一种基于DC-SPP-YOLO的图像目标检测方法与流程
本发明涉及一种图像目标检测方法,属于机器视觉技术领域,尤其涉及一种基于密集连接和空间金字塔池化yolo(denseconnectivityandspatialpyramidpoolingimprovedyoulookonlyonce,dc-spp-yolo)的目标检测方法。
背景技术:
目标检测是机器视觉领域的核心研究内容之一,广泛应用于驾驶导航、工件检测、机械臂抓取等方面。建立并训练高质量的目标检测模型,能够提取更丰富、有效的目标特征,提高在图像或视频中定位和分类目标的准确度。
传统的形变部件模型(deformablepartsmodels,dpm)等目标检测方法通过滑动窗口搜索目标位置,效率低下;提取目标的梯度方向直方图(histogramoforientedgradients,hog)等人工设计特征用于目标分类,难以全面、深层次的表达目标特征信息。深度卷积神经网络因具有良好的特征提取和表达能力被应用于图像目标分类和检测任务,其中的yolo(youlookonlyonce)算法具有目标检测速度快、无需生成推荐区域等优点,实现了图像目标的实时检测。然而,yolo和yolov2法在目标检测精度方面仍然存在局限;当通过加深网络提高模型学习能力时会出现梯度消失现象,yolov3算法采用残差连接方式缓解了梯度消失现象但阻碍了网络各层的信息流;同时,yolov2和yolov3算法的多尺度目标检测偏重于融合不同尺度卷积层的全局特征,忽略了融合同一卷积层不同尺度的局部区域特征;这都制约着目标检测准确度的提高。
因此,本发明充分考虑了加深卷积网络引起的“梯度消失”问题和yolov2模型未充分使用多尺度局部区域特征问题,在yolov2网络模型中采用卷积层密集连接方式进行改进,同时引入空间金字塔池化汇聚多尺度局部区域特征,构建了dc-spp-yolo目标检测模型,提高了目标检测的精度。
技术实现要素:
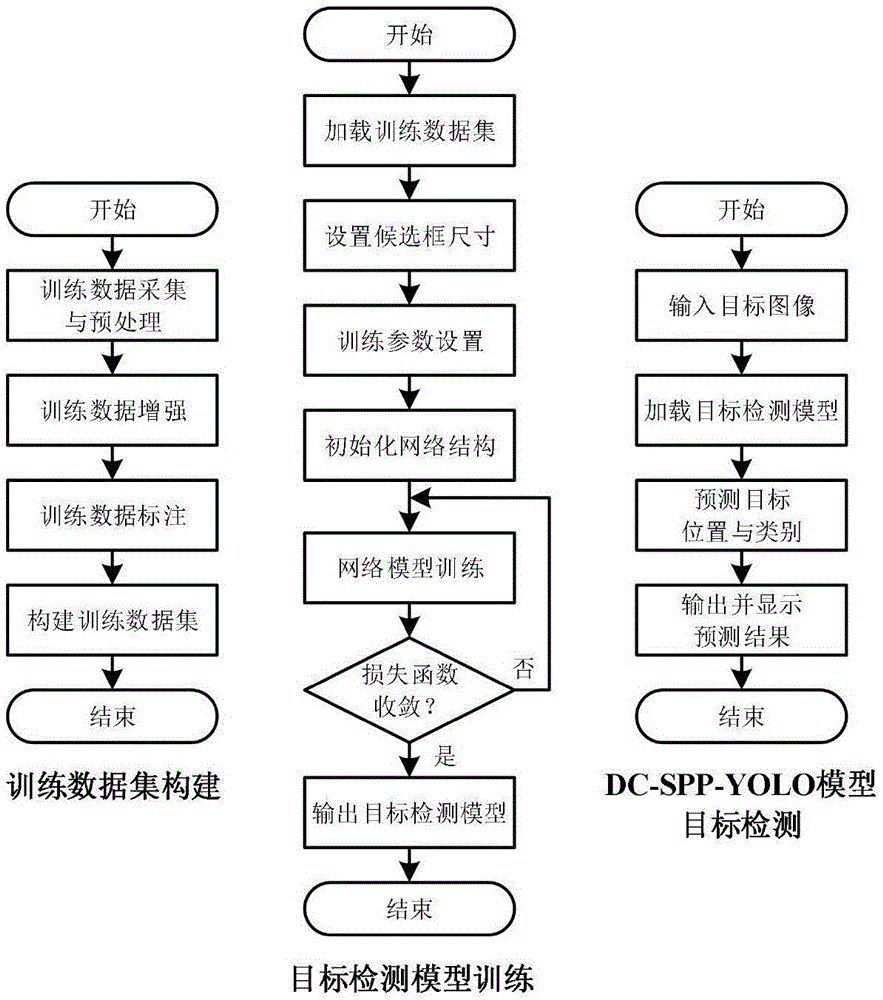
本发明以提高yolov2模型目标检测精度为目的;首先采用数据增强方法对训练样本进行预处理并构建训练数据集,采用k-means聚类算法选取训练样本中主要的若干类边界框尺寸作为预测目标边界框的先验信息;然后构建yolov2目标检测网络模型,将卷积层连接方式由逐层连接改进为密集连接,对卷积层输入数据进行批归一化并采用leakyrelu激活函数进行非线性化,在卷积模块与目标检测层之间引入空间金字塔池化模块汇聚多尺度图像局部区域特征;最后以目标位置和类别预测的最小平方和误差为训练目标构建损失函数,训练深度卷积网络模型直至损失函数收敛,进而利用所训练的dc-spp-yolo模型检测图像目标。dc-spp-yolo目标检测流程如图1所示。
本发明采用的技术方案为一种基于dc-spp-yolo的图像目标检测方法,该方法具体包括以下步骤:
步骤一:采用图像几何变换等数据增强方法对训练样本进行预处理并构建训练数据集,以训练图像目标边界框与聚类中心目标边界框的重合度作为聚类距离指标,采用k-means聚类算法选取训练样本中主要的若干类边界框尺寸作为预测目标边界框的先验信息;
步骤二:构建yolov2目标检测网络模型,将卷积层连接方式由逐层连接改进为密集连接,对卷积层输入数据进行批归一化并采用leakyrelu激活函数进行非线性化,在卷积模块与目标检测层之间引入空间金字塔池化模块汇聚多尺度图像局部区域特征;
步骤三:以目标位置和类别预测的最小平方和误差为训练目标构建损失函数,根据步骤一获得的训练数据集和目标边界框先验信息,训练步骤二所构建的dc-spp-yolo目标检测模型直至损失函数收敛;
步骤四:输入被测目标图像,利用所训练的dc-spp-yolo模型检测图像中的目标,输出图像中每个目标的边界框位置、尺寸以及目标类别。
具体而言,步骤一包括如下步骤:
采用几何变换等方法对训练样本进行数据增强,增加训练样本的多样性进而提高目标检测精度。设原图像中某一像素点的坐标为(x0,y0),几何变换后该像素点的坐标为(x1,y1),图像宽和高分别为width和height;对图像进行水平位移为tx、垂直位移为ty的平移变换可表示为
对图像绕中心点进行逆时针旋转
对图像进行水平镜像变换和垂直镜像变换分别表示为
对图像进行水平方向缩放因子为sx、垂直方向缩放因子为sy的缩放表示为
以训练图像中目标边界框与聚类中心目标边界框的重合度作为聚类距离指标,即
其中
步骤二包括如下步骤:
将输入图像划分为s×s的网格,训练图像中预先标记的目标真实边框中心坐标所在的网格负责预测该类目标的位置和类别。通过回归预测每个包含目标真实位置中心的网格预测b个可能的目标边框。每个目标边框包含五个参数,即边框中心点坐标x和y、边框宽度w和高度h、该边框含有目标的置信度c。其中置信度c由该边框含有物体概率pr(object)和边框准确度
对预测框包含的目标类别进行预测,若训练样本中共有c类(c∈n*)目标,则该预测框包含的物体属于第i类(i∈n*,i≤c)的概率为pr(classi|object),预测框的类别置信度表示为
模型预测输出为s×s×(b*(5+c))维的特征向量,其表示输入图像每一个网格预测的边界框的位置、大小、置信度以及其包含的目标类别概率。
以yolov2的darknet19网络为基础,将最后一个卷积模块的连接方式由逐层连接改进为密集连接,如图3所示。设卷积模块的初始输入为x0,第l层输入为xl,批次归一化、非线性激活函数和卷积用非线性映射gl(.)表示;则逐层连接方式可表示为
xl=gl(xl-1)(10)
密集连接方式将前l-1层输出的特征图堆叠为[x0,x1,…,xl-1]作为第l层输入,即
xl=gl([x0,x1,…,xl-1])(11)
每个非线性映射函数gl(.)输出k幅堆叠的特征图,密集连接模块的第l层输入k0+k×(l-1)幅堆叠的特征图,其中k0为每个密集连接模块输入的特征图通道数。在卷积层之前进行批次归一化,采用leakyrelu激活函数
对卷积进行非线性化处理。
在卷积层与目标检测层之间引入空间金字塔池化模块,如图4所示,池化窗口尺寸sizepool×sizepool的取值可表示为
其中sizefmap×sizefmap表示输入特征图尺寸,ni=1,2,3,…;池化步长均为1,采用边界填充保证池化后特征图尺寸不变。
步骤三包括如下步骤:
训练步骤二所构建并如图5所示的dc-spp-yolo目标检测模型,使其学习预测目标位置和类别,设预测的边界框中心相对于其所在网格左上角坐标与网格边长的比值分别为tx和ty,采用sigmoid激活函数函数
约束预测值,将其归一化为σ(tx)和σ(ty);设边界框宽、高相对于先验框宽、高的比值取对数为tw和th;边界框相对先验框的目标置信度为tc,归一化为σ(tc);边界框中心点所在网格左上角坐标为(cx,cy);先验框的宽和高分别为pw和ph;则边界框的中心点坐标(bx,by)、宽bw、高bh和置信度bc分别为
bx=σ(tx)+cx(15)
by=σ(ty)+cy(16)
bc=σ(tc)(19)
预测的边界框输出最终表示为b=[bx,by,bw,bh,bc]t;同理,训练集中目标边界框的真实信息可表示为g=[gx,gy,gw,gh,gc]t;目标的分类情况表示为class=[class1,class2,…,classc]t,目标属于各类的实际概率为pr(classl)l∈c,模型预测的目标属于各类的概率为
采用最小平方和误差构建目标预测的损失函数:
其中w、h分别为特征图每列和每行的网格数。
步骤四包括如下步骤:
输入被测目标图像,加载根据步骤三训练好的dc-spp-yolo模型检测图像中的被测目标;设置阈值iouthres和pr(class)thres,筛选符合要求的目标位置和类别信息;再采用非极大抑制进行局部最大搜索,抑制冗余边框;取筛选后每个网格
本发明的优点:充分考虑了深度卷积网络的梯度消失问题和同一卷积层多尺度局部区域特征融合方法;在yolov2网络模型中采用卷积层密集连接方式进行改进,聚合不同卷积层特征,增大网络信息流,强化特征传播;引入空间金字塔池化模块汇聚多尺度局部区域特征,综合利用丰富的多尺度全局特征和局部区域特征;构建了dc-spp-yolo目标检测模型,提高了目标检测的精度。
附图说明
图1是本发明所述的一种基于dc-spp-yolo的目标检测方法流程图。
图2是k-means聚类算法选取训练样本目标边界先验框的流程图。
图3是dc-spp-yolo算法密集连接卷积的原理图。
图4是dc-spp-yolo算法空间金字塔池化的原理图。
图5是dc-spp-yolo深度卷积网络模型图。
图6是dc-spp-yolo算法计算损失函数和迭代更新网络权重的流程图。
图7是具体实施方式中dc-spp-yolo模型在pascalvoc标准数据集上的图像目标检测结果。
具体实施方式
下面结合实例及附图对本发明作进一步的描述,需要说明的是,实施例并不限定本发明要求保护的范围。
实施例
实施例采用公开且被广泛应用于图像识别与目标检测算法性能测评的pascalvoc(2007+2012)标准数据集进行dc-spp-yolo模型的训练和测试;其中voc2007+2012数据集共包含图像样本32487幅,训练数据集图像8218幅,验证数据集图像8333幅,voc2007测试数据集图像4952幅,voc2012测试数据集图像10990幅。
实施例的计算机配置为intel(r)xeon(r)e5-26433.3ghzcpu,32.00gb内存,1块显存为11.00gb的navidagtx1080tigpu。实施例在windows10系统visualstudio2017平台上进行,所使用的深度学习框架为darknet,采用c/c++语言编程实现。
将本发明应用到上述pascalvoc数据集图像目标检测中,具体步骤如下:
步骤一:采用几何变换等方法对训练样本进行数据增强;对训练图像随机进行水平位移tx和垂直位移ty分别在(-width/4,width/4)和(-height/4,height/4)之间随机变化的平移变换;对训练图像绕中心点进行随机逆时针旋转变换,旋转角
以训练图像中目标边界框与聚类中心目标边界框的重合度作为聚类距离指标,即采用k-means聚类方法将所有训练样本中的目标边界框分为5类,取各类中心的目标边界框尺寸作为模型预测目标边界框的先验边界框尺寸。聚类获得的先验边界框尺寸(w,h)分别为:(1.3221,1.73145)、(3.19275,4.00944)、(5.05587,8.09892)、(9.47112,4.84053)和(11.2364,10.0071)。
步骤二:将训练图像缩放至416×416像素大小输入dc-spp-yolo网络模型,每10个训练批次对输入图像尺寸进行随机缩放,缩放的大小在256×256像素至608×608像素之间随机变化,变化幅度为32像素的整数倍。
将输入图像划分为13×13的网格,训练图像中预先标记的目标真实边框中心坐标所在的网格负责预测该类目标的位置和类别。对输入数据进行批次归一化,采用在yolov2模型的基础上,将最后一个卷积模块的连接方式改进为4层卷积层密集连接;输入特征图尺寸为13×13×512,输出特征图尺寸为13×13×6144;再采用1×1的卷积核减少特征图数量至。在卷积层之前进行批次归一化,采用ai=10的leakyrelu激活函数对卷积进行非线性化处理。
在卷积模块与目标检测模块之间引入空间金字塔池化模块,空间金字塔池化模块共有3层,池化窗口尺寸分别设置为5×5、7×7和13×13,滑动步长为1,采用最大池化方式;输入特征图尺寸为13×13×512,输出特征图尺寸为13×13×2048。dc-spp-yolo模型结构及参数设置如图5所示。
通过回归预测每个包含目标真实位置中心的网格预测5个可能的目标边框,设置接受该边界框包含目标的交并比阈值iouthres=0.5。pascalvoc数据集共有20类目标,通过分类的方法预测物体属于每一个类别的概率,取最大概率的类别作为预测的物体类别,设置接受物体属于某一类别的概率阈值pr(class)thres=0.5。
步骤三:训练dc-spp-yolo目标检测模型,计算预测边界框中心相对于其所在网格左上角坐标与网格边长的比值tx和ty,采用sigmoid激活函数函数约束预测值,将其归一化为σ(tx)和σ(ty);计算边界框宽、高相对于先验框宽、高的比值对数tw和th;计算边界框相对先验框的目标置信度为tc并归一化为σ(tc);根据边界框中心点所在网格左上角坐标(cx,cy)、先验框的宽pw和高ph计算预测的边界框位置和置信度向量b=[bx,by,bw,bh,bc]t;计算模型预测的目标属于各类的概率
采用最小平方和误差构建目标预测的损失函数,根据步骤二可知w=13、h=13,iouthres=0.5,pr(class)thres=0.5。设置各部分损失的权重系数λnoobj、λobj、λcoord和λclass分别为1、1、5、1。在前12800个训练样本中引入损失项,计算没有提供实际框有效预测的先验框与预测边界框之间的损失,权重系数λprior=0.1。
分批次输入训练样本,设置批次大小为64、初始学习率为0.001、动量为0.9、权值衰减系数为0.0005,计算每批次训练的平均损失,采用自适应矩估计优化算法迭代更新权值,训练网络模型直至损失函数收敛,得到dc-spp-yolo目标检测模型。
步骤四:输入测试数据集图像样本,加载根据步骤三训练好的dc-spp-yolo模型检测图像中的被测目标;根据阈值iouthres和pr(class)thres,筛选符合要求的目标位置和类别信息;再采用非极大抑制进行局部最大搜索,抑制冗余边框;取筛选后每个网格
上述步骤为本发明在pascalvoc数据集上进行模型训练和目标检测的具体应用,为了验证本发明的有效性,设置基于yolov2模型的目标检测方法为实验对比方法,利用平均查准率均值(meanaverageprecision,map)和目标检测速度作为性能评价指标,评价dc-spp-yolo算法的目标检测性能。pascalvoc2007测试数据集的目标检测结果如表1所示。
表1dc-spp-yolo算法在pascalvoc2007测试数据集上的目标检测结果
由表1可知,在pascalvoc2007测试数据集上,当输入特征图尺寸分别为416×416像素和544×544像素时,dc-spp-yolo模型目标检测的map分别为78.4%和79.5%,yolov2模型目标检测的map分别为76.8%和78.6%;实验结果表明,同等实验条件下,采用pascalvoc2007测试数据集,dc-spp-yolo模型的目标检测精度高于yolov2模型的目标检测精度更高。
在上述实验条件下测试卷积层密集连接改进和空间金字塔池化改进之后yolov2目标检查模型的性能提升情况,结果如表2所示。
表2卷积层密集连接改进和空间金字塔池化改进的yolov2模型性能提升情况
由实验结果可知,在yolov2模型中采用卷积层密集连接改进使得其在pascalvoc2007测试数据集上目标检测map达到77.6%,相较于yolov2的map提升0.8%;在yolov2模型中引入空间金字塔池化模块使得map提升0.7%;同时采用卷积层密集连接和空间金字塔池化改进的dc-spp-yolov2模型目标检测精度达到78.4%,相较于yolov2算法的map提升1.6%。
pascalvoc2012测试数据集的目标检测结果如表3所示。
表3dc-spp-yolo模型在pascalvoc2012测试数据集上的目标检测结果
注:表3目标检测map和各类别ap的结果均为百分比数值(%),粗体表示上述四种模型检测该类目标的最高ap值。dc-spp-yolo模型在pascalvoc2012标准测试数据集上的目标检测结果通过了pascalvocevaluationserver的测评,测评结果可见http://host.robots.ox.ac.uk:8080/anonymous/tad5ii.html。
实验结果表明dc-spp-yolo算法在pascalvoc2012测试数据集上的目标检测map达到74.6%,相较于yolov2模型的map提升1.2%;20类被测目标中的18类,dc-spp-yolo模型预测的ap值高于yolov2模型预测的ap值(表3中字体的加粗部分),目标检测精度有了较明显的提升。
上述实验结果表明:采用本发明所述方法对yolov2目标检测模型进行的改进合理、有效,提高了图像目标检测的精度。
- 电路板料号识别方法、装置及计...
- 一种车内按键/图标即问即答的...
- 情绪精细划归模型构建及自动进...
- 多类别人体动作识别方法及识别...
- 一种基于三维模型的差异性对比...
- 一种基于双卷积和主题模型的场...
- 一种基于深度学习和图像处理的...
- 一种对视频模型做评估的方法、...
- 一种甲状腺锝扫图像的识别模型...
- 一种图像匹配方法及装置与流程
- 还没有人留言评论。精彩留言会获得点赞!
- 低功耗便携式实时图像目标检测与跟踪装置的制造方法
- 一种基于张量表示的偏振高光谱图像目标检测方法
- 基于nmf图像融合的sar图像变化检测方法
- 基于收缩自编码器的sar图像分类方法
- 一种图像中确定目标遮掩的方法及装置的制造方法
- 一种多分辨层次化筛选的遥感图像港口船舶检测方法
- 基于空谱联合背景共同稀疏表示的高光谱异常检测方法
- 一种基于部件模型的高分辨sar图像目标检测方法
- 一种基于图像显著性与svm的飞机目标检测方法
- Ka FMCW SAR的运动目标检测方法及装置的制造方法
- 一种自动获取目标图像的方法
- 低信杂比合成孔径雷达图像的地物目标检测方法
- 一种图像中运动目标的计数方法
- 用于生成由多个子图像构成的目标体的合成图像的方法
- 一种烟田图像目标定位线的检测方法
- 大斜视角下无人机可见光和红外图像目标定位方法
- 使用基于来自其它图像的信息的函数的泛函产生目标图像的制作方法
- 一种获取目标图像的方法以及目标追踪设备的制造方法
- 一种作物图像稠密匹配方法及系统的制作方法
- 一种基于视频图像的目标分类方法
- 用于在移动终端中跟踪视频图像中的物体的方法
- 一种确定图像中的目标区域的方法和装置的制造方法
- 极化sar图像中目标极化相干特征的增强方法
- 一种水下小目标声呐图像目标检测跟踪方法和系统的制作方法
- 基于多种特征联合的目标sar图像和光学图像配准方法
- 一种基于isar图像的空间目标姿态反演方法
- 用于显示目标的第一图像和第二图像的方法和设备的制造方法
- 一种基于深度图像的自适应调整目标跟踪算法
- 一种自动获取目标图像的方法
- 低信杂比合成孔径雷达图像的地物目标检测方法
- 基于局部协同表示和邻域信息约束的高光谱图像分类方法
- 极化sar图像舰船目标检测方法
- 基于光谱显著性的高光谱遥感图像小目标检测方法
- 一种高光谱图像的异常检测方法及装置制造方法
- 一种高光谱图像异常检测的方法
- 一种sam加权kest高光谱异常检测算法的制作方法
- 采用多窗口特征分析的高光谱图像异常检测方法
- 一种高速多光谱无限远动态目标发生方法与装置制造方法
- 一种高光谱检测装置制造方法
- 基于目标红外辐射光谱和带模式的被动测距方法