一种面向复杂数据的快速搜索和寻找密度峰值的聚类算法的制作方法
本发明涉及大数据分析领域的聚类算法,尤其涉及一种面向复杂数据的快速搜索和寻找密度峰值的聚类算法。
背景技术:
密度峰值聚类算法(clusteringbyfastsearchandfindofdensitypeaks,dpc)由alexrodriguez和alessandrolaio于2014年提出,并将论文发表在science上。因其算法原理简单、运行高效、无需迭代计算目标函数即可快速找到密度峰值点(聚类中心)、适用于大规模数据集的聚类分析等特点,提出后就受到学者的关注,并在在图像处理、社区网络发现、基因序列重组、旅行社问题等得到了广泛应用,但dpc算法在处理复杂数据集时难以正确寻找密度峰值点,并且在分配时易出现分配连带错误的缺点,限制了dpc的实际应用。
技术实现要素:
发明目的:针对现有技术中存在的问题,本发明提供一种面向复杂数据的快速搜索和寻找密度峰值的聚类算法(afastclusteringalgorithmforsearchingandfindingdensitypeaksforcomplexdata,fca-sfdpcd),以解决在处理多尺度、交叉缠绕和流型的复杂数据集时无法找到正确密度峰值点及分配方式容易出现错误连带问题等不足。
技术方案:一种面向复杂数据的快速搜索和寻找密度峰值的聚类算法,包括如下内容:
局部密度定义:
定义1累积近邻度πk:用于测量数据点i与其k近邻点的相似程度;
其中,knn(i)为数据点i的k个近邻点的集合,dij为数据点i与数据点j之间的欧式距离;所述k的取值为1-100。
定义2离心率ε:用于表示数据点i与其k近邻点的关联程度;
该值越大,说明数据点i与其k近邻点的关系越不紧密,为离群点的可能性越大;
定义3局部密度ρ:
分配策略:
定义4数据点的加权邻近度ω:
其中,ωij表示数据点i到数据点j的加权邻近度,
定义5数据点与微簇的相互邻近度ai→c,用于表示数据点属于微簇的权重:
所述数据点与微簇的相互邻近度越大,说明该微簇对该数据点的吸引度越大,该数据点越大概率属于该微簇;所述
定义6微簇与微簇的相互邻近度
所述
算法具体步骤如下:
输入:数据集data,样本近邻数k;
输出:聚类结果c;
步骤1:数据归一化;
步骤2:计算各数据点间欧式距离,计算数据点的局部密度ρ和相对距离δ值;
步骤3:计算数据点的决策值γ,选择出最终合成簇密度峰值点的集合cn和初始生成微簇密度峰值点的集合cm;
步骤4:计算数据点的加权邻近度矩阵;
步骤5:若cm≠cn,计算不含密度峰值点的微簇与含密度峰值点的微簇之间的簇间相互邻近度,否则结束聚类;
步骤6:合并相互邻近度最高的不含密度峰值点的微簇与含密度峰值点的微簇,转至步骤5。
进一步的,所述步骤2中,将数据点i的相对距离δi定义为数据点i与密度比它高且距离最近的数据点间的欧式距离,计算公式为:
进一步的,由于密度最高的数据点不存在密度比它高的数据点,对于密度最高的数据点,将其定义为最大值,计算公式为:
进一步的,所述步骤3中,决策值γ的计算公式为:
γi=ρi·δi
密度大且距离远的数据点为密度峰值点,即决策值γi较大的点为密度峰值点;在找到密度峰值点后,将其余数据点分配给密度比它高的最近的数据点。
和现有技术相比,本发明具有如下显著优点:本发明通过样本与其k近邻样本的距离定义该样本的离心率,再通过该样本与其k近邻样本的离心率比较确定该样本局部密度,该增强了样本与其k近邻点的关系,新定义的ρ能更加客观地反映数据点的属性;此外,引入微簇合并的策略,首先使用密度峰值聚类分配策略将样本分为多个微簇,再计算样本间的加权邻近度,以此确定微簇间的相似程度,将相似程度最高的微簇依次合并,形成最终聚类。相比其他改进方法,fca-sfdpcd算法在处理各类型复杂数据集时能取得更好的聚类结果,仿真实验结果表明:fca-sfdpcd算法在多尺度、交叉缠绕和流型的复杂数据集中能正确找到密度峰值点,并能对其余样本进行正确的分配,聚类精度得到较高提升。
附图说明
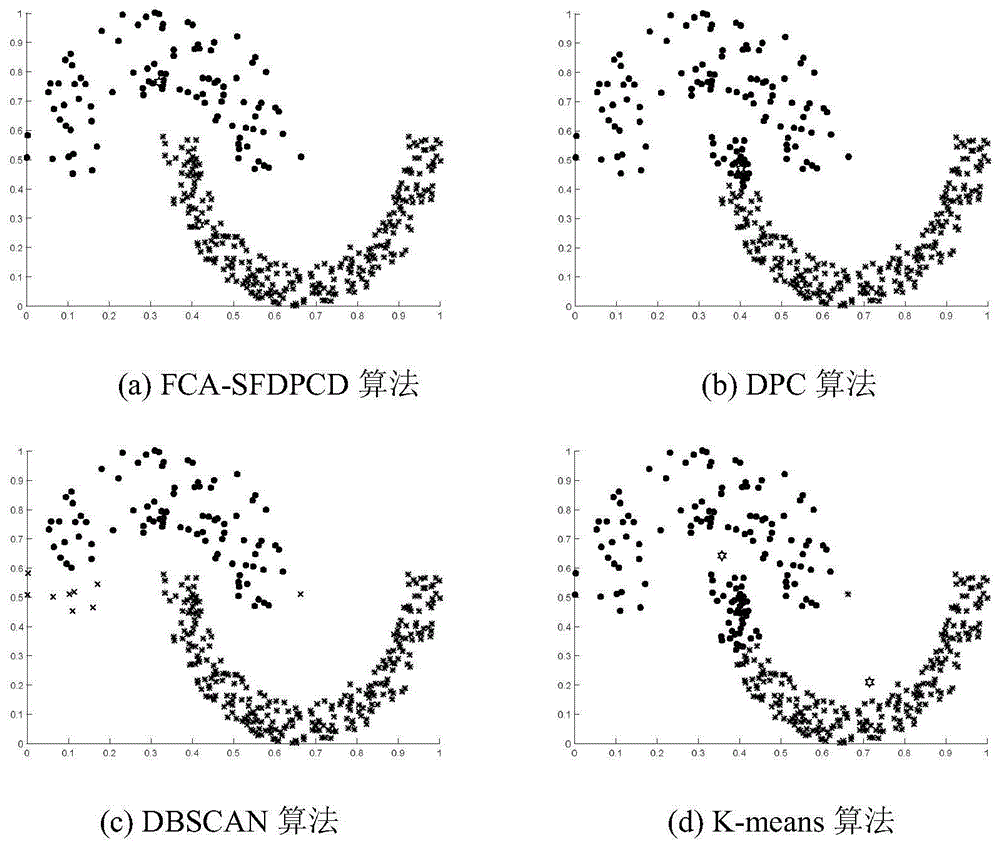
图1(a)-1(d)为fca-sfdpcd算法、dpc算法、dbscan算法、k-means算法对jain数据集的聚类结果;
图2(a)-2(d)为fca-sfdpcd算法、dpc算法、dbscan算法、k-means算法对pathbased数据集聚类结果;
图3(a)-3(d)为fca-sfdpcd算法、dpc算法、dbscan算法、k-means算法对aggregation数据集的聚类结果;
图4(a)-4(d)为fca-sfdpcd算法、dpc算法、dbscan算法、k-means算法对flame数据集的聚类结果;
图5(a)-5(d)为fca-sfdpcd算法、dpc算法、dbscan算法、k-means算法对r15数据集的聚类结果;
图6(a)-6(d)为fca-sfdpcd算法、dpc算法、dbscan算法、k-means算法对spiral数据集的聚类结果;
图7(a)-7(d)为fca-sfdpcd算法、dpc算法、dbscan算法、k-means算法对s2数据集的聚类结果。
具体实施方式
下面结合具体实施例,进一步阐明本发明的技术方案。
密度峰值聚类算法是一种基于密度的聚类算法,它既能找到各簇的密度峰值点,对各簇进行聚类,又能够排除离群点。并且该算法不受微簇的形状和大小的影响。dpc算法基于这样的假设:(1)簇中心被簇中其他密度较低的数据点包围;(2)簇中心之间的相对距离较远。故为了找到每个簇的密度峰值点,dpc算法引入两个概念:(1)数据点i的局部密度ρi;(2)数据点i的相对距离δi。
对于数据点i的局部密度,dpc算法给出了两种度量方式:截断核和高斯核。截断核度量方式由公式(1)给出,高斯核度量方式由公式(2)给出。
其中,dij为数据点i到数据点j的欧式距离,dc为数据点的邻域截断距离。对于截断核,每当数据点i的dc范围内存在一个点,该点的局部密度就加一,即数据点i的局部密度为该点的dc邻域内数据点的个数。当两个数据点的dc邻域内数据点个数相同时,截断核认为这两个数据点的密度是相等的,这就忽略了dc邻域内数据分布因素对局部密度的影响,故dpc原文给出了高斯核定义局部密度用于解决该问题。
dpc算法将数据点i的相对距离δi定义为数据点i与密度比它高且距离最近的数据点间的欧式距离,计算公式如(3)所示。由于密度最高的数据点不存在密度比它高的数据点,对于密度最高的数据点,dpc将其定义为最大值,计算公式如(4)所示。
为了找到所有密度峰值点,dpc为每个数据点i定义了决策值γi,计算公式如(5)所示。
γi=ρi·δi(5)
dpc认为密度大且距离远的数据点为密度峰值点,即决策值γi较大的点为密度峰值点。在找到密度峰值点后,将其余数据点分配给密度比它高的最近的数据点。
一种面向复杂数据的快速搜索和寻找密度峰值的聚类算法(fca-sfdpcd),包括如下内容:
局部密度定义:
定义1累积近邻度πk:用于测量数据点i与其k近邻点的相似程度,由公式(6)给出,其中knn(i)为数据点i的k个近邻点的集合,dij为数据点i与数据点j之间的欧式距离。
定义2离心率ε:用于表示数据点i与其k近邻点的关联程度,该值越大,说明数据点i与其k近邻点的关系越不紧密,越有可能是离群点。由公式(7)给出。
定义3局部密度ρ:由公式(8)给出
根据公式(8)可知,数据点i的局部密度与该点的累积近邻度有关,该点的累积近邻度越大,其局部密度ρi越小。同时,其局部密度还与该点的k近邻点的累积近邻度之和有关,其k近邻点的累积近邻度之和越大,该点的局部密度也将增大。这样设计的局部密度的优势在于,它不仅与其k近邻的距离有关,而且它计算的密度为该点与其k近邻点的相对密度,这样更有利于找到稀疏簇的密度峰值点。
分配策略:
由式(6)-(8)计算数据点i的局部密度ρi,再由式(3)-(4)计算数据点的距离δi,通过式(5)计算决策值γi,对γ进行排序,选择前n个点作为最终生成簇的密度峰值点,选择前m(n≤m)个数据点作为微簇密度峰值点。通过实验发现,当微簇个数m到达一定个数时,初始生成微簇个数的多少对聚类结果影响不大。通过dpc的分配策略,即将非密度峰值数据点分配给密度比它高的最近的数据点,生成m个微簇,最后通过基于图形度连接的微簇合并策略实现微簇合并。
定义4数据点的加权邻近度ω:数据点的加权邻近度由公式(9)给出,ωij表示数据点i到数据点j的加权邻近度。
其中,
定义5数据点与微簇的相互邻近度ai→c:数据点与微簇的相互邻近度表示数据点属于微簇的权重,数据点与微簇的相互邻近度越大,说明该微簇对该数据点的吸引度越大,该数据点越大概率属于该微簇,由公式(10)给出。
其中,deg-(c)为微簇到数据点的邻近度,计算公式如(11)所示。deg+(c)为数据点到微簇的邻近度,计算公式如(12)所示。
定义6微簇与微簇的相互邻近度
其中,
通过公式(9)-(14)计算不含密度峰值点的微簇与含密度峰值点的微簇之间的簇间相互邻近度,再将相互邻近度最高的一个不含密度峰值点的微簇与含密度峰值点的微簇相融合,重复该操作直至微簇个数与最终要生成的簇的个数相同为止。这样合并微簇的优势在于:该合并策略不会将含有密度峰值点的两个簇合并在一起,充分发挥了dpc算法寻找到的密度峰值点的优势;
fca-sfdpcd算法详细步骤如下:
输入:数据集data,样本近邻数k
输出:聚类结果c
step1:数据归一化;
step2:计算各数据点间欧式距离,根据公式(8)和公式(3)-(4)计算数据点的ρ和δ值;
step3:根据公式(5)计算数据点的决策值γ,选择出最终合成簇密度峰值点的集合cn和初始生成微簇密度峰值点的集合cm;
step4:根据式(9)计算数据点的加权邻近度矩阵;
step5:若cm≠cn,根据式(10)-(14)计算不含密度峰值点的微簇与含密度峰值点的微簇之间的簇间相互邻近度,否则结束聚类;
step6:合并相互邻近度最高的不含密度峰值点的微簇与含密度峰值点的微簇,转至步骤5。
仿真实验
为验证fca-sfdpcd算法的有效性,使用经典的人工数据集和真实数据集测试其性能。将fca-sfdpcd算法与fknn-dpc、dpc、dbscan、optics、ap和k-means进行比较,其中dbscan和k-means算法为参照原文献使用matlab2016a编程实现,ap在python的sklearn库中实现,optics在python的pyclustering库中实现。dpc算法基于作者提供的源代码,但由于我们的数据集不包含噪声,因此删除“halo”部分。对于fknn-dpc算法,由于无法从论文作者处获得源代码,因此我们参照现有技术的原文献实现了该过程。所有结果都是经过参数调优后的最优结果。实验中使用的人工数据集和真实数据集分别在表1和表2中给出。
为更客观的反映各算法的实际结果,我们对每个算法进行参数调优,从而保证各算法的最佳性能。对于fca-sfdpcd算法及fknn-dpc算法我们选择k为1-100间的最优值。对于dpc算法,作者提出一个经验法则选择dc,即每个数据点所包含的相邻点个数控制在总数据点个数的1%到2%之间。通过实验发现,并不是所有数据都能在这个范围内取得最好的结果,我们修改这个百分比以获得最好的聚类效果。对于dbscan和optics算法,它们有ε和minpts两个参数,ε选择为0.01到1,步长为0.01;minpts选择为1到100,步长为1。对于ap算法,由于没有通用的规则来选择参数,所以我们把参数搜索上限设置为最大相似度的几倍,然后逐渐缩小搜索范围。k-means算法的唯一参数为正确数量的类簇,同时,由于k-means算法每次聚类结果可能不相同,所以我们对每个数据集进行50次聚类,取其中最好的结果。
表1人工数据集
表2真实数据集
表3为各算法对表1中所有人工数据集的聚类结果,表中arg-为各算法的最优参数值。对于fca-sfdpcd、fknn-dpc和传统dpc算法虽然均可以通过决策图决定聚类中心,但是对于部分数据集,通过该方法均无法获得正确的集群个数,所以我们人为指定类簇个数。
表3不同聚类算法在人工数据集上的性能
图1-7为各算法在二维人工数据集上聚类结果图,图中不同形状的点被分配给不同的簇。除dbscan外,其他聚类中心由六角星型表示,dbscan中的叉表示该算法确定的噪声点。
图1的jain数据集由两个月牙形的簇组成,下半部分为密集簇,上半部分簇较为稀疏,对于这种由稀疏簇与密集簇组成的数据集,fca-sfdpcd算法使用新的局部密度定义方式成功寻找到正确的密度峰值点,并且将该数据集成功聚类。而dpc算法由于无法正确的找到密度峰值点,使得dpc算法无法对该数据成功聚类。k-means算法将密集簇1中一部分数据分配给了较稀疏的簇2,这是由k-means算法只能发现球状的簇决定的。对于dbscan算法,它能成功对密集的簇1进行聚类,但是对于较稀疏的簇2,由于数据较稀疏,使得dbscan算法将稀疏的簇分成了两个簇,并将一个较远的点识别为噪声点。由表3的聚类结果发现,fca-sfdpcd算法能对该簇做到完美聚类,dbscan和optics算法虽然存在一些聚类错误,但是总体上达到了较好的聚类结果,而fknn-dpc、dpc、ap和k-means算法对该数据的聚类结果较差。
如图2所示,只有fca-sfdpcd算法可以同时找到pathbased数据集的类簇中心和正确的类簇数,dpc和k-means算法能够成功识别类簇中心,dbscan无法识别集群。虽然fca-sfdpcd和dpc算法发现的类簇中心相似,但聚类结果却有很大的差异,通过微簇合并策略,fca-sfdpcd算法大大缓解了dpc算法分配策略中的错误连带问题。从图2可以看出,dpc和k-means算法的聚类结果是相似的,但是导致这些样本点分配错误的原因是完全不同的。dpc出现的分配错误,导致dpc算法将大量簇3中的数据点分配给了簇1和簇2。而k-means算法产生这类现象的原因是因为k-means算法仅能识别球状的簇,该数据集不符合这个要求,故无法对其进行聚类。dbscan算法通过对数据点邻域进行分析,将局部区域内较稀疏的数据点定义为噪声点。由于簇3相对于其余两簇较为稀疏,dbscan算法将簇3的所有点都定义为噪声点。
图3的聚类结果表明,fca-sfdpcd、dpc和dbscan算法均能对aggregation数据集成功聚类,但是k-means算法将一个簇分成三个簇,并在两个簇之间选择了类簇中心。虽然dbscan算法对该数据集成功聚类,但是该算法也将一些点标记为噪声点,使聚类效果有所下降。表3的聚类结果表明,fca-sfdpcd、fknn-dpc、dbscan和optics算法均能对该数据集成功聚类,但是与实际结果均存在些许偏差,dpc算法能对该数据集进行完美聚类,而ap和k-means算法的聚类效果不理想。
图4的聚类结果表明,fca-sfdpcd、dpc和dbscan算法均能对flame数据集成功聚类,但是k-means算法将簇1左边的数据点分配给了簇2,又将簇2的右下角部分数据点分配给了簇1,造成了严重的聚类错误,使它不能聚类成功。与aggregation数据集的聚类效果一样,dbscan算法虽然对该数据集聚类成功,但是该算法也将一些点标记为噪声点,使聚类效果有所下降。表3的聚类结果表明,fca-sfdpcd、dpc和fknn-dpc算法均能对该数据集进行完美聚类,但是dbscan算法聚类结果与实际结果却有少量不吻合,而optics、ap和k-means算法聚类结果均不是很好。
r15数据集中数据点的分布使得各算法对该数据集均能成功聚类,但是表3的聚类结果表明,虽然各算法均能对该数据做到成功聚类,但是该数据集中部分数据点存在于其他簇中,使得各算法均不能对该数据做到完美聚类。
图6的spiral数据集为交叉数据集,从图6可知,fca-sfdpcd、dpc和dbscan算法均能获得较好的聚类效果,值得注意的是,fca-sfdpcd算法和dpc算法相比,dpc算法的密度峰值点更接近簇的头部,各密度峰值点相隔距离较近,而fca-sfdpcd算法的密度峰值点却更靠近簇的尾部,各密度峰值点之间的距离相对较远,这类密度峰值点的优势就是能够使其他数据点更容易分配到正确的簇,当数据集变得更为复杂时,效果将变得尤为明显。由于k-means算法只能发现球状的簇,对于交叉数据集,它的聚类效果变得很差。表3的数据表明,fca-sfdpcd、fknn-dpc、dpc、dbscan和optics算法均能对该数据做到完美聚类,而ap和k-means算法的聚类效果却不尽人意。
对于图7所示的s2数据集,其数据点分布与r15和d31数据集较为相似,但是部分簇之间更为密集,而边界点数量也有所增加。由图7可以得出,fca-sfdpcd、dpc和k-means算法均能成功识别各个簇,而dbscan算法却将右下角的三个簇合并成了一个簇,并且将更多的边界点标记为噪声。表3的数据显示,对于该数据集,fca-sfdpcd、fknn-dpc、dpc和k-means算法均能达到较好的聚类效果,而dbscan、optics和ap算法的聚类结果却不能令人满意。
综上所述,fca-sfdpcd算法在各人工数据集上均能达到比较好的聚类效果,在边界点分配问题上,fca-sfdpcd算法在aggregation和s2数据集上与其他部分算法相比稍差,但是就总体效果而言,fca-sfdpcd算法要优于其他算法。
使用上述算法对13个uci数据集进行聚类分析,从表4可知,fca-sfdpcd算法仅在segmentation、inonsphere和waveform-+noise数据集上的聚类结果比其他部分算法的聚类效果略差,对于其余10个数据集均能获得较好的聚类效果。表5为各算法对13个uci数据集聚类各指标的平均值,表5表明fca-sfdpcd算法要优于其他6种算法。
表47种聚类算法在13个真实数据集上的聚类性能
表57种聚类算法在13个真实数据集上的平均性能
为进一步测试本文算法的聚类性能,将本文提出的fca-sfdpcd算法与其他dpc改进算法进行比较,由于各算法所在文献选择的数据集及评价指标不一,所以我们选择各文献使用频率最高的五个uci数据集及评价指标ari对各算法进行比较。表中“-”表示原文献中该算法并未对该数据集进行测试。
由表6的结果可知,fca-sfdpcd算法在处理iris数据集时略逊于adpc-dnaga算法,与fn-dp算法效果相当,比其余6种算法效果更佳。在处理seeds数据集时,聚类效果要略逊于idpca和adpc-dnaga算法,但是比其余6种算法效果均要好。在处理wine、wdbc和segmentation数据集时fca-sfdpcd算法聚类结果要优于其余所有算法。
表6不同的dpc改进算法在ari指标上的测试结果
- 一种沥青路面裂缝类型快速分类...
- 基于深度学习的钢材尺寸和数量...
- 一种禽蛋检测方法、装置、系统...
- 设备配网数据的处理方法、装置...
- 一种基于彩色图像的青椒识别方...
- 基于知识驱动和数据驱动的分群...
- 一种基于多源数据融合的电流互...
- 一种折线相似度的对比方法与流...
- 文本识别方法、装置、介质及电...
- 一种基于深度学习的运动模糊图...
- 还没有人留言评论。精彩留言会获得点赞!
- 基于快速密度聚类的电力通信网节点重要性评估方法
- 基于快速密度聚类的电力通信网节点重要性评估方法
- 采用新型密度聚类进行人脸识别的方法
- 一种基于特征选择与密度峰值聚类的异常流量检测方法
- 基于密度峰值聚类的杆状物规则化三维建模方法及系统的制作方法
- 一种基于密度与紧密度聚类的用户移动行为确定方法
- 一种基于密度峰值聚类的网络异常流量监测系统的制作方法
- 用于多孔介质三维重构的模式密度函数模拟算法
- 一种基于密度的文章聚合算法
- 一种基于密度聚类算法的城市交通拥堵状态检测方法
- 一种基于迭代的神经网络聚类方法
- 一种基于聚类和节约算法的路线优化推荐方法
- 基于聚类融合算法的社交团体发现方法
- 基于近似化的谱聚类算法预测癌症转移复发的方法
- 基于扫描线聚类的安防视频道路自动识别算法
- 一种基于密母算法的软件模块聚类分析方法
- 一种基于混合层次聚类的rdf数据平衡分割算法
- 基于层次聚类的云平台测速数据判定方法
- 一种基于数据场层次聚类的多模雷达信号分选方法
- 一种基于谱聚类算法的城市低电压分区方法
- 基于密度自适应的特征向量组最优选取谱聚类方法与流程
- 一种基于向量同态加密的隐私保护层次聚类方法与流程
- 基于模糊聚类的有效性指标的图像分割方法与流程
- 一种基于DFS与改进中心聚类法的破碎文档拼接方法与流程
- 一种结合类内紧致性和类间分离性的增量模糊聚类方法与流程
- 一种基于竞争学习的深度聚类方法与流程
- 一种面向公共安全事件信息获取的时空聚类方法与流程
- 一种聚类肽嵌段共聚物的制备方法与制造工艺
- 一种基于深度学习的短文本聚类方法与制造工艺
- 一种基于社交网络短文本流的用户聚类和短文本聚类方法与制造工艺