卷积及降采样运算单元、神经网络运算单元和现场可编程门阵列集成电路的制作方法
本发明涉及数字集成电路领域,特别是涉及卷积及降采样运算单元、神经网络运算单元和现场可编程门阵列集成电路。
背景技术:
现场可编程门阵列(fpga)是一种通用的逻辑电路,具有灵活性高、开发风险低的优点,已广泛应用于工业控制、航空航天、通信、汽车电子等领域,并且占据着越来越多的市场份额。作为一种可编程器件,目前主流的fpga产品大多采用sram来对用户设计进行编程。fpga中的可编程资源包括:可编程逻辑模块(configurablelogicblock,clb)、可编程互连资源、可编程输入输出模块、可编程块存储器、可编程数字信号处理单元等。
随着越来越多智能处理任务的广泛开展,目前有越来越多的应用使用fpga平台来实现不同的神经网络算法。这些算法的层数、数据形式、网络形式千变万化,但核心的运算步骤均包括卷积运算、降采样运算等。在fpga中,通常使用可编程数字信号处理单元配合clb模块来实现这两种运算。但由于可编程数字信号处理单元原本是用来实现常用的数字信号处理功能,如fft、fir、乘法器等等,因此,在进行神经网络运算时,可编程数字信号处理单元的运算效率较低,且需要clb配合实现较为复杂的数据控制流程。
技术实现要素:
基于此,有必要针对现有技术中神经网络运算结构的运算强度大,运算效率低,可编程数字信号处理单元无法单独实现卷积和降采样功能,提供一种卷积及降采样运算单元、神经网络运算单元、嵌入了所述神经网络运算单元的现场可编程门阵列集成电路。
一种卷积及降采样运算单元,包括:
数据选择器与寄存器阵列,所述数据选择器与寄存器阵列用于选择输入的数据以何种形式进入运算;
乘法器,所述乘法器的输入端与所述数据选择器与寄存器阵列的数据输出端信号连接,所述乘法器用于完成乘法运算;
加法器,所述加法器的输入端与所述乘法器的数据输出端信号连接,所述加法器用于完成加法运算;
所述加法器为n个,所述乘法器为2n个,其中n为正整数;
数据信号选择器,所述数据信号选择器的输入端与所述加法器的数据输出端信号连接,所述数据信号选择器用于完成对经过加法计算得出的运算结果的选择;
加法信号选择器,所述加法信号选择器的第一输入端与所述数据选择器与寄存器阵列的输出端信号连接,所述加法信号选择器的第二输入端与所述数据信号选择器的输出端信号连接,所述加法信号选择器的输出端与所述加法器的输入端连接。
在一个实施例中,4n组并联设置的数据选择结构,每一组所述数据选择结构包括k个d触发器和k个多路选择器,k为每一组所述数据选择结构输入数据的位数;
所述多路选择器具有至少四个数据输入端,所述四个数据输入端分别连接所述d触发器的输入端、所述d触发器的输出端、数据0、数据1;
所述多路选择器具有一个数据输出端,用于输出经所述数据选择结构选择后的数据。
在一个实施例中,所述多路选择器为四路选择器,所述四路选择器具有2个控制输入端。
在一个实施例中,所述多路选择器为八路选择器,所述八路选择器具有3个控制输入端。
在一个实施例中,每一组所述数据选择结构还包括k个反相器和k个d触发器;
每个所述反相器的输入端用于完成数据输入,每个所述反相器的输出端与所述d触发器的输入端信号连接,每个所述;
所述八路选择器的四个输入端分别连接所述d触发器的输入端、所述d触发器的输出端、数据0、数据1;
所述八路选择器的第五个输入端与所述反相器的输出端信号连接;
所述八路选择器的第六个输入端与所述d触发器的输出端信号连接。
在一个实施例中,还包括第一寄存器组,信号连接设置于所述乘法器和所述加法器之间。
在一个实施例中,还包括第二寄存器组,信号连接设置于所述加法器和所述数据信号选择器之间。
在一个实施例中,所述第二寄存器组为d触发器,所述数据信号选择器包含多个相同结构的信号选择器,所述数据信号选择器中的每一个信号选择器的一个输入端与所述第二寄存器组的一位输出端信号连接;所述数据信号选择器中的每一个信号选择器的另一个输入端与所述加法器的一位数据输出端信号连接。
一种神经网络运算单元,包括上述任一项所述的卷积及降采样运算单元、激活运算器和多路选择器;
所述激活运算器的输入端与所述数据信号选择器的数据输出端信号连接;
所述多路选择器组包括多个相同结构的多路选择器,所述多路选择器组中的每一个多路选择器的一个输入端与所述激活运算器的一个输入端信号连接;
所述多路选择器组中的每一个多路选择器的另一个输入端与所述激活运算器的一位输出端信号连接。
在一个实施例中,每个所述神经网络运算单元通过所述数据选择器与寄存器阵列完成数据的输入;
每个所述神经网络运算单元通过上一级所述神经网络运算单元的输出信号完成控制信号的输入;
每个所述神经网络运算单元的输出数据将输入到下一级所述神经网络运算单元的控制信号输入端;
每两个所述神经网络运算单元之间通过直连列模式进行数据级联。
一种现场可编程门阵列集成电路,包括上述所述的神经网络运算单元、可编程逻辑块、可编程块存储器、可编程输入输出单元和可编程数字信号处理单元;
所述可编程逻辑块、所述可编程块存储器、所述可编程输入输出单元、所述可编程数字信号处理单元和所述神经网络运算单元之间通过可编程互连结构实现信号通信。
在一个实施例中,在至少一列的所述神经网络运算单元的两侧各设置一列所述可编程块存储器。
本发明提供的所述卷积及降采样运算单元包括数据选择器与寄存器阵列、乘法器、加法器、数据信号选择器和加法信号选择器。所述卷积及降采样运算单元的结构简单。所述卷积及降采样运算单元能够实现可变位宽的卷积运算、可旁路的激活操作、累加、加偏置、标量加权运算。所述卷积及降采样运算单元的运算强度大,运算效率高。
附图说明
图1为本发明一个实施例中,所述卷积及降采样运算单元的结构示意图;
图2为本发明一个实施例中,所述数据选择器与寄存器阵列的结构示意图;
图3为本发明一个实施例中,所述数据选择器与寄存器阵列的结构示意图;
图4为本发明一个实施例中,所述神经网络运算单元的结构示意图;
图5为本发明一个实施例中,所述神经网络运算单元的结构示意图;
图6为本发明一个实施例中,所述神经网络运算单元的结构示意图;
图7为本发明一个实施例中,所述神经网络运算单元级联的结构示意图;
图8为本发明一个实施例中,所述现场可编程门阵列集成电路的结构示意图;
图9为本发明一个实施例中,所述现场可编程门阵列集成电路的结构示意图。
附图标号说明:
卷积及降采样运算单元10
神经网络运算单元20
现场可编程门阵列集成电路30
数据选择器与寄存器阵列100
d触发器111
四路选择器112
反相器113
d触发器114
乘法器200
第一寄存器组300
可编程逻辑块310
可编程块存储器320
可编程输入输出单元330
可编程数字信号处理单元340
加法器400
第二寄存器组500
数据信号选择器600
加法信号选择器700
激活运算器800
多路选择器组900
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明的卷积运算及神经网络运算单元、可编程门阵列集成电路进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
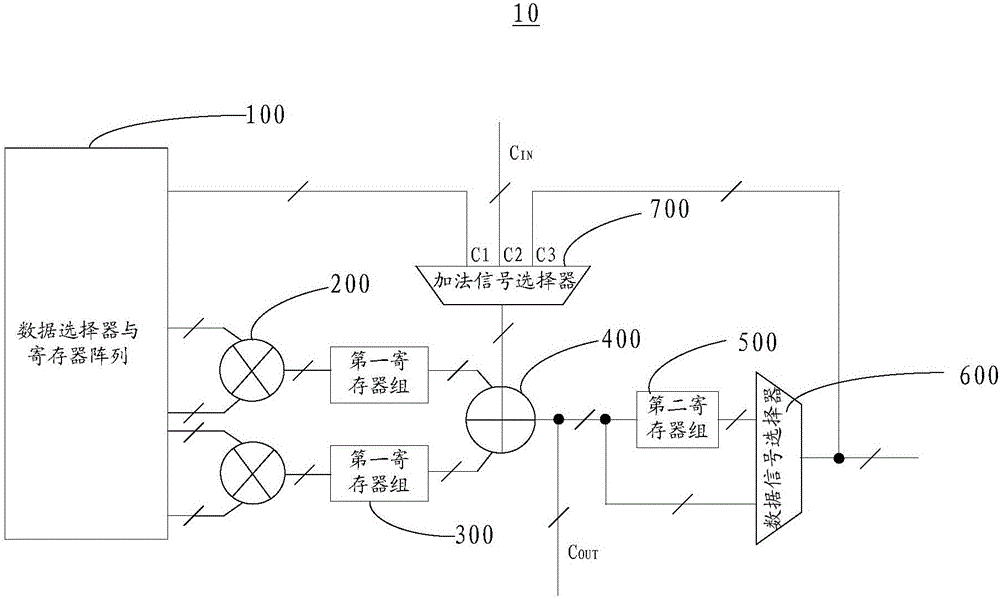
请参阅图1,本发明一个实施例提供一种卷积及降采样运算单元10,其包括数据选择器与寄存器阵列100、乘法器200、加法器400、数据信号选择器600和加法信号选择器700。
所述数据选择器与寄存器阵列100用于选择输入的数据是否进入运算或者以哪种形式参与运算。具体地,所述数据选择器与寄存器阵列100具体可以为数据选择器(multiplexer,数据选择器与寄存器阵列100)和寄存器(register)组成的阵列。所述数据选择器与寄存器阵列100可以对输入数据进行存储和选择。
所述乘法器200的输入端与所述数据选择器与寄存器阵列100的数据输出端信号连接。所述乘法器200用于完成乘法运算。比如,所述乘法器200包括两个输入信号a1和a2,那么所述乘法器200的输出信号b满足:b=a1×a2。可以理解,所述乘法器200还可以包括多个输入信号,用于完成各个乘数之间的乘法运算。
所述加法器400的输入端与所述乘法器200的数据输出端信号连接。所述加法器400用于完成加法运算。所述加法器400为n个,所述乘法器200为2n个,其中n为正整数。具体的,所述卷积及降采样运算单元10可以包括一个所述加法器400,两个所述乘法器200。所述乘法器200完成乘法运算之后,可以将乘法运算结果输入至所述加法器200以完成加法运算。可以理解,所述加法器400并不限定为三个加数相加。所述加法器400还可以设置为四个或更多个加数做加法运算。
所述数据信号选择器600的输入端与所述加法器400的数据输出端信号连接。所述数据信号选择器600用于完成对经过加法计算得出的运算结果的选择。具体的,所述数据信号选择器600可以是多路选择器。在一个实施例中,所述数据信号选择器600可以是一组二选一多路选择器。可以理解,所述数据信号选择器600的设置在此不做限定,可以根据具体的用户需求进行选择。
所述加法信号选择器700的第一输入端与所述数据选择器与寄存器阵列100的控制信号输出端信号连接。所述加法信号选择器700的第二输入端与所述数据信号选择器600的输出端信号连接。所述加法信号选择器700的输出端与所述加法器400的输入端连接。所述加法信号选择器700用于完成对整个卷积及降采样运算单元10中不同加数来源的选择。可以理解,所述加法信号选择器700也可以是多路信号选择器。在一个实施例中,所述加法信号选择器700为三选一信号选择器。
本实施例中,所述卷积及降采样运算单元10包括数据选择器与寄存器阵列100、乘法器200、加法器400、数据信号选择器600和加法信号选择器700。所述卷积及降采样运算单元10的结构简单。所述卷积及降采样运算单元10能够实现可变位宽的卷积运算、累加、加偏置、标量加权运算。所述卷积及降采样运算单元10的运算强度大,运算效率高。所述卷积及降采样运算单元10既能够实现卷积运算,又能够实现降采样运算,提高了使用fpga实现神经网络算法的效率。同时,还可以作为乘法器和加法器使用,作为fpga中可编程数字信号处理单元一种资源上的扩充。
请参阅图2,在一个实施例中,当所述加法器400的个数n,n取1,2,3……时,所述数据选择器与寄存器阵列100包括4n组并联设置的数据选择结构110。每一组所述数据选择结构110包括k个d触发器111和k个四路选择器112(k=1,2,3……)。
所述四路选择器112具有四个数据输入端。所述四个数据输入端分别连接所述d触发器111的输入端、所述d触发器111的输出端、数据0、数据1。
所述四路选择器112具有两个控制输入端,所述两个控制输入端分别输入第一控制信号s0和第二控制信号s1。
所述四路选择器112具有一个数据输出端,用于输出经所述数据选择结构110选择后的数据。本实施例中,所述数据选择器与寄存器阵列100可以输出四组经过选择的数据信号,分别为out_0[k-1:0]、out_1[k-1:0]、out_2[k-1:0]、out_3[k-1:0]。
具体的,请参阅图3,在一个实施例中,所述数据选择器与寄存器阵列100包括八组并联设置的数据选择结构110。每一组所述数据选择结构110包括k个d触发器111、k个八路选择器112、k个反相器113和k个d触发器114。
所述多路选择器112为八路选择器,所述八路选择器具有3个控制输入端,输入控制信号分别为s0,s1和s2。
所述八路选择器112具有一个数据输出端,用于输出经所述数据选择结构110选择后的数据。本实施例中,所述数据选择器与寄存器阵列100可以输出八组经过选择的数据信号,分别为out_0[7:0]、out_1[7:0]、out_2[7:0]……out_7[7:0]。
在一个实施例中,所述卷积及降采样运算单元10还包括第一寄存器组300。所述第一寄存器组300信号连接设置于所述乘法器200和所述加法器400之间。可以理解,所述第一寄存器组300的具体形式不做具体限定。具体地,所述第一寄存器组300可以是d触发器。所述d触发器可以寄存所述乘法器200得出的数据。
在一个实施例中,所述卷积及降采样运算单元10还包括第二寄存器组500。所述第二寄存器组500信号连接设置于所述加法器400和所述数据信号选择器600之间。同样,所述第二寄存器组500的具体形式也不作具体的限定。在一个实施例中,所述第二寄存器组500也为d触发器。
所述数据信号选择器600包含多个相同结构的信号选择器,在一个实施例中,所述数据信号选择器中的每一个信号选择器的一个输入端与所述第二寄存器组500的一位输出端信号连接。所述数据信号选择器中的每一个信号选择器的另一个输入端与所述加法器400的一位数据输出端信号连接。
请参阅图4-7,本发明一个实施例还提供一种神经网络运算单元20,包括激活运算器800、多路选择器组900,以及上述任意实施例所述的卷积及降采样运算单元100。
所述激活运算器800的输入端与所述数据信号选择器600的数据输出端信号连接。所述多路选择器组900包含多个相同结构的多路选择器,所述多路选择器组中的每一个多路选择器的一个输入端与所述激活运算器800的一个输入端信号连接。所述多路选择器组中的每一个多路选择器的另一个输入端与所述激活运算器800的一位输出端信号连接。具体地,所述多路选择器组900可以设置为多个二选一多路选择器。
本实施例中,所述神经网络运算单元20能够完成卷积运算层和降采样层的运算。具体的,卷积运算层又分为两个运算步骤:卷积的乘和加、加偏置。降采样层又分为四个运算步骤:加法运算、乘法运算、加偏置和非线性激活。
请参阅图4,所述乘法器200用于完成输入数据的对位相乘。将对位相乘后的结果传输至所述第一寄存器组300,在所述第一寄存器组300中存储该数据。将对位相乘后的数据传输至所述加法器400进行加法运算。通过fpga中的sram配置加法信号选择器的控制信号,使得加法信号选择器选择c2输出,来实现卷积运算层的卷积运算。完成卷积运算后,在下一级神经网络运算单元中,通过fpga中的sram配置使得乘法器200的输入数据均为0,同时配置加法信号选择器的控制信号,使得加法信号选择器选择c1输出,来实现卷积运算层的加偏置运算。。
降采样层的加法运算可以在fpga的clb中运行。降采样层的乘法运算也叫标量加权,可以只用到所述神经网络运算单元20中的一个乘法器进行乘法运算。完成标量加权后,通过fpga中的sram配置加法信号选择器的控制信号,使得加法信号选择器选择c1输出,来实现降采样层的加偏置运算。降采样层的非线性激活运算通过所述激活运算器800完成。
具体的,所述神经网络运算单元20在进行神经网络运算的过程中还可以反复多次的进行卷积运算和降采样运算。所述神经网络运算单元20能够完成的更具体运算过程和运算完成顺序可以根据具体的运算进行不同的设置。
请参阅图5,在一个实施例中,所述神经网络运算单元20包括四组并列设置的所述数据选择结构110、两个所述乘法器200、两个所述第一寄存器组300、一个所述加法器400、一个所述第二寄存器组500、一个所述数据信号选择器600、一个所述加法信号选择器700、一个所述激活运算器800和一个多路选择器组900。
所述两个乘法器200的输入端分别与所述数据选择器与寄存器阵列100的数据输出端信号连接。两个所述第一寄存器组300的输入端分别与两个所述乘法器200的数据输出端信号连接。所述加法器400的输入端与两个所述第一寄存器组300的数据输出端、以及所述加法信号选择器700的输出端分别连接。
所述第二寄存器组500的输入端与所述加法器400的数据输出端信号连接。所述数据信号选择器600包含多个相同结构的信号选择器,所述数据信号选择器中的每一个信号选择器的一个输入端与所述第二寄存器组500的一位输出端信号连接。所述数据信号选择器中的每一个信号选择器的另一个输入端与所述加法器400的一位数据输出端信号连接。所述加法信号选择器700的第一输入端连接所述数据选择器与寄存器阵列100的输出。所述加法信号选择器700的第二输入端连接上一级所述神经网络运算单元20的输出cout。所述加法信号选择器700的第三输入端连接所述数据信号选择器600的输出端。所述加法信号选择器700的输出端连接所述加法器400的输入端。神经网络运算输出cout设置于所述加法器400的输出端,用于输出本级所述神经网络运算单元20的运算结果。
所述激活运算单元800的输入端与所述数据信号选择器600的输出端信号连接。所述多路选择器组900包含多个相同结构的多路选择器,所述多路选择器组中的每一个多路选择器的一个输入端与所述激活运算器800的一个输入端信号连接。所述多路选择器组中的每一个多路选择器的另一个输入端与所述激活运算器800的一位输出端信号连接。具体地,所述多路选择器组900可以设置为多个二选一多路选择器。
请参阅图6,在一个实施例中,所述神经网络运算单元20包括八组并列设置的所述数据选择结构110、四个所述乘法器200、四个所述第一寄存器组300、两个所述加法器400、两个所述第二寄存器组500、两个所述数据信号选择器600、两个所述加法信号选择器700、两个所述激活运算器800和两个多路选择器组900。
图6中示出的实施例是设置了两个基本的所述神经网络运算单元20。图6中示出的实施例是两个图5中的所述神经网络运算单元20的并联结构。图6中示出的实施例中,所述神网络运算单元20能够实现更大两的存储数据的神经网络的运算。可以理解,根据需要还可以扩展现有的所述神经网络运算单元20的容量和计算量。
请参阅图7,在一个实施例中,每个所述神经网络运算单元20通过所述数据选择器与寄存器阵列100完成数据的输入。每个所述神经网络运算单元20通过上一级所述神经网络运算单元20的输出信号完成控制信号的输入cin。每个所述神经网络运算单元20的输出数据cout将输入到下一级所述神经网络运算单元20的加法信号输入端。每两个所述神经网络运算单元20之间通过直连列模式进行数据级联。本实施例中,所述神经网络运算单元能够实现可变位宽的卷积运算、可旁路的激活操作、累加、加偏置、标量加权等。
fpga(field-programmablegatearray),即现场可编程门阵列,它是在pal、gal、cpld等可编程器件的基础上进一步发展的产物。fpga作为专用集成电路(asic)领域中的一种半定制电路,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。在fpga中,通常使用可编程数字信号处理单元配合clb模块来实现这两种运算。但由于可编程数字信号处理单元原本是用来实现常用的数字信号处理功能,如fft、fir、乘法器等等,因此,在进行神经网络运算时,可编程数字信号处理单元的运算效率较低,且需要clb配合实现较为复杂的数据控制流程。
请参阅图8-9,本发明一个实施例还提供一种现场可编程门阵列集成电路30。所述现场可编程门阵列集成电路30是用于实现神经网络运算的现场可编程门阵列。所述现场可编程门阵列集成电路30包括如上述所述的神经网络运算单元20、可编程逻辑块310、可编程块存储器320、可编程信号处理单元340和可编程输入输出单元330。
可编程逻辑块310也称作clb,用于实现任意输入的组合、寄存逻辑。可编程块存储器320也称作bram。所述可编程块存储器320具有一定大小的存储容量(512bit、4k、9k、20k或者更大)。所述可编程块存储器320可配置成多种工作模式:多种位宽模式的单端口、多种位宽模式的简单双端口、多种位宽模式的真双端口。
可编程输入输出单元330也称作可编程io。所述可编程输入输出单元330用于实现fpga芯片内部与外部信号的互连。在一个实施例中,可编程数字信号处理单元340也称作dsp。所述可编程数字信号处理单元340通常是多位宽浮点/定点乘法器+加法器。
在一个实施例中,所述可编程逻辑块310、所述可编程块存储器320、所述可编程数字信号处理单元340、所述可编程输入输出单元330和所述神经网络运算单元20之间通过可编程互连结构实现信号通信。
可以理解,上述所有的可编程模块之间的信号通信通过可编程互连结构实现。可编程模块包括上述的可编程逻辑块310、可编程块存储器320、可编程输入输出单元330以及可编程数字信号处理单元340。可编程互连结构分布在clb之间、clb与可编程输入/输出模块之间。可编程互连结构包括互连线段、连线连接盒(connectionbox,cb)和连线开关盒(switchbox,sb)。其中,cb将clb的输入和输出引脚连接到互连线段上,sb将水平和垂直方向上的互连线段连接起来。clb的输出还可以通过直连(directlink)的方式直接连接到与其临近的可编程模块中。
在一个实施例中,所述神经网络运算单元20之间设置直连模式。在一个实施例中,可以设置所有可编程模块均为列模式,即一列为同一种类型的可编程模块,芯片的可编程性通过对其中的配置模块(sram、flash、熔丝等)进行编程来实现。
为了进一步提高性能,在该可编程神经网络运算单元的左右,各放置一列bram。其中,左边的bram列存放神经网络的权值,右面的bram列存放卷积层或降采样层的计算结果。除了通用的互连结构外,增加特殊的直连模式,从而以更高的性能来实现神经网络运算。
本实施例中,提供的所述属于深度学习架构,这些架构具有不同的层数、位宽,各有各自的侧重。本发明的可编程门阵列集成电路30能够更好的利用fpga的灵活性、可编程特性。同时,fpga本身有丰富的高速接口(如ddr、serdes、pcie等),使得一款芯片能够满足用户在多个应用场景下的需求、实现多个深度学习架构。
可参阅图9,在一个实施例中,提供所述可编程门阵列集成电路30进行神经网络运算的具体步骤为:
s01,将bram配置为简单双端口模式;
s02,将输入的数据和权值存放于bram中;
s03,所述神经网络运算单元20从bram中读取所述输入数据和权值,做卷积运算(包括乘法和累加运算)。此时,所述神经网络运算单元20中的所述加法信号选择器700选择c2作为输入,完成卷积层中的卷积运算。即,上一级的所述神经网络运算单元20得出的结果作为本级所述神经网络运算单元20的输入数据进行运算,完成卷积运算后,在下一级神经网络运算单元中,乘法器200的输入数据均选择为0,同时加法信号选择器选择c1输出,来实现卷积运算层的加偏置运算。所述神经网络运算单元20所得计算结果写入到右边的bram中;
s04,所述神经网络运算单元20从bram中读取权值,从上一层卷积运算写入的bram中读取上一层卷积层的运算结果;
s05,做降采样层运算,实现数据的标量加权、加偏置。用所述神经网络运算单元20中的一个乘法器进行乘法运算。完成标量加权后,加法信号选择器选择c1输出,来实现降采样层的加偏置运算;
s06,激活运算。通过所述神经网络运算单元20中的所述激活运算器800和所述多路选择器组900完成对数据的激活运算。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 基于博弈理论的灰色神经网络预...
- 基于灰狼群优化LSTM网络的...
- 基于注意力机制的单张图像人群...
- 一种工业物联网云计算盒的制作...
- 一种非接触IC卡及可有效标记...
- 用于人机交互的超高频无源触控...
- 一种带有天线的扎带的生产方法...
- 用于游戏的RFID天线阵列的...
- 一种智能卡及其工作方法与流程
- 一种智能卡、应用实现方法、装...
- 还没有人留言评论。精彩留言会获得点赞!
- 可编程卷积器的制作方法
- 一种基于fpga的实时模板卷积实现方法
- 基于非完全数据解卷积的实孔径前视成像方法
- 基于全卷积神经网络的极化SAR地物分类方法与流程
- 基于一维卷积神经网络的雷达辐射源信号的识别方法与流程
- 基于深度卷积神经网络的乳腺癌风险评估分析系统的制造方法与工艺
- 一种基于医学征象和卷积神经网络的肺结节CT图像哈希检索方法与流程
- 一种基于卷积神经网络的APP相似图标检索方法和系统与流程
- 一种基于卷积神经网络的企业实体关系抽取的方法与流程
- 一种基于卷积神经网络自适应背景建模物体检测方法与流程
- 一种基于卷积神经网络的输电线路螺栓检测方法与流程
- 一种基于多个分类器的卷积神经网络快速分类方法与流程
- 一种基于全卷积神经网络的SAR图像目标检测方法与流程