一种基于词袋模型的文本相似度计算方法及系统与流程
1.本发明涉及自然语言处理技术领域,具体是一种基于词袋模型的文本相似度计算方法及系统。
背景技术:
2.随着大数据时代的发展,用户获取信息的数据来源越来越丰富,如何从海量数据中向用户提供更为精确的个性化服务,成为亟待解决的问题。为此,个性化推荐成为近年来越来越热门的研究领域。
3.智能推荐算法是个性化推荐系统的核心,推荐算法的优劣是影响个性化推荐系统性能优劣的重要因素。而在智能推荐服务领域,文字产品是服务产品的主要样式之一。以文字产品为推荐对象,如何为用户更为精确的推荐信息,是目前智能推荐服务领域研究的热点之一。
4.根据获取用户兴趣方式的不同,推荐算法主要包括基于内容的推荐、协同过滤推荐、基于知识的推荐、混合推荐等多种方法。其中应用最为广泛的基于内容推荐算法,核心思想是计算内容的相似度。目前,文本相似度计算思想,均是通过对文本进行数字向量转换,将文本相似度计算转换为向量相似度计算问题。因此,如何用数字向量准确表征文本特征,是提高文本相似度计算精度的关键因素之一。
技术实现要素:
5.为克服现有技术的不足,本发明提供了一种基于词袋模型的文本相似度计算方法及系统,解决现有技术存在的文字产品的文本相似度计算精度不够、个性化推荐精准度较低等问题。
6.本发明解决上述问题所采用的技术方案是:
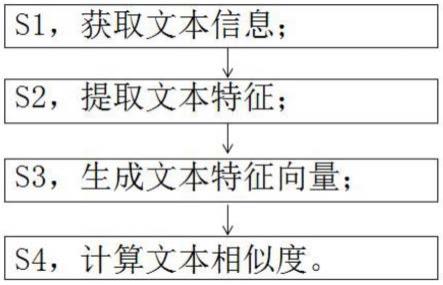
7.一种基于词袋模型的文本相似度计算方法,包括以下步骤:
8.s1,获取文本信息:获取文字产品的文本信息,所述文本信息包括用户在阅文本正文信息、待推荐文本正文信息;
9.s2,提取文本特征:采用tf-idf关键词提取算法,对文本进行关键词提取,输出文本的【关键词,tf-idf值】列表,用以表征文本特征,从而提取文本特征,所述文本特征包括用户在阅文本的文本特征、待推荐文本的文本特征;
10.s3,生成文本特征向量:生成词袋模型,采用词袋模型将文本特征进行数值化向量表示;
11.s4,计算文本相似度:计算在阅文本向量与待推荐文本向量之间的夹角,计算得到用户在阅文本与待推荐文本的相似度。
12.作为一种优选的技术方案,步骤s2包括以下步骤:
13.s21,利用文本预处理方法,提取出文本关键词;
14.s22,采用tf-idf算法计算各关键词的tf-idf值;
15.s23,将文本关键词按tf-idf值从大到小排序,输出排名靠前的n个关键词及其tf-idf值,输出的用户在阅文本的文本特征形式如下:
16.{[word
11
,v
tf-idf11
],[word
12
,v
tf-idf12
],...,,..[word
1n
,v
tf-idf1n
]};
[0017]
输出的待推荐文本的文本特征形式如下:
[0018]
{[word
21
,v
tf-idf21
],[word
22
,v
tf-idf22
],...,,..[word
2m
,v
tf-idf2m
]};
[0019]
其中,word
11
,word
12
,...,word
1n
分别表示用户在阅文本的前n个关键词,v
tf-idf11
,v
tf-idf12
,...,v
tf-idf1n
分别表示用户在阅文本的各关键词的tf-idf值,n≥3且n为正整数,n的取值根据需要自行设定;word
21
,word
22
,...,word
2m
分别表示待推荐文本的前m个关键词,v
tf-idf21
,v
tf-idf22
,...,v
tf-idf2m
分别表示待推荐文本的各关键词的tf-idf值,m≥3且m为正整数,m的取值根据需要自行设定。
[0020]
作为一种优选的技术方案,步骤s21中,文本预处理方法包括结巴分词和/或去除停用词。
[0021]
作为一种优选的技术方案,步骤s3包括以下步骤:
[0022]
s31,分别对用户在阅文本特征列表和待推荐文本特征列表进行关键词的权重归一化,输出用户在阅文本特征归一化列表和待推荐文本的特征归一化列表;
[0023]
用户在阅文本特征列表的关键词权重归一化公式如下:
[0024][0025]
输出用户在阅文本特征归一化列表的形式如下:
[0026]
{[word
11
,w
11
],[word
12
,w
12
],...,[word
1i
,w
1i
],..[word
1n
,w
1n
]};
[0027]
其中,i表示用户在阅文本关键词的编号,1≤i≤n;w
1i
表示用户在阅文本第i个关键词的权重,w
11
+w
12
+...+w
1i
+...+w
1n
=1;v
tf-idf1i
表示用户在阅文本第i个关键词的tf-idf值;
[0028]
待推荐文本特征列表的关键词权重归一化公式如下:
[0029][0030]
输出待推荐文本的特征归一化列表,形式如下:
[0031]
{[word
21
,w
21
],[word
22
,w
22
],...,[word
2j
,w
2j
],..[word
2m
,w
2m
]};
[0032]
其中,j表示待推荐文本关键词的编号,1≤j≤m;w
2j
表示待推荐文本第j个关键词的权重,w
21
+w
22
+...+w
2j
+...+w
2m
=1;v
tf-idf2j
表示待推荐文本第j个关键词的tf-idf值;
[0033]
s32,对用户在阅文本的文本关键词和待推荐文本的文本关键词求并集,生成词袋模型;词袋模型形式如下:
[0034]
u=u(word
11
,word
12
,...,word
1n
)∪u(word
21
,word
22
,...,word
2m
);
[0035]
s33,以词袋模型中文本关键词为索引,将文本关键词对应的数值用词权重表示,生成用以表征文本特征的词袋向量,词袋向量形式如下:
[0036]
word
11
,word
12
,...,word
1n
,word
22
,...,word
2m
[0037]
[w
11
,w
12
,...,w
1n
,0,...,0]
[0038]
[w
21
,0,...,0,w
22
,...,w
2m
];
[0039]
其中,
[0040]
word
11
,word
12
,..
·
,word
1n
,word
22
,...,word
2m
表示索引号;
[0041]
[w
11
,w
12
,
···
,w
1n
,0,
···
,0]表示用户在阅文本的特征向量;
[0042]
[w
21
,0,
···
,0,w
22
,
···
,w
2m
]表示待推荐文本的特征向量。
[0043]
作为一种优选的技术方案,步骤s32中,未在文本中出现的词,则权重为0。
[0044]
作为一种优选的技术方案,步骤s4中,采用余弦计算公式,计算在阅文本特征向量和待推荐文本特征向量之间夹角的余弦值,用以表征用户在阅文本和待推荐文本之间的相似度。
[0045]
作为一种优选的技术方案,步骤s4中,余弦计算公式如下:
[0046][0047]
一种基于词袋模型的文本相似度计算系统,基于所述的一种基于词袋模型的文本相似度计算方法,包括依次电相连的文本信息获取模块、文本特征提取模块、文本特征向量生成模块、文本相似度计算模块;
[0048]
其中,
[0049]
文本信息获取模块:用以获取文字产品的文本信息,所述文本信息包括用户在阅文本正文信息、待推荐文本正文信息;
[0050]
文本特征提取模块:用以采用tf-idf关键词提取算法,对文本进行关键词提取,输出文本的【关键词,tf-idf值】列表,用以表征文本特征,从而提取文本特征,所述文本特征包括用户在阅文本的文本特征、待推荐文本的文本特征;
[0051]
文本特征向量生成模块:用以生成词袋模型,采用词袋模型将文本特征进行数值化向量表示;
[0052]
文本相似度计算模块:用以计算在阅文本向量与待推荐文本向量之间的夹角,计算得到用户在阅文本与待推荐文本的相似度。
[0053]
本发明相比于现有技术,具有以下有益效果:
[0054]
本发明提出一种基于词袋模型的文本相似度计算方法及系统,计算文字产品相似度,利用本发明计算得出的文本相似度比其他方法具有更高的准确性,从而提高文字产品的个性化推荐精度。
附图说明
[0055]
图1为本发明所述的一种基于词袋模型的文本相似度计算方法的步骤示意图;
[0056]
图2为本发明所述的一种基于词袋模型的文本相似度计算系统的结构示意图。
具体实施方式
[0057]
下面结合实施例及附图,对本发明作进一步的详细说明,但本发明的实施方式不限于此。
[0058]
实施例1
[0059]
如图1、图2所示,本发明提出一种基于词袋模型的文本相似度计算方法,计算文字产品相似度,从而提高文字产品的个性化推荐精度。
[0060]
包括下列步骤:
[0061]
步骤s1:获取文本信息。文本信息包括用户在阅文本信息和待推荐文本信息。
[0062]
用户在阅文本信息主要指用户在阅文本的正文内容;待推荐文本信息主要指待推荐文本的正文内容。
[0063]
步骤s2:提取文本特征。文本体征包括用户在阅文本特征和待推荐文本特征。
[0064]
用户在阅文本特征提取:
[0065]
首先利用结巴分词、及去除停用词等文本预处理方法,提取出文本关键词;其次采用tf-idf算法计算各关键词的tf-idf值;将文本关键词按tf-idf值从大到小排序,输出排名靠前的n个关键词及其tf-idf值,形如:
[0066]
{[word
11
,v
tf-idf11
],[word
12
,v
tf-idf12
],...,,..[word
1n
,v
tf-idf1n
]};
[0067]
用以表征文本特征。其中,word
11
,word
12
,...,word
1n
分别表示文本的前n个关键词,v
tf-idf11
,v
tf-idf12
,...,v
tf-idf1n
分别表示各关键词的tf-idf值。n的取值可根据需要自行设定。
[0068]
待推荐文本特征提取:
[0069]
待推荐文本特征提取方法参看用户在阅文本特征提取方法。输出为待推荐文本的特征列表,形如:
[0070]
{[word
21
,v
tf-idf21
],[word
22
,v
tf-idf22
],...,,..[word
2m
,v
tf-idf2m
]};
[0071]
其中:word
21
,word
22
,...,word
2m
分别为待推荐文本的前m个关键词,v
tf-idf21
,v
tf-idf22
,...,v
tf-idf2m
分别表示各关键词的tf-idf值。m的取值可根据需要自行设定。
[0072]
步骤s3:生成文本特征向量。文本特征向量包括用户在阅文本特征向量,和待推荐文本特征向量。
[0073]
首先,对用户在阅文本特征列表进行关键词的权重归一化处理。归一化公式如下:
[0074][0075]
其中:v
tf-idf11
,v
tf-idf12
,...,v
tf-idf1n
分别表示在阅文本前n个关键词的tf-idf值;v
tf-idf1i
表示在阅文本第i个关键词的tf-idf值。
[0076]
输出用户在阅文本特征归一化列表,形如:
[0077]
{[word
11
,w
11
],[word
12
,w
12
],...,,..[word
1n
,w
1n
]};
[0078]
其中,word
11
,word
12
,...,word
1n
分别表示文本的前n个关键词,w
11
,w
12
,...,w
1n
分别表示各关键词的权重,满足w
11
+w
12
+...+w
1n
=1。
[0079]
其次,对待推荐文本特征列表进行关键词的权重归一化处理。归一化方法参看对用户在阅文本特征列表的归一化方法,待推荐文本特征列表的关键词权重归一化公式如下:
[0080][0081]
其中,w
2j
表示待推荐文本第j个关键词的权重;v
tf-idf21
,v
tf-idf22
,...,v
tf-idf2m
分别表示待推荐文本前m个关键词的tf-idf值;v
tf-idf2j
表示待推荐文本第j个关键词的tf-idf值。
[0082]
输出待推荐文本的特征归一化列表,形如:
[0083]
{[word
21
,w
21
],[word
22
,w
22
],...,,..[word
2m
,w
2m
]};
[0084]
其中,word
21
,word
22
,...,word
2m
分别为待推荐文本的前m个关键词,w
21
,w
22
,...,w
2m
分别为各关键词的权重,满足w
21
+w
22
+...+w
2m
=1。
[0085]
然后,计算分别用户在阅文本和待推荐文本的特征向量。步骤如下:
[0086]
对用户在阅文本特征归一化列表和待推荐文本特征归一化列表中的关键词求并集,输出词袋模型,形如:
[0087]
u=u(word
11
,word
12
,...,word
1n
)∪u(word
21
,word
22
,...,word
2m
);
[0088]
其中,word
11
,word
12
,...,word
1n
分别表示文本的前n个关键词,word
21
,word
22
,...,word
2m
分别为待推荐文本的前m个关键词。
[0089]
举例说明:当关键词word
11
=word
21
时,输出词袋模型为:
[0090]
u=u(word
11
,word
12
,...,word
1n
,word
22
,...,word
2m
);
[0091]
以词袋模型u中的文本关键词为索引,其对应的数值用词权重表示,未在文本中出现的词,则权重为0,分别生成用户在阅文本和待推荐文本的词袋向量,用以表征文本特征,称之为文本特征向量。
[0092]
举例说明:当关键词word
11
=word
21
时,输出用户在阅文本的词袋向量和待推荐文本的词袋向量如下所示:
[0093]
word
11
,word
12
,...,word
1n
,word
22
,...,word
2m
[0094]
[w
11
,w
12
,...,w
1n
,0,...,0]
[0095]
[w
21
,0,...,0,w
22
,...,w
2m
];
[0096]
其中:
[0097]
word
11
,word
12
,...,word
ln
,word
22
,..
·
,word
2m
为索引号;
[0098]
[w
11
,w
12
,...,w
1n
,0,...,0]为用户在阅文本的特征向量;
[0099]
[w
21
,0,...,0,w
22
,...,w
2m
]为待推荐文本的特征向量。
[0100]
步骤s4:计算文本相似度。
[0101]
采用余弦计算公式,计算在阅文本特征向量和待推荐文本特征向量之间夹角的余弦值(取值范围为(0~1)),用以表征用户在阅文本和待推荐文本之间的相似度。相似度越高的两篇文本,其特征向量夹角的余弦值越接近于1。计算公式如下:
[0102][0103]
将提出的基于改进词袋模型的文本相似度计算方法,与其他方法进行对比验证,在收集的10万条文字产品数据集上,本发明的评测指标高于其他方法,利用本发明计算得
出的文本相似度比其他方法具有更高的准确性。
[0104]
如上所述,可较好地实现本发明。
[0105]
本说明书中所有实施例公开的所有特征,或隐含公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合和/或扩展、替换。
[0106]
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,依据本发明的技术实质,在本发明的精神和原则之内,对以上实施例所作的任何简单的修改、等同替换与改进等,均仍属于本发明技术方案的保护范围之内。
完整全部详细技术资料下载
当前第1页 1 2
相关技术
- 基于GIS技术的土地测绘设备...
- 安全冗余编译运行方法、计算机...
- 电力调控实时信息无线远程监视...
- 店铺数据处理方法、装置、计算...
- 一种识别目标用户的方法和装置...
- 一种对象数据显示方法、装置、...
- 信息共享处理方法、装置、设备...
- 一种驱动射频电路的包络分析二...
- Wi-Fi的压力测试方法和装...
- CT数据重建方法和装置、电子...
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1