基于孪生网络和多头注意力机制的语义相似度匹配方法与流程
本发明属于自然语言处理问答系统领域,提供了一种基于孪生网络和多头注意力机制的语义相似度匹配方法。
背景技术:
句子对语义匹配的任务是对比两个句子,并确定句子之间的关系,它在自然语言处理的很多工作中都有应用,比如说问答系统、文本复述判别和文本语义推断等。这些不同的场景中,相同点都是要确定两个句子的关系,不同点是句子的关系不尽相同。在文本复述判别中,语义匹配用于判断句子对是否表达语义相同,句子间是并列关系;在文本语义推断中,语义匹配用于判断前提能不能推导出假设,句子间是因果关系;在问答系统答案选择中,语义匹配用于寻找与问题最相关的答案,句子间是解释关系。
在这些不同的关系中,我们将其分为两类,一类是前后关系,比如因果关系、解释关系;一类是对等关系,比如并列关系。前后关系句子对描述的一般不是同一件事,只是这两件事之间存在关联;而对等关系句子对描述的一般是同一件事或者很类似的事情。这两种关系在描述的时候会存在一个明显的差异:前后关系的句子对描述使用的关键词汇相同的比例低,对等关系的句子对描述使用的关键词汇相同的比例高。
将语义匹配的任务划分为这两种场景实际上之前从没有被提及。在深度学习之前,句子对匹配早期的方法侧重于词汇语义、表面形式匹配和基本的句法相似性。目前深度学习方法针对句子对匹配的现有模型在建模的时候主要考虑两个关键因素,一个是如何区别两个句子之间语义上的差异,一个是如何构建两个句子之间的关联性。区分两个句子之间语义上的差异可以利用孪生网络的结构。孪生网络属于比较典型的结构,主要使用rnn(recurrentneuralnetwork,循环神经网络)或者cnn(convolutionalneuralnetworks,卷积神经网络)对两个句子分别进行编码,并且保证编码两个句子的模型参数一致,这样可以确保两个句子编码之后没有引入模型上的差异。构建两个句子之间的关联性可以利用匹配-聚合模型,使用rnn或者cnn对句子编码之后,使用注意力机制直接将两个句子进行交互,之后利用交互信息进行判断。目前在句子对匹配中取得比较好的工作的模型都会在孪生网络结构中采用注意力机制,差别在于如何使用不同的编码模块、不同的交互方式等等。例如,在esim(enhancedlstmfornaturallanguageinference,专为自然语言推断而生的加强版lstm)中,使用rnn构建了孪生网络,在此基础上,利用注意力机制添加两个句子交互信息,再次利用rnn进行句子编码。在abcnn(attentionbaesdconvolutionalneuralnetworks,基于注意力的卷积神经网络)中,使用cnn构建了孪生网络,之后同样利用多种注意力机制构建交互信息,它的特色在于利用注意力机制改变了卷积、池化的基本操作,获得了更好的句子表示。也有像matchpyramid(匹配金字塔)这种匹配-聚合模型主要考虑交互信息,它受到图像识别的启发,首先构造两个句子的相似度矩阵,接着在矩阵上利用卷积提取特征。我们会同时考虑两个句子之间语义上的差异、两个句子之间的关联性,但是我们使用的方式与现有的方式不太相同。我们提出模型snma(siamesenetworkcooperatingwithmulti-headattention,基于孪生网络和多头注意力机制的语义相似度匹配方法),它使用双向gru构建孪生网络分别对两个句子嵌入进行编码,之后对编码信息利用jaccard距离进行信息聚合;同时,我们利用多头注意力机制将两个句子的信息进行交互,最终将交互信息与孪生网络得到的聚合信息进行融合,这样的模型在四个中文数据集上得到了有效性证明。
技术实现要素:
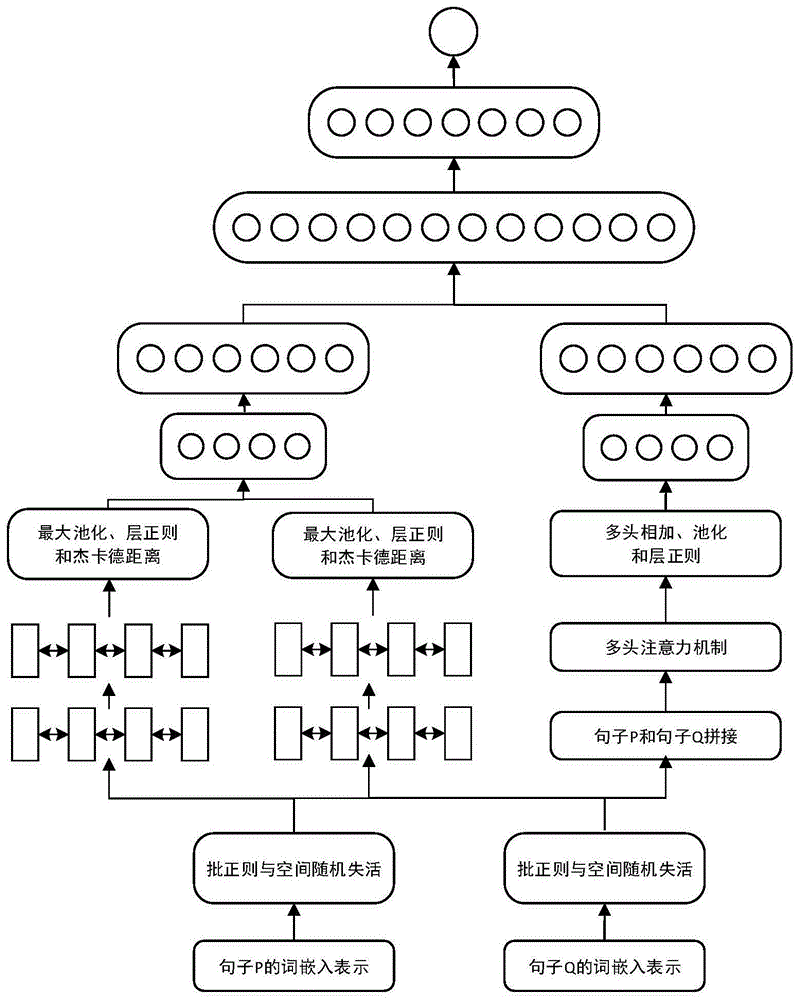
本发明提出基于孪生网络和多头注意力机制的语义相似度匹配方法。我们提出模型snma,它使用双向gru构建孪生网络分别对两个句子嵌入进行编码,之后对编码信息利用杰卡德距离进行信息聚合;同时,我们利用多头注意力机制将两个句子的信息进行交互,最终将交互信息与孪生网络得到的聚合信息进行融合。
本发明的技术方案:
基于孪生网络和多头注意力机制的语义相似度匹配方法,步骤如下:
步骤一:使用结巴(jieba)分词对语料的所有句子进行分词处理。
步骤二:使用word2vec在语料的所有句子上进行字、词的词向量的训练。
步骤三:按序输入句子对:长度为m的p={p1,p2,···,pm}和长度为n的q={q1,q2,···,qn}。
步骤四:对句子进行词嵌入编码
在步骤二预训练完成的word2vec模型中提取对应的字/词向量,将每个句子的词向量扩充为字向量的长度,扩充的办法是每个词中有几个汉字,该词对应的词向量就复制几遍,从而得到与字向量序列长度一致的词向量序列。在训练的过程中,我们发现如果保持嵌入层可训练,可能会导致模型过拟合,因此我们将是否可训练参数设置为否,这样实际上也减少了训练集和测试集之间字/词向量的差异。通过嵌入层,我们将数据的维度变为vp∈rm×d和vq∈rn×d,d是字或者词向量的维度,在这里为了保证字和词向量可融合,我们在预训练阶段将字和词向量大小d都设置为300。
步骤五:使用批正则和空间随机失活进行句子编码的正则化
将两个句子vp∈rm×d和vq∈rn×d通过一层批正则和空间随机失活,在这里的空间随机失活是tompson等人在图像领域提出的一种随机失活方法。普通随机失活是随机独立地将部分元素置零,空间随机失活则是随机地将某个维度的元素全部置零。一般来讲字/词向量中的不同维度代表不同的语义,通过不同维度的置零,我们可以获得不同语义信息的组合。
步骤六:使用两层双向gru对句子进行编码
将获得的
其中,
步骤七:利用池化层提取特征,缩小维度
采用全局平均池化和全局最大池化,计算如下式所示:
其中,
其中,viq表示句子q第i个字/词的向量表示,
步骤八:使用层正则对编码后的句子向量进行正则化
在池化操作之后采用了层正则,这有利于我们更好地优化和获得更好的结果。层正则中同层神经元输入拥有相同的均值和方差;而批正则中则针对不同神经元输入计算均值和方差,同一个小批次中的输入拥有相同的均值和方差。实践证明,层正则用于rnn进行正则时,取得了比批正则更好的效果。层正则的计算公式如下所示:
其中,ui表示第i层所有神经元的均值;j表示第j个神经元;xij表示第i层的第j个神经元的数值;σi表示第i层所有神经元的标准差;
步骤九:使用jaccard距离将两个句子不同表示信息融合
获得了池化和正则后的
其中,vmax表示全局最大池化后的两个句子利用jaccard距离计算公式求得的距离,vavg表示全局平均池化后的两个句子利用jaccard距离计算公式求得的距离。;f(·)表示杰卡德距离计算公式;xi表示句子p在维度i的数值;yi表示句子q在维度i的数值
步骤十:拼接步骤九中不同表示方法的句子信息,并使用relu激活
之后我们将两者拼接在一起获得vconcated=concat(vmax;vavg)(15-1)
并利用激活函数relu进行激活:
vmerged=relu(vconcated)(15-2)
其中,vmerged是利用孪生网络获得的句子融合表示,这个表示将用来跟接下来的多头注意力机制获得的融合信息进行再融合。
步骤十一:将步骤五两个编码后的句子信息拼接
将嵌入层的两个结果
步骤十二:使用多头注意力机制对上述步骤十一拼接句子进行自编码
之后就是要将该表示通过多头注意力机制来获得两个句子的交互信息。多头注意力机制目前广泛应用于nlp各种课题。文中采用的的注意力机制主要是自注意力机制,即论文中提到的“scaleddot-productattention”,计算公式如下:
多头注意力机制可以针对不同的位置利用不同的注意来表示,可以获得更好的语义信息表示,有效的防止过拟合,多头注意力机制通过自自注意力机制的不同权重构造不同表示,达到多头的目标。多头注意力机制的计算公式如下:
vinter=multi-head(q,k,v)=concat(head1,head2,…,head8)wo(18)
headi=attention(qwiq;kwik;vwiv)(19)
其中,请补充字母含义:q表示一个句子表达,k表示该句子的关键信息,v表示另一个句子的表达、dk表示缩放因子、vinter是进过多头注意力机制表达之后的句子、head1,head2,…,head8表示每个头表示下的句子信息、wo表示拼接多头注意力机制时不同头表示的权重、wiq句子表达q上的第i个权重、wik句子关键信息k上的第i个权重、wiv句子表达v上的第i个权重。
步骤十三:利用池化层提取步骤十二的特征,缩小维度
同时采用全局平均池化和全局最大池化,池化的结果应当使得句子的表示大小等同于比较模块最终获得的结果,计算公式如下:
其中,viinter表示句子表示vinter的第i个单词的表示,m表示句子的长度,
步骤十四:拼接步骤十三不同表示方法的句子信息,并使用relu激活
将两个池化结果进行拼接
其中,vinter拼接了最大池化和平均池化后的句子表示。
步骤十五:拼接步骤十和步骤十四的句子信息
我们将比较模块和交互模块拼接,获得一个融合了两个句子的最终表示:
vall=concat(vmerged;vinter)(23)
其中,vall表示拼接了利用孪生网络获得的句子融合表示和利用多头注意力机制获得的句子交互表示。
该表示既有重点关注句子间差异的语义信息,也有关注句子间交互的语义信息,
步骤十六:输入全连接和最后的sigmoid函数,得到结果
损失函数和评价指标
损失函数在本文中我们采用的损失函数是交叉熵损失,计算公式如下式:
评价指标我们的观测指标主要是f1值:
(1)precisionrate=tp/(tp+fp)
(2)recallrate=tp/(tp+fn)
(3)accuracy=(tp+tn)/(tp+fp+tn+fn)
(4)f1-score=2*precisionrate*recallrate/(precisionrate+recallrate)
其中truepositive(tp)意思表示做出同义的判定,而且判定是正确的,tp的数值表示正确的同义判定的个数;同理,falsepositive(fp)数值表示错误的同义判定的个数;
依此,truenegative(tn)数值表示正确的不同义判定个数;falsenegative(fn)数值表示错误的不同义判定个数。
本发明的有益效果:(i)我们提出了将句子对的比较和融合分开训练再融合的模型snma;(ii)我们首次将多头注意力机制用在了语义相似度匹配工作中;(iii)我们在四个中文语义相似度数据集中验证了我们工作的有效性。
附图说明
图1为基于孪生网络和多头注意力机制的语义相似度匹配模型。
图2为基于孪生网络和多头注意力机制的语义相似度匹配方法网络结构示意图。
具体实施方式
下面将结合具体实施例对本发明的技术方案进行进一步的说明。
我们分别使用word2vec训练了文本中字和词的向量表示,每个向量的维度都是300维。未登录词和padding词采用随机初始化的固定向量。在embedding阶段我们会对使用分词后序列化的句子进行扩长,将每个词语复制一定倍数,倍数等于该词语包含的字的个数,之后我们可以对词向量和字向量进行融合。spatialdropout的比例值设置为0.2。embedding阶段之后我们将字向量连续输入两个双向gru,第一个gru的隐藏层维度为384,第二个gru的隐藏层维度为256。注意力机制共有8个,每个注意力机制单词维度的大小为16。激活函数采用relu。为了训练模型我们使用了nadam优化器,学习率设置为0.0008。训练过程中,我们采用了学习率下降措施。同时为了获得更好的实验效果,我们采用了早停训练方法。
atec数据集
数据集源于蚂蚁金服提供的“atecnlp之问题相似度计算”比赛,所有数据均来自蚂蚁金服金融大脑的实际应用场景。问题相似度计算,即给定客服里用户描述的两句话,用算法来判断是否表示了相同的语义。比赛提供10万对的标注数据,作为训练数据,包括同义对和不同义对。数据集中每一行就是一条样例。格式如下:
表1atec数据集的样例
行号指当前问题对在训练集中的第几行,句1和句2分别表示问题句对的两个句子,标注指当前问题对的同义或不同义标注,同义为1,不同义为0。
我们将10万对的标注数据按照9:1的比例划分为训练集和测试集,并在训练集中按照8:2的比例划分训练集和验证集。
表2不同模型在atec数据集上的表现
针对atec数据集不同模型实验数据如上表格所示。所有的模型都没有额外使用手工特征。表格中除了我们自己设计模型外,另外5个模型都是摘录自在英文数据集中获得比较好的成绩的模型。我们根据这些模型的原论文进行复现并在atec数据集上进行训练以获得比较好的结果。我们设计的模型在该数据集上取得了比其他模型都要好的结果。
表3模型各部分取舍在atec数据集上的表现
在该数据集中,将字向量换成词向量可以发现f1值会下降很多,直接从53.92下降至41.08,这说明了字编码对于模型是至关重要的,也说明了我们预训练的词向量的质量不高,这个可能跟中文分词本身的难度有关,也跟jieba分词质量有关;我们将字向量与词向量相结合之后使用,虽然没有获得比原始模型好的结果,但是要比单一词向量模型要好,只是词向量质量太差,所用影响了模型的最终结果;针对模型最后的池化取舍发现,最大池化明显没有平均池化在数据集中的作用大;我们在模型中对句子的编码使用了两层双向lstm,如果只使用一层的话,确实会影响到最后的结果,说明两层编码是有效的;在最后,我们发现句子交互阶段的多头注意力机制有助于提高模型效果,只是由于句子之间本身的相似性所以交互作用可能比较小。考略到实验的重复性和论文的目标,我们下面的实验将重点关注多头注意力机制取舍的影响。
ccks数据集
数据集源于ccks2018微众银行智能客服问句匹配大赛,所有数据均都是主要来自金融领域的真实文本。本次评测任务的主要目标是针对中文的真实客服语料,进行问句意图匹配。集给定两个语句,要求判定两者意图是否相同或者相近。所有语料来自原始的银行领域智能客服日志,并经过了筛选和人工的意图匹配标注。比赛提供10万对的标注数据,作为训练数据,包括同义对和不同义对,可下载。数据集中每一行就是一条样例。格式如下:
行号指当前问题对在训练集中的第几行,句1和句2分别表示问题句对的两个句子,标注指当前问题对的同义或不同义标注,同义为1,不同义为0。
我们将10万对的标注数据按照9:1的比例划分为训练集和测试集,并在训练集中按照8:2的比例划分训练集和验证集。
表4ccks数据集的样例
表5不同模型在ccks数据集上的表现
针对ccks数据集不同模型实验数据如上表格所示。所有的模型都没有额外使用手工特征。同atec数据集中使用的模型一样,表格中除了我们自己设计模型外,其余5个模型都是摘录自在英文数据集中获得比较好的成绩的模型。我们根据这些模型的原论文进行复现并在ccks数据集上进行训练以获得比较好的结果。我们设计的模型在该数据集上取得了比其他模型都要好的结果。实验分析如表6:
表6模型取舍在ccks数据集上的表现
上表可以发现多头注意力机制存在句子交互作用。
ppdai数据集
数据集源于拍拍贷第三届魔镜杯大赛,此次提供智能客服聊天机器人真实数据。智能客服聊天机器人场景中,待客户提出问题后,往往需要先计算客户提出问题与知识库问题的相似度,进而定位最相似问题,再对问题给出答案。本次比赛的题目便是问题相似度算法设计。比赛提供25万对的标注数据,作为训练数据,包括同义对和不同义对。格式如下:
表7ppdai数据集的样例
我们将25万对的标注数据按照9:1的比例划分为训练集和测试集,并在训练集中按照8:2的比例划分训练集和验证集。
表8不同模型在ppdai数据集上的表现
针对ppdai数据集不同模型实验数据如上表格所示。所有的模型都没有额外使用手工特征。同atec数据集中使用的模型一样,表格中除了我们自己设计模型外,其余5个模型都是摘录自在英文数据集中获得比较好的成绩的模型。我们根据这些模型的原论文进行复现并在ccks数据集上进行训练以获得比较好的结果。我们设计的模型在该数据集上的验证集f1值取得了比其他模型都要好的结果,但是在测试集中略微逊色于模型matchpyramid,不过我们的参数量要远小于matchpyramid。
表9模型取舍在ppdai数据集上的表现
观察表9,多头注意力机制存在句子交互作用。
chip数据集
数据集源于第四届中国健康信息处理会议(chip),本次评测任务的主要目标是针对中文的真实患者健康咨询语料,进行问句意图匹配。给定两个语句,要求判定两者意图是否相同或者相近。所有语料来自互联网上患者真实的问题,并经过了筛选和人工的意图匹配标注。官方提供了训练集包含20000条左右标注好的数据(经过脱敏处理,包含标点符号),包含若干对由问题id组成的pair。以label表示问句之间的语义是否相同。若相同,标为1,若不相同,标为0。其中,训练集label已知,测试集label未知。
表10chip数据集的样例
本实验数据集过小,不再适合划分测试集,因此这里的实验结果只展示了验证集结果。
表11不同模型在chip数据集上的表现
针对chip数据集不同模型实验数据如上表格所示。所有的模型都没有额外使用手工特征。同atec数据集中使用的模型一样,表格中除了我们自己设计模型外的5个模型都是摘录自在英文数据集中获得比较好的成绩的模型。我们根据这些模型的原论文进行复现并在ccks数据集上进行训练以获得比较好的结果。我们设计的模型在该数据集上要比esim结果略微差一点,但是我们的参数量只有esim的一半左右。实验分析如表12:
表12模型各部分取舍在ccks数据集上的表现
从上表可以发现,句子交互阶段的多头注意力机制可以提升模型实验结果。
我们针对中文数据集文本相似度匹配提出了新的模型,实验表明我们的模型在这些数据集中取得了比较理想的结果。我们的模型主要分为两个方面,一个模块是利用双向gru构建了孪生网络来提取句子之间的差异,另一个模块则是利用多头注意力机制来获取两个句子之间的交互。我们发现在中文短句子匹配情况下,比较复杂的模型反而没有取得较好的成绩,而是利用双向gru构建的简单孪生网络取得了比较好的结果,考虑到单纯的孪生网络没有能够引入句子之间的交互信息,因此额外使用多头注意力机制来进行句子之间的交互。我们认为句子之间的匹配既离不开句子之间的差异性,也离不开句子之间的相似性,有效合理地匹配句子需要多角度地比较。
- 一种基于关联语义链网络的新闻...
- 一种基于矩阵形式的文本表示方...
- 药品信息匹配处理方法、装置、...
- 一种文本处理方法、装置、系统...
- 文本分类方法和装置与流程
- 一种信息处理方法、装置、计算...
- 文档验收方法、装置、计算机设...
- 基于机器智能的题库生产方法及...
- 一种智能IETM故障维修记录...
- 基于百科知识库和词向量的中文...
- 还没有人留言评论。精彩留言会获得点赞!