一种基于IDCNN-crf与知识图谱的影视实体识别方法与流程
本发明涉及深度学习自然语言处理技术领域,特别涉及一种基于idcnn-crf与知识图谱的影视实体识别方法。
背景技术:
智能电视已进入了快速发展,视频领域也积累了大量的影片、演员等非结构化的用户数据。原语义识别系统是语音识别后的文本做简单的数据处理后,去媒资数据库模糊搜索,由于媒资库数据量大,搜索比较耗时,且准确率不高,一些噪音数据也有可能被识别成影片名输出,而且不能满足用户多轮请求的需求,用户体验很差。对语音识别后文本的语义的识别即命名识别是智能电视的关键技术之一。如何用一种有效地方式准确的提取影视实体,以帮助用户快速找到其心仪的影视剧,成为一个重要的需求。
目前命名实体识别在自然语言处理中较多采用深度神经网络方法,将语料标注与词向量特征结合,通过减少人工特征在模型中的比重,减少命名实体识别系统对于大型语料库的依赖;并通过概率统计降低规则方法的复杂度,有效提高了模型的性能。在实际工程中主要采用长短期记忆(longshorttermmemory,lstm)神经网络及卷积神经网络(convolutionalneuralnetworks,cnn)等深度学习算法。目前对于命名实体识别任务,表现效果最好的算法基本上采用双向lstm(bidirectionallstm),避免了模型庞大的参数优化问题。采用blstm通过词向量、字符向量等特征,建立embedding层,再经过双向的lstm层,最后为crf层。该模型集成了深度学习方法的优势,无需特征工程,仅使用字符向量就可以达到很好的效果。对于序列标注,cnn有一个不足,就是卷积之后,末层神经元可能只是得到了原始输入数据中一小块的信息。而对ner来讲,整个输入句子中每个字都有可能对当前位置的标注产生影响,即所谓的长距离依赖问题。为了覆盖到全部的输入信息就需要加入更多的卷积层,导致层数越来越深,参数越来越多。而为了防止过拟合又要加入更多的dropout之类的正则化,带来更多的超参数,整个模型变得庞大且难以训练。但bilstm又有个问题,在对gpu并行计算的利用上不如cnn那么强大。
因此,提出了dilatedcnn模型,意思是“膨胀的”cnn。其想法并不复杂:正常cnn的filter,都是作用在输入矩阵一片连续的区域上,不断sliding做卷积。dilatedcnn为这个filter增加了一个dilationwidth,作用在输入矩阵的时候,会skip所有dilationwidth中间的输入数据;而filter本身的大小保持不变,这样filter获取到了更广阔的输入矩阵上的数据,看上去就像是“膨胀”了一般。而且与其他领域相比,影视领域涉及实体类别复杂,包含的实体种类也千差万别,”扫毒”和电影‘扫毒’,看似同一实体却属于不同实体类型,而且实体的命名方式无法统一,用户普通话不标准,平翘舌不分,同一实体不同表达方式等,都对语音识别后的命名实体识别产生很大影响。
技术实现要素:
本发明的目的是克服上述背景技术中不足,提供一种基于idcnn-crf与知识图谱的影视实体识别方法,能够解决标注数据少及文本简短、口语化的影视文本数据的实体识别问题。
为了达到上述的技术效果,本发明采取以下技术方案:
一种基于idcnn-crf与知识图谱的影视实体识别方法,包括以下步骤:
a.收集影视数据信息;
b.收集大量通过语音转换为文本的用户搜索影视的数据并进行数据分析得到用于模型训练的训练数据;
c.对实体识别模型进行训练;
d.采集需要进行预测的预测数据,并在进行数据预处理后输入实体识别模型进行预测;
e.对模型预测结果进行验证处理并输出。
进一步地,所述步骤a具体为:从各大影视数据源实时收集影视数据信息,爬取各影视数据的包括影视名、演员、角色、人物关系的实体信息,建立影视专用的知识图谱;如可从豆瓣、百度百科等,爬取各影视名、演员、角色、人物关系等各实体信息,建立影视专用的知识图谱,其中,知识图谱的建立和维护不是本方案的重点,本方案只借助知识图谱做进一步验证,因此对应的具体步骤在此不再赘述。
进一步地,所述步骤b包括:将采集的用户数据进行频次统计、k-means聚类分析,并将用户说法意图相似的语句聚类到一起结合频次分析及聚类分析的结果,预知用户常用的影视搜查语句并打上标签作为训练数据;具体的,对从电视端采集的大量用户数据做频次统计、k-means聚类分析,经过测试调参这里选择15个聚类点,会将用户说法意图相似的语句聚类到一起结合频次分析及聚类分析的结果,大概预知用户常用的影视搜查语句,确定要识别的实体类型。
进一步地,所述实体识别模型由特征表示层、dropout层、idcnn层和crf层构成,其中,特征表示层即嵌入层是由词向量和字符向量组成,所述字符向量是通过lm模型训练得到的,词向量是结巴分词后按‘0/1/2/3’编码后的向量,其长度为输入文本的长度值,模型初始的参数是通过word2vec训练得的100维预训练字符向量,通过将词向量和字符级向量进行拼接以表示单词在特定语义空间下的特征;
所述dropout层用于对输入的特征进行dropout(随机失活)处理以预防过拟合,所述idcnn层具体是对输入的特征分别编码当前时刻的上文和下文信息;再将两者的编码信息合并构成待解码的得分信息;具体的,实体识别模型是4个大的相同结构的dilatedcnnblock拼在一起,每个block里面是dilationwidth为1,1,2的三层dilated卷积层,所以叫做iterateddilatedcnn,idcnn层可对输入句子的每一个字生成一个logits;所述crf层用于将idcnn层的输出得分作为输入,同时引入转移得分矩阵,根据序列得分选择最优的标签序列。
进一步地,所述步骤b中还包括进行词向量训练,具体包括:对训练数据进行包括去除特殊标点符号、英文大小写转换的预处理,然后将处理后的数据使用gensim工具包的word2vec训练,训练为维度100维的字符向量,对训练数据的句子进行结巴分词并编码得到词向量,将词向量与word2vec训练出的字符向量按一定权重相加得到最终的词向量,并将最终得到的词向量作为双向idcnn网络的初始参数;
本方案中,用大量真实数据训练的词向量一定程度上解决了标注数据少的情况下使用深度神经网络做实体识别的问题,idcnn神经网络的初始参数不再是没有意义的随机参数,大量数据训练的词向量会得到中文字偏旁等初始信息作为神经网络的底层输入,本文还加入了优化后的词向量,一句话中一个单独的字符可能没有实际意思,而正确的分词向量却对整句话起着重要作用,将字符向量和词向量结合更能体现文本的整体特征。
进一步地,在所述步骤c中进行实体识别模型训练前还包括从训练数据中筛选出包含各个标签的常用数据,并由人工按bio标准进行训练数据标注。
进一步地,进行实体识别模型训练时具体包括以下步骤:
c1.将所有标注的训练数据按a、b、c的比例划分为训练数据集、测试数据集和验证数据集,其中,a+b+c=1;
c2.在训练数据集中,以句子为单位,将一个含有n个字的句子记作:x=(x1,x2,...,xn),其中,xi表示句子的第i个字在字典中的id,根据xi得到每个字的word2id向量,其中,word2id是通过统计训练数据集的字符个数,并按此方法得到的字符数据集;在字符数据集中按字符出现频率降序进行编码,得到字符对应的唯一的id编号数据集word2id,其中,未在word2id中出现的字符id置0,用‘<unk>’标记;
c3.在实体识别模型的特征表示层利用预训练或随机初始化的向量矩阵将句子中的每个字xi由wordid向量映射为低维稠密的字向量,其中,xi∈r2;
c4.在实体识别模型的dropout层设置dropout以缓解过拟合,且dropout设置为0.5;
c5.将一个句子的各个字的字符向量序列(x1,x2,...,xn)作为idcnn层的输入,建立基于idcnn的深度学习模型,随机抽取batch_size进行参数训练,并将膨胀算子计算的卷积矩阵组合,采用dropout正则化模型参数,在每个批次的训练中将隐层神经元随机保留一半,得到每个字符对应的非归一化的对数概率logits值,其中,
在本实施例的idcnn层中,dilatedwidth会随着层数的增加而指数增加,这样随着层数的增加,参数数量是线性增加的,而receptivefield却是指数增加的,可以很快覆盖到全部的输入数据;
c6.在实体识别模型的crf层中进行句子级的序列标注,其中,crf层的参数是一个(k+2)×(k+2)的矩阵a,k是不同标签的数目,aij表示从第i个标签到第j个标签的转移得分,对每个句子的各标签进行打分,记一个长度等于句子长度的标签序列y即y=(y1,y2,...,yn),则对于句子x的标签y的打分为
作为优选,crf层可以为最后预测的标签添加一些约束来保证预测的标签是合法的,且在训练数据训练过程中,这些约束可以通过crf层自动学习到,有了这些约束,标签序列预测中非法序列出现的概率将会大大降低。
进一步地,所述步骤c1中,a=0.7,b=0.2,c=0.1。
进一步地,所述步骤e中,对预测结果的验证处理具体是将预测结果分为有实体及无实体两类,并分别进行预测结果无实体验证处理及预测结果有实体验证处理;其中,所述预测结果无实体验证处理包括去掉前后冗余部分和特定实体后再去搜索知识图谱得到对应的实体结果,若有对应实体结果则将其作为最终输出的预测结果,若无则进行模糊搜索;所述预测结果有实体验证处理包括将对应实体在搜索知识图谱中验证是否有真实存在对应的实体,若有,则将其作为最终的,若无,则转为预测结果无实体验证处理。
本发明与现有技术相比,具有以下的有益效果:
本发明的基于idcnn-crf与知识图谱的影视实体识别方法,通过对大量用户数据的分析、人工数据标注、模型训练;获取待识别文本的字符向量和词向量,对字符向量和词向量进行加权求和,得到加权求和结果;将加权求和结果输入至idcnn模型中进行处理,得到文本特征序列;将文本特征序列输入至目标crf模型中进行处理,得到待识别文本的命名实体识别结果;将命名实体识别结果去影视知识图谱中查询进一步验证结果,避免不合逻辑的实体结果,其中,获取待识别文本的字符向量和词向量之后,通过对字符向量和词向量进行加权求和,更好的利用了字符特征和词特征信息,通过采用膨胀的卷积神经网络模型尽可能记住全句的信息来对当前字做标注,再结合crf模型进行处理及知识图谱的实体验证,从而提高了命名实体识别的准确率,可以实现从大规模、表达口语化的语音文本中准确高效地提取实体,有助于用户在电视端进行影视实体的搜索,提高用户体验。
附图说明
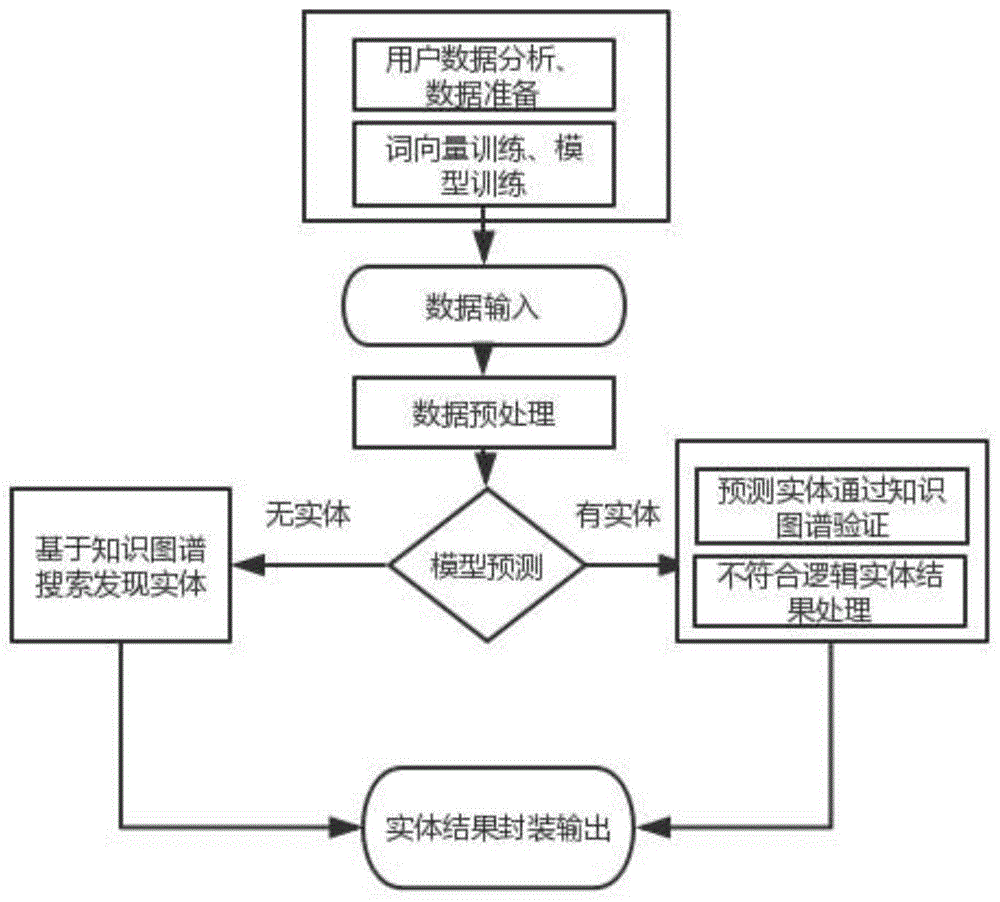
图1是本发明的基于idcnn-crf与知识图谱的影视实体识别方法流程示意图。
图2是本发明的一个实施例的实体识别模型的结构示意图。
具体实施方式
下面结合本发明的实施例对本发明作进一步的阐述和说明。
实施例:
实施例一:
现用比较多的实体识别方法都是基于bilstm,bilstm本质是一个序列模型,但在对gpu并行计算的利用上不如cnn那么强大,且在应用于线上系统时,随着用户增多,对模型训练及预测时间要求也比较高,在高并发下模型的性能、处理时间尤为重要,本实施例即提供了一种基于idcnn-crf与知识图谱的影视实体识别方法,其idcnn-crf模型在训练及预测时间均优于bilstm+crf,能够解决标注数据少及文本简短、口语化的影视文本数据的实体识别问题。
具体的,如图1所示,本实施例的基于idcnn-crf与知识图谱的影视实体识别方法包括以下步骤:
步骤1.从各大影视数据源实时收集影视数据信息,如,豆瓣、百度百科等,爬取各影视名、演员、角色、人物关系等各实体信息,建立影视专用的知识图谱。
步骤2.从电视端收集通过语音转换为文本的用户搜索影视的数据;分析收集到的数据,对有一定规律的(指用户常用的搜索影视的句式)、用户常用的搜索语句打标签,用于训练模型并进行词向量训练。
具体包括从大量采集到的用户数据中通过k-means聚类、频次、用户行为数据等分析用户影视搜索的基本需求,如常用搜索句式、按什么条件搜索视频等,结合业务需求,确定实体类别及命名;然后人工按bio标准标注训练数据,由于没现成可用的标注数据,利用大量用户真实数据及word2vec语言模型训练100维度的字符向量及分词向量,并按一定权重拼接文本的字符向量和词向量,作为双向idcnn的底层输入。
具体的,本实施例中,对从电视端采集的大量用户数据做频次统计、k-means聚类分析,经过测试调参本实施例中选择15个聚类点,会将用户说法意图相似的语句聚类到一起结合频次分析及聚类分析的结果,大概预知用户常用的影视搜查语句,确定要识别的实体类型、标签统一命名,本实施例中,目前有27个标签。
其中,词向量训练前需要对数据进行预处理,包括去除特殊标点符号、英文大小写转换等,再将处理后的数据大量用户规范数据使用gensim工具包的word2vec训练,训练为维度100维的字符向量;词向量对句子进行结巴分词并编码,例如“我/想/看/刘德华/的/天下无贼,编码为“0/0/0/123/0/1223”,最后将词向量与word2vec训练出的字符向量按一定权重相加,最终得到词向量作为双向idcnn网络的初始参数。
作为优选,在词向量训练中还涉及到对于分词的优化,比如‘流淌的美好生活’结巴分词不会记录这是影片名为一组分词结果,本方案将热门影片作为结巴的自定义字典,这样提高分词和实体识别的效果。最后再将词向量和字符级向量进行拼接作为词向量层。
本方案中,用大量真实数据训练的词向量一定程度上解决了标注数据少的情况下使用深度神经网络做实体识别的问题,idcnn神经网络的初始参数不再是没有意义的随机参数,大量数据训练的词向量会得到中文字偏旁等初始信息作为神经网络的底层输入,本方案还加入了优化后的词向量,一句话中一个单独的字符可能没有实际意思,而正确的分词向量却对整句话起着重要作用,将字符向量和词向量结合更能体现文本的整体特征。
步骤3.进行实体识别模型的训练。
具体的,如图2所示,本实施例中,实体识别模型主要由嵌入层、dropout层、idcnn层和crf层4部分构成。
其中,嵌入层(即特征表示层):主要由词向量和字符向量组成;字符向量是通过lm模型训练得到的100维向量,词向量对句子进行结巴分词并编码,例如“我/想/看/刘德华/的/天下无贼,编码为“0/0/0/123/0/1223”。
dropout层主要用于在特征输入idcnn网络层之前做随机失活dropout,从而一定程度缓解过拟合。
idcnn层具体是对输入的特征分别编码当前时刻的上文和下文信息;再将两者的编码信息合并构成待解码的得分信息。本模型是4个大的相同结构的dilatedcnnblock拼在一起,每个block里面是dilationwidth为1,1,2的三层dilated卷积层,所以叫做iterateddilatedcnn,idcnn对输入句子的每一个字生成一个logits值作为待解码的得分信息。
crf层则是用于接受idcnn的输出得分作为输入,同时引入转移得分矩阵,根据序列得分选择全最优的标签序列。
具体的,在进行模型训练时,具体包括以下步骤:
先将所有标注的训练数据按0.7、0.2、0.1的比例划分为训练数据集、测试数据集和验证数据集。其中,测试数据集和验证数据集分别是用于对模型的测试及对于测试结果的验证,具体的测试及验证过程类似于模型的训练过程,且本方案的重点在于对模型的训练过程,因此对于模型的测试及验证此处不再赘述。然后以句子为单位,将一个含有n个字的句子(字的序列)记作:x=(x1,x2,...,xn);其中,xi表示句子的第i个字在字典中的id,根据xi得到每个字的word2id向量,其中,word2id是通过统计训练数据集的字符个数,并按此方法得到的字符数据集;在字符数据集中按字符出现频率降序进行编码,得到字符对应的唯一的id编号数据集word2id,其中,未在word2id中出现的字符id置0,用‘<unk>’标记。
模型的第一层是嵌入层(特征表示层),利用预训练或随机初始化的embedding矩阵将句子中的每个字xi由wordid向量映射为低维稠密的字向量(characterembedding),xi∈r2是embedding的维度。
模型的第二层是dropout层,在输入下一层之前,设置dropout以缓解过拟合,本实施例中dropout设置为0.5。
模型的第三层是idcnn层,正常cnn的filter,都是作用在输入矩阵一片连续的区域上,不断sliding做卷积。而dilatedcnn为这个filter增加了一个dilationwidth(膨胀宽度),作用在输入矩阵的时候,会skip所有dilationwidth中间的输入数据;而filter本身的大小保持不变,这样filter获取到了更广阔的输入矩阵上的数据,看上去就像是“膨胀”了一般。则具体使用时,dilatedwidth会随着层数的增加而指数增加。这样随着层数的增加,参数数量是线性增加的,而receptivefield却是指数增加的,可以很快覆盖到全部的输入数据。
最终,将一个句子的各个字的字符向量序列(x1,x2,...,xn)作为idcnn层的输入,建立基于idcnn的深度学习模型,随机抽取batch_size进行参数训练,并将膨胀算子计算的卷积矩阵组合,采用dropout正则化模型参数,在每个批次的训练中将隐层神经元随机保留一半,得到每个字符对应的非归一化的对数概率logits值,其中,
模型的第四层是crf层,进行句子级的序列标注。crf层的参数是一个(k+2)×(k+2)的矩阵a,k为句子中一个字的向量的长度,如本实施例中,k=100;aij表示从第i个标签到第j个标签的转移得分,进而在一个位置进行标注的时候可以利用此前已经标注过的标签,之所以要加2是应为要为句子首部添加一个起始状态以及为句子尾部添加一个终止状态,对每个句子的各标签进行打分,记一个长度等于句子长度的标签序列y=(y1,y2,...,yn),则对于句子x的标签y的打分为
crf层可以为最后预测的标签添加一些约束来保证预测的标签是合法的。作为优选,在训练数据训练过程中,这些约束可以通过crf层自动学习到,有了这些约束,标签序列预测中非法序列出现的概率将会大大降低,由于idcnn的输出为单元的每一个标签分值,我们可以挑选分值最高的一个作为该单元的标签。
具体的,在实施例中,模型训练主要分为以下3部分:
第一,输入字/词向量表示。
使用wordid向量表示每个字符,分词向量按‘0/1/2/3’方式编码,例如“我/想/看/刘德华/的/天下无贼,编码为“0/0/0/123/0/1223”。将从单个字(单个字母)中提取一些含义,从词向量中获取句子及部分上下文的含义。对每一个字,需要构建一个向量来获取这个字的意思以及对实体识别有用的一些特征,本方案中这个向量由word2vec训练的字向量和从词向量中提取出特征的向量按权重堆叠而成的。
第二,上下文字的语义表示。
对上下文中的每一个字,需要有一个有意义的向量表示。使用idcnn来获取上下文中字的向量表示。利用idcnn的膨胀机制,可以迅速的扫描获取输入文本每个字的上下文信息。
第三,进行实体标签的预测。
这一阶段计算标签得分,使用每个字对应的logits来做最后预测,可以使用一个全连接神经网络来获取每个实体标签的得分。记一个长度等于句子长度的标签序列y=(y1,y2,...,yn),则对于句子x的标签y的打分为
本实施例中,具体使用了线性crf给实体标签的得分:softmax方法是做局部选择,没有利用周围的标签来帮助决策。例如:“张三”,当我们给了三“i-actor”这个标签后,这应该帮助我们决定“张”对应i-actor的起始位置。线性crf定义了全局得分。最后,将训练的模型及相应参数保存。
步骤4.采集需要进行预测的预测数据,并在进行数据预处理。
数据预处理时主要是去特殊符号等;将文本数据处理为模型预测要求的格式,即将文本转换为wordid词向量,维度是训练数据词库字典的长度。
步骤5.进行模型预测。
将处理后的数据输入经训练的模型进行预测,预测结果可能的情况如下:
(1)、看张二谋导演的红x粱
ob-directori-directori-directoroob-movie_namei-movie_namei-movie_name
(2)、刘小四的大话x游
b-actori-actori-actorob-movie_namei-movie_namei-movie_name
(3)、张三那期的快乐x本营
b-actori-actorooob-movie_namei-movie_namei-movie_namei-movie_namei-movie_name
(4)、王二可不可以不悲伤
oooooob-movie_namei-movie_namei-movie_name
(5)、钱某参加的综艺
ooooooo
步骤6.预测结果的验证与处理。
具体包括预测结果无实体处理及预测结果有实体验证处理。其中,如对于上述第(5)种预测结果即没有预测出实体情况处理方法如下:
首先,进行数据处理,去除前后冗余部门‘我想看’,‘我要看’、‘播放’、‘有吗’等,然后再对film集/季/部、版本、语言等实体规则提取,由于事先维护了语言、版本、国家等不长变动这些数据同时在存于知识图谱,类似{‘英语’:‘英语’,‘英文’:‘英语’,‘外语’:‘英语’}形式,会将其所有同义词考虑在内。将对应的实体用正则匹配后并将实体替换为空,如‘我想看速度与xx英文版’,如果模型没有预测实体结果,去掉前后冗余部分和特定实体后‘速度与激情英’再去搜索知识图谱得到对应的实体结果。如果还没找到实体会分词后再模糊搜索。
如对于上述第(1)、(2)、(3)、(4)种预测结果即有实体结果标签处理方法如下:
将对应实体搜索知识图谱验证是否有真实存在这样的实体,如(2)中刘小四实际没有演过大话x游,将向用户推荐刘小四的其他电影,而不是返回用户没找到该影片。预测结果(3)实际用户张三最新一期参加的快乐x本营节目,此是实体抽象关系的挖掘,能够更好的满足用户需求。知识图谱验证进一步提高了实体的效果。对(4)这种虽然有实体结果,但在知识图谱中没找到对应的影视名称实体视为预测失败,再执行预测结果没实体处理。
步骤7.实体结果封装输出。
本步骤中还包含对不符合逻辑的实体预测结果处理,如对于‘刘某华第三集’的识别结果为actor:刘某华,season:;则在结果输出时会将删除season实体,将“刘某华”作为识别结果封装。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 情绪向量的生成方法及装置与流...
- 基于信息熵识别新词的方法、装...
- 一种组词方法、装置、电子设备...
- 基于CNN双向GRU注意力机...
- 一种文本内容检测方法、检测装...
- 数据监控方法、装置、设备及计...
- 一种基于词汇统计的学习软件系...
- 一种汉语选词填空方法与流程
- 一种基于主题模型的在线评论情...
- 文本情感分析模型训练方法、装...
- 还没有人留言评论。精彩留言会获得点赞!