用层面它和RNN是类似的。
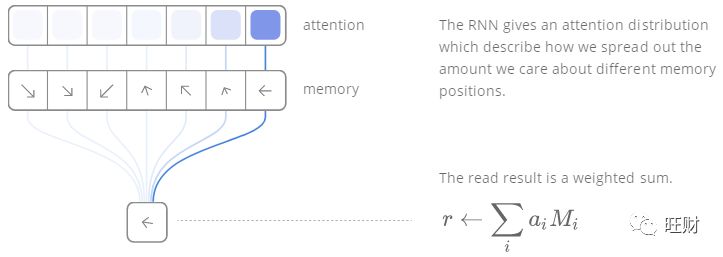
但是从原理上看,NTM最有趣的是训练读写权重中的两次寻址,我们注意到读写过程中的权重 w_t 是和时间相关的,并且和每个M一一对应,读是softmax这种多分类器读所有的memory[12]:
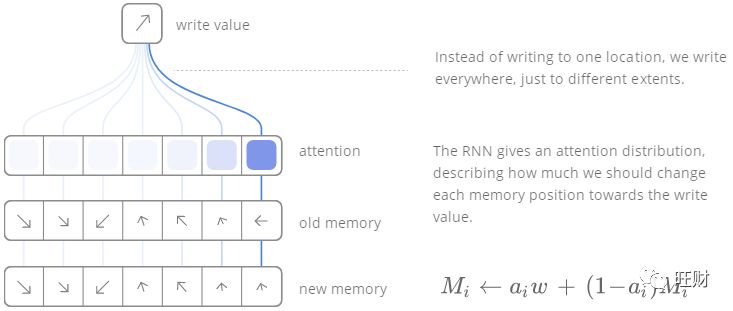
写是全部memory一起更新(注意这个图里的公式不正确,以上文从论文中截取的为准,但这个图在逻辑上是正确的)[12]:
对应传统图灵机,程序员设计代码(判断、跳步或循环)需要考虑执行时候的symbol和m-config,即便高级语言也是如此(大内存、小寄存器和单条执行的语句)。神经图灵机的M在训练的时候会更改,训练完成后M值固定(代码写好了),测试的时候,w值(寄存器)根据每次输入的值(程序语句)会不断更改。只不过人工代码种类较少,w值的空间相当大。
以下图来说明权重的更新过程[12]:
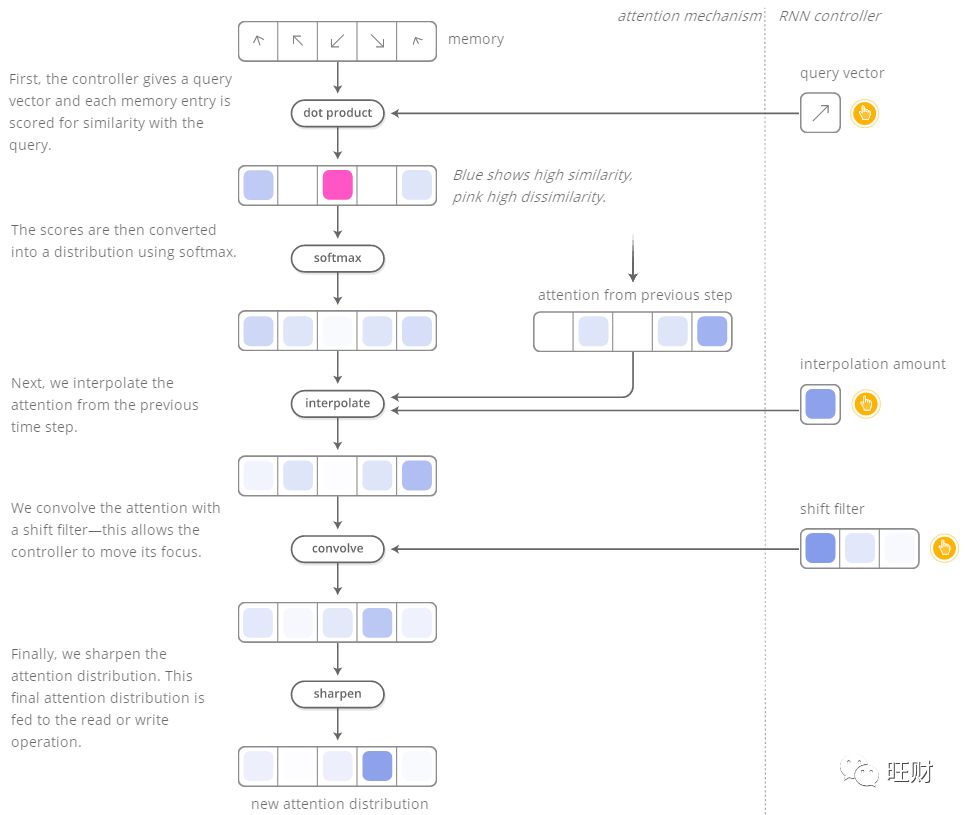
其中对于Interpolation插值和shift偏移的值的来源事实上这篇文章没有讲,在作者的另一篇文章中提到了[13],但来不及细看,通过代码[14]中的实现,发现这两个参数实际上是程序中写死的:

另外作者在文中信誓旦旦赌咒发誓自己的模型不是RNN,事实上还是有很多相似点的,关于这个模型我还有很多东西还是没搞明白,且待后续分解。
六、参考文献
[1] Turing, A. M. (1937). On computable numbers, with an application to the Entscheidungsproblem. Proceedings of the London mathematical society, 2(1), 230-265.
[2] Graves, A., Wayne, G., & Danihelka, I. (2014). Neural Turing Machines. ArXiv:1410.5401 [Cs]. Retrieved from http://arxiv.org/abs/1410.5401
[3] Kurach, K., Andrychowicz, M., & Sutskever, I. (2015). Neural Random-Access Machines. ArXiv:1511.06392 [Cs]. Retrieved from http://arxiv.org/abs/1511.06392
[4] Grefenstette, E., Hermann, K. M., Suleyman, M., & Blunsom, P. (2015). Learning to Transduce with Unbounded Memory. ArXiv:1506.02516 [Cs]. Retrieved from http://arxiv.org/abs/1506.02516
[5] Kaiser, Ł., & Sutskever, I. (2015). Neural GPUs Learn Algorithms. ArXiv:1511.08228 [Cs]. Retrieved from http://arxiv.org/abs/1511.08228
[6] Michael Sipser, 计算理论导论[M], 中信出版社, 2002
[7] 图灵完备性, 维基百科, https://zh.wikipedia.org/wiki/图灵完备性
[8] Lipton, Z. C., Berkowitz, J., & Elkan, C. (2015). A Critical Review of Recurrent Neural Networks for Sequence Learning. ArXiv:1506.00019 [Cs]. Retrieved from http://arxiv.org/abs/1506.00019
[9] Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., Grabska-Barwińska, A., ... & Badia, A. P. (2016). Hybrid computing using a neural network with dynamic external memory. Nature, 538(7626), 471.
[10] 邱锡鹏, 神经网络与深度学习, https://nndl.github.io/
[11] 张嘉伟,玩转人工神经网络,https://zhuanlan.zhihu.com/p/24150657
[12] CHRIS OLAH, Attention and Augmented Recurrent Neural Networks, https://distill.pub/2016/augmented-rnns/
[13] Graves, A. (2013). Generating Sequences With Recurrent Neural Networks. ArXiv:1308.0850 [Cs]. Retrieved from http://arxiv.org/abs/1308.0850
[14] pytorch-ntm, github, https://github.com/loudinthecloud/pytorch-ntm
