四倍体是啥?
4 个回答

哈哈哈,这是一个好问题。关于染色体组,单倍体,二倍体,多倍体的概念一直都存在一些小争议,我最喜欢有点争议的小东西了。
忍不住要吐槽一波,算了算了,还是先回答问题再吐槽吧。
1.什么是染色体组
染色体组是细胞中的一组非同源染色体,携带着控制生物生长发育的全部遗传信息 [1]。一个染色体组以N表示,由若干条染色体组成,它们的形态、结构和功能各异,但又相互协调并共同支配着生物体的生长、发育、遗传和变异 [2]。
比如,果蝇就含有两个染色体组 [3],人也是,都是二倍体生物。
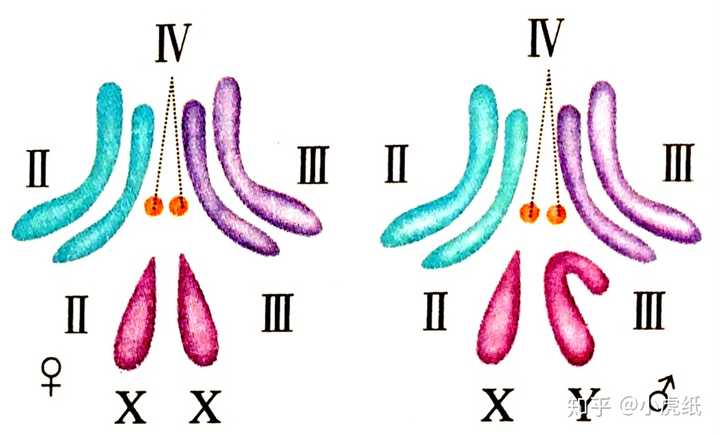

高中生物课本的名词概念一般是有对应的英文名的,但是为了避免不必要的麻烦,课本中没有注明染色体组对应的英文。如果去查一下染色体组对应的英文,会发现这个词是genome,而反过来查,genome这个词更多的是表示基因组。早期,遗传学家将包含整套遗传物质染色体定义为染色体组(genome)。近年来,genome这一术语在一般情况下表示为基因组,指一个配子的染色体所带有的全部基因。这么看来,染色体组这个概念有些落后啊。
知道了什么是染色体组,再看什么是四倍体就容易了。
2.同源四倍体
多倍体的情况在被子植物中非常普遍,大约有33%的被子植物是多倍体。
同源四倍体有两种情况。
一种是两个含有两个同种生物染色体组的配子结合,这样发育成的个体的体细胞中含有四个染色体组,称作四倍体。
另一种情况是,二倍体在胚或幼苗时期受某种因素影响,如低温诱导或者秋水仙素处理,使得体细胞在进行有丝分裂时,染色体只复制未分离,这样也会形成四倍体。


四倍体可以通过减数分裂形成含两个染色体组的配子。
3.异源四倍体
如果一个亲本物种有染色体组AA,另一亲本物种的染色体组是BB,杂交后得到种间杂种,具有A、B染色体组的二倍体(异源二倍体)。染色体加倍成为AABB(异源四倍体),这种情况形成的异源四倍体生物也可称作双二倍体。像这样,两个或两个以上的不相同物种杂交,其杂种的染色体组经染色体加倍形成的多倍体就属于异源多倍体。
我国的普通小麦(主要有三个亚种:云南小麦,新疆小麦和西藏半野生小麦)是异源六倍体,并认为是由三种植物杂交而成 [4],下图中的野生二粒小麦就是异源四倍体。
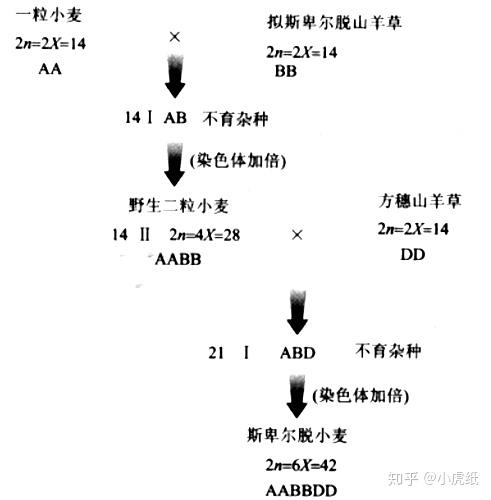

如果继续培育,还能得到异源八倍体的小黑麦。八倍体小黑麦是由普通小麦和二倍体黑麦杂交而成。名字也是这么来的,普通小麦(6X)+黑麦(2X)=小黑麦(8X)。
多说一句,小麦的基本染色体组是A [5],在分析小麦演化模式中,含有A染色体组的都被叫做小麦,找找下图中的异源四倍图在哪里。


除了杂交,两个二倍体植物细胞,通过植物体细胞杂交技术也能得到异源四倍体。
4.四倍体不是四体
三倍体与三体不一样,四倍体也不能简单叫做四体生物。
我们所说的几倍体都是指的整倍体,而说的“三体”“四体”指的是非整倍体。


唐氏综合征就是三体人,也称作21三体综合征。
5.吐槽时间到
在旧版高中教材中对二倍体和多倍体的定义如下 [1]。
由受精卵发育而成的个体,体细胞中含有两个染色体组的叫做二倍体;体细胞中含有三个或三个以上染色体组的叫做多倍体。其中,体细胞中含有三个染色体组的叫做三倍体:体细胞中含有四个染色体组的叫做四倍体。
这个概念对其来源做出了规定,有受精卵(合子)发育而来的个体,在 @赵泠 回答中,提到“四倍体生物由合子发育而来“就和此概念相吻合。(非引战,我是 @赵泠 的粉,保命要紧)
但是,这个概念存有争议。在有些大学遗传学教材中 [2],这一组概念就没有强调来源。
单倍体是指细胞核中含有一个完整染色体组的生物体或细胞。二倍体是指具有两个染色体组的细胞或个体。具有3个或3个以上染色体组的细胞或个体称为多倍体。按其来源又分为同源多倍体和异源多倍体。
新版高中生物教材对多倍体的概念也做出了修改。把由“受精卵发育而来”这句给删掉了。
如果两个含有两个染色体组的配了结合,发育成的个体的体细胞中就含有四个染色体组,称作四倍体力如果二倍体在胚或幼苗时期受某种因素影响、体细胞在进行有丝分裂时,染色体只复制未分离,也会形成四倍体。体细胞中含有三个或三个以上染色体组的个体,统称为多倍体 [3]。
但是,新版教材改的并不彻底。改了就改了,怎么改就怎么学呗。不过麻烦改就改全套啊,单倍体概念也一起改了啊。单倍体的概念还是有些含糊不清。
如,蜜蜂的蜂王和工蜂的体细胞中有32条染色体,而雄蜂的体细胞中只有16条染色体。像蜜蜂的雄蜂这样,体细胞中的染色体数目与本物种配子染色体数目相同的个体,叫作单倍体 [1] [3]。
来做一道题就知道为什么会感觉纠结呢?
有个二倍体植物,纯合个体,我们记做2N,染色体组加倍后变为了4N,其配子(花药离体培养)单独发育成了一个单独的个体,此个体含有两个染色体组。问题来了,此个体是几倍体呢?
它是四倍体生物的单倍体?还是恢复成了含有两个染色体组的二倍体生物?还是两种说法都对?如果两种说法都对,能说它既是单倍体又是二倍体吗?
题目虽然是我出的,但是答案是什么我并不知道。如果让我选,我选二倍体。我的倾向是简单点,再简单点。
大哥,你是了解我的,我喜欢简单粗暴……
参考
- ^ a b c高中生物教材,必修Ⅰ,人民教育出版社,2004年初审通过
- ^ a b戴灼华,遗传学,第2版,高等教育出版社
- ^ a b c高中生物教材,必修Ⅱ,人民教育出版社,2019新版
- ^梁祖霞.普通小麦起源之谜[J].种子世界,1987(04):37-38
- ^曹亚萍.小麦的起源、进化与中国小麦遗传资源[J].小麦研究,2008,29(03):1-10.

染色体倍性指细胞内包含的染色体组的数目,只有一组染色体的称为“单套”或“单倍体”,有两组则称为“双套”或“二倍体”,有超过两组染色体的叫做多倍体。含有四组染色体的细胞称为四倍体细胞。
由合子发育而成的、体细胞中含有四个染色体组的生物称为四倍体生物。
例如二倍体葡萄有19对染色体,四倍体葡萄有38对染色体。
常见的玉米、花生、棉花、白菜、油菜都是四倍体生物。
要注意,由配子而非合子发育而成的生物无论体细胞里有几个染色体组,都是单倍体。八倍体生物的卵子未经受精直接发育出来的生物个体是单倍体而不是四倍体。
同源多倍体生物的体细胞中含有多个来自同种生物的染色体组。异源多倍体生物的体细胞中含有来自不同种生物的多个染色体组。例如小黑麦是六倍体,其中有四套染色体来自小麦,还有两套染色体来自裸麦。

2024年1月23日Nature communication 在线发表A chromosome-scale assembly reveals chromosomal aberrations and exchanges generating genetic diversity in Coffea arabica germplasm基因组文章。


摘要
为了更好地理解最近的异源四倍体咖啡(Coffea arabica)物种中产生遗传多样性的机制,我们在这里提出了利用长读取技术获得的染色体水平组装。在两个同源基因组中确定了具有不同结构和功能特性的两个基因组区域。来自大量材料的重测序数据揭示了该物种原产地的种内多样性较低。在有限数量的基因组区域中,一些栽培基因型的多样性增加到与一个亲本物种Coffea canephora内部观察到的水平相似,可能是由于所谓的Timor杂交导致的插入。它还揭示了除了少数早期同源染色体之间的交换外,还存在许多最近的染色体异常,包括非整倍体、缺失、重复和交换。这些事件在种质资源中仍然多态,并且可能代表了这种变异较低的物种中的基本遗传变异源。
结果和讨论
基因组组装的连续性、准确性和完整性
阿拉比卡咖啡(C. arabica)的组装序列总量为1.32 Gbp(见补充表1),几乎与基于流式细胞术中观察到的2 C值为2.71 pg ± 0.04的预期基因组大小1.33 Gbp相匹配。其中,1,098,789,244 bp的非间隔序列组装成了22条染色体伪分子,包括175个contigs、80个scaffolds和22个超级scaffold(图1a,补充表2和补充方法1)。将组装与BAC序列进行比较以评估共识序列的准确性。我们在350个随机基因组区域的1.5 Mbp样本中发现组装与BAC scaffold之间的整体序列一致性达到了99.4%。相较于以前的阿拉比卡咖啡组装,该组装显示了更高的完整性和连续性,以及与二倍体祖先的组装在顺序和方向上更好的一致性(补充图1-11和补充表3-4)。
图1:阿拉比卡咖啡染色体的图形表示


a 基因组组装的连续性和完整性以及rDNA数组的位置。b 阿拉比卡咖啡亚基因组之间的合成图。c 跨越4467个非重叠基因组窗口的基因和可移动元件(TE)密度,对应于100 Kb的非重复DNA和A/B类型染色质区段。在所有面板中,y轴表示百万碱基对(Mbp)。源数据提供为源数据文件。
我们预测了57,794个基因模型,其中间位数长度为2,409 bp,外显子中位数数目为4。其中,27,337个基因的中位长度为2,528 bp,属于canephora亚基因组。另外28,197个基因的中位长度为2,480 bp,属于eugenioides亚基因组。未定位scaffolds中预测出了2,260个基因。编码序列的累积长度达到了85.5 Mbp,占据了总基因组长度的6.5%。内含子的中位长度为238 bp,并且累积覆盖了基因组长度的12.5%。BUSCO分析25表明,预期的单拷贝基因中有99.3%被完全组装,0.7%在组装序列中不存在,无论是作为片段还是部分拷贝。正如预期的那样,在一个相对最近起源的四倍体物种中6,91.5%的预期通用同源基因是完整的并且是重复的。
端粒重复序列在44条染色体末端的38个位置被组装起来(图1a)。Chr7e的下端和Chr11e的上端的组装被伪分子中部分组装的35S rDNA数组(分别为35和30重复)中断。它们的同源染色体(Chr7c和Chr11c)的组装中断于35S rDNA数组开始的近端。一个未定位的scaffold(scaffold_682,大小127 Kb)在一端包含了端粒重复序列,在另一端包含了12个35S rDNA单位。scaffold_682中端粒重复序列和rDNA的取向与染色体7和11中相同序列的取向相关,这让我们相信它可能代表Chr7c或Chr7e的染色体末端,为阿拉比卡咖啡染色体7上的35S rDNA位点的亚端粒位置提供了证据(图1a)。在16个未定位的scaffolds中找到了290个额外的35S rDNA单位重复。因此,35S rDNA总共约为~3.42 Mbp,由保守的~9.5 Kb单体组成。35S rDNA数组中插入了3个可移动元素(TE)。Chr11e上组装了两个5S rDNA位点,Chr11c上组装了一个5S rDNA位点(图1a)。因此,Chr11携带了35S rDNA数组和5S rDNA数组。基于FISH实验证明,另外两条染色体上也预期存在两个5S rDNA位点26,但它们没有组装到任何染色体伪分子中。在28个未定位的scaffolds中找到了额外的5S rDNA重复。5S rDNA总共约为~4.58 Mbp,由保守的~0.5 Kb单体组成。Chr4e伪分子中缺少了端粒重复序列。三个未定位的scaffolds几乎完全由端粒重复序列组成。在一个染色体(Chr7c)中获得了近乎完整和连续的序列,解决了着丝粒和其周围串联重复卫星序列的问题(图1a和2a)。
阿拉比卡咖啡染色质组织和演化历史
高度准确和完整的四倍体基因组组装的可用性使得对两个同源基因组进行准确比较,从而更好地理解它们的演化和功能动态。从年轻叶片组织获得的Hi-C数据用于组装后的染色体伪分子,用于研究三维染色质组织。类似于大麦基因组27中观察到的情况,我们观察到了在染色体内Hi-C接触矩阵中存在着一个可识别的反对角模式(补充图12),表明在C. arabica有丝分裂后期细胞核中发生了RABL构型,其中两条染色体臂在其分裂点之后相互接触。在Hi-C接触矩阵中也清楚地看到了亚端粒区域之间更高的接触频率,就像大麦27和拟南芥28中所观察到的那样。
我们对50 Kb分辨率的距离归一化交互矩阵进行了主成分分析,并利用PC1值的符号将100 Kb基因组窗口分配到活跃和紧凑度较低的A区段或不活跃和紧凑度较高的B区段。总体上,我们观察到,在年轻叶片的细胞核中,C. arabica基因组约有465 Mbp(44.2%)对应于A区段,有586 Mbp(55.8%)对应于B区段。A和B染色质区段的比例在两个亚基因组中非常相似(A区段分别代表canephora和eugenioides亚基因组的44.1%和44.3%),大规模的染色质组织在两个同源染色体之间经常非常相似(补充图13-16)。一小部分染色体两端都有A区段环绕着一个大的B区段,而绝大多数染色体有一个端仅占据了染色体的一端的不对称的染色质组织(补充图13-17)。A和B染色质区段显示出不同的结构和功能属性,以及非常不同的演化历史。
在结构上,染色质区段与重复序列和基因密度密切相关(图1c和补充图17)。A区段贫含重复序列而富含基因,而B区段则呈相反的组织(补充图18a,b)。所有类转座元件超家族都主要位于B区段,不同超家族在A/B区段之间相对富裕的相关性差异较大(补充表5)。
从演化上看,A区段的同源序列和亚基因组之间的序列相似性比B区段之间更高(图2b和补充图18c-f),这主要是由于不同的转座元件插入历史导致的。在C. arabica内,两个亚基因组在444 Mbp范围内保持共线性,其中包括132 Mbp的共享转座元件,累计占canephora亚基因组的40.8%和eugenioides亚基因组的40.1%,平均序列相似性为94.9%(图1b,c和补充图19-24)。亚基因组的其余部分富含结构变异,这是由两个二倍体祖先物种之间的遗传变异所引起的,涉及了累计519 Mbp,相当于47.3%的染色体总长度(补充图1-11和19-24)。还存在着135 Mbp的由于存在/缺失变异而产生的不能归因于已知转座元件的非共享序列,相当于染色体总长度的12.3%(补充表6)。当比较A和B区段中共享的序列比例时,我们发现两者之间的差异不是由于低/单拷贝DNA序列,而是由于B区段中存在的大量非共享转座元件。根据内元LTR分歧的基础上LTR-逆转座元件插入的年代学显示,共享的逆转座元素要比非共享的要老得多(补充图25和补充方法2)。这与共享的逆转座元素先于两个祖先物种分离的假设一致,而非共享的则代表了在整个B染色质区段中明显的序列分化,这在大片染色体区段上是可见的(补充图1-11和19-24)。阿拉比卡咖啡的非常近期起源使我们无法确定至少部分非共享插入是在异源多倍化事件之后发生的,并且可能会对阿拉比卡咖啡中的基因组中的现有序列变异做出贡献。
从功能上看,A区段在所有分析的器官中的转录活性更高(补充图26)。之前的一项研究显示,在同源基因之间的表达差异中,有65%的基因对表达水平相似30。我们将同源基因之间的表达水平差异与染色质区段联系起来。分析的所有组织显示,位于B区段的基因对的表达水平差异比位于A区段的更大(在分析的12个样本中有10个的差异是显著的),这可能是由于B区段中存在的结构变异水平更高,这可能导致调控同源基因拷贝的顺式调控元件的变异(补充图27)。
我们对参与咖啡因生物合成途径的一组基因在两个祖先基因组之间的结构、功能和演化方面进行了详细的比较分析,这些基因对于咖啡栽培和咖啡生产非常重要。控制咖啡因生物合成途径中三个关键步骤的特定N-甲基转移酶的基因位于C. arabica染色体1和9上。控制咖啡碱转化为咖啡因的最后一步酶的3,7-二甲基黄嘌呤 N-甲基转移酶(DXMT)基因,其删除或减少表达解释了咖啡树Coffea humblotiana32和C. arabica33,34中咖啡因合成的变异,位于Chr1的上亚端粒区域。在C. arabica中的canephora同源基因组(Chr1c)携带一个单个的DXMT拷贝(补充图28a)。在C. arabica中的eugenioides同源基因组(Chr1e)携带了一个~6.5 Kb长的串联重复,包括了该基因的基因体和其5'基因间区域的一部分,形成了两个DXMT拷贝(补充图28b)。源自咖啡罗布斯塔种的DXMT基因在阿拉比卡咖啡中在多个器官(如叶片、茎、根、芽、茎顶分生组织和果实)中表达。罗布斯塔种中DXMT基因的表达在发育中的绿色果实中表现出最高水平,在完全成熟的红色果实和采集于中间成熟阶段的混合果实样本中表现出最低水平(附图28和29)。而尤根尼奥德斯种中的DXMT副基因仅在发育中的绿色果实阶段显著表达(附图28和29)。尽管DXMT位于富含基因但缺乏重复序列的A端粒染色质域内,然而DXMT基因周围的基因间空间具有同源特异性重复DNA的存在,这可能解释了基因表达的器官特异性调控的差异(附图30和31)。控制可可碱及其前体合成的黄嘌呤甲基转移酶(XMT)和7-甲基黄嘌呤N-甲基转移酶(MXMT)这两个基因共定位于一个基因簇中,该簇包含了数个黄嘌呤甲基转移酶(XMT)基因,分别位于Chr9c和Chr9e上。在Chr9c上的簇中,有5个XMT预测基因位于一个153.1 Kb的区域内(附图32a)。而在Chr9e上的簇中,有6个XMT预测基因和具有与咖啡罗布斯塔MXMT和XMT蛋白31相似性的核苷酸转化序列位于一个191.5 Kb的区域内(附图32b)。该XMT簇的区域在阿拉比卡咖啡和阿拉比卡咖啡与阿拉比卡野生种之间的同源物外编码序列之间显示出较小的相互关系(附图33)。在这个基因簇中,负责酶转化成可可碱的副基因(MXMT,对应于咖啡罗布斯塔的Cc00_g24720基因)在阿拉比卡咖啡器官中以类似水平从两个亚基因组中表达。至于阿拉比卡咖啡同源簇中的其他XMT基因拷贝,与在咖啡罗布斯塔种子中表达的XMT拷贝(Cc09_g06970)具有最高序列相似性的拷贝也是在阿拉比卡咖啡器官中表达最多的(附图29)。咖啡罗布斯塔种中这个XMT拷贝的同源物在所有器官和复制体中转录水平要远高于尤根尼奥德斯种中的XMT同源物,这种情况在发育中的绿色果实中最为明显。果实中XMT和MXMT的表达模式与最近对咖啡豆中这些基因表达进行的详细分析35基本一致,而对于DXMT基因而言,在考虑到尤根尼奥德斯中存在的两个拷贝的累积表达时,两个亚基因组中的基因差异似乎较为不明显。正如之前指出的,这些咖啡因生物合成基因的表达模式似乎与成熟种子中的咖啡因含量高度相关。
C. arabica基因组的着丝点区域
与先前关于C. arabica中着丝点卫星数组缺失的说法相反,我们发现了在C. arabica中存在大量串联重复的卫星结构,其大小可达数百Kb,并且在每条染色体的B染色质区跨越数Mbp(附图17、34-35)。我们并未发现形成通常观察到的高等重复结构的短单体单位(100-200 bp),这种结构通常跨越不同的生物界(例如在酿酒酵母37、拟南芥2和人类38中),并促进着丝点的形成。使用串联重复查找工具39未发现在长度短于2 Kb的串联排列区域中有短于2 Kb的重复单元。每条染色体的异染色质区域的相当部分由长于2 Kb的串联重复数组组成,这些序列通常来自不同的含染色域的Gypsy逆转录子(图2a和附图17)。CRM、Tekay、Galadriel、Reina和Athila派生序列占据了C. arabica基因组的45.4%,并且特异地定位在每条染色体的B染色质区域内(附图17)。大部分派生自CRM和Tekay类群的单体单位,以及在更有限的程度上派生自Reina和Galadriel类群的单体单位形成了沿染色体的交替排列的复杂结构(附图34-35)。包含最高密度的染色病毒派生数组的大片染色体区域通常由具有最高Athila派生串联排列数组密度的区域所夹带,有时这些区域会与染色病毒派生数组夹杂在一起(附图35)。在Chr7c中,存在一个690 Kb长的卫星结构,由一个2,683 bp的CRM派生单体结构组成,此结构在序列构成上高度保守,与周围区域的序列构成差异很大(图2和附图3)。在同源染色体(Chr7e)的相同区域中,相同的单体构成了一个394 Kb长的数组。单体单位的系统发育分析表明,这些数组的形成可能早于两个原始物种的分化。它们的内部序列变异模式还表明,它们是在不同的动态下扩展和进化的(附图36)。Chr7e上的数组显示出大部分是由高度相似的单体组成,就像这个数组的某些部分是最近扩展或通过不平衡交叉发生序列均质化的结果。Chr7c上的数组单体间的序列同一性较低,随着它们的物理距离增加,单体之间的序列逐渐变得不那么相似。Chr7e和Chr7c上的数组都被LTR-逆转录子插入打断(Chr7e有一个,然后被复制,Chr7c有8个,附图37-38)。这些逆转录子插入发生在一个长达9.2到0.3百万年的时间跨度上(附表7)。更老的插入位点位于Chr7c数组的远端区域,该区域的单体之间的序列差异更大。没有其他染色体伪分子携带这种单体的数组,但是同样的单体存在于27个未定位的支架上,总共约为4.0 Mbp,其中包含这种单体的串联数组覆盖了97.9%的序列。这些支架可能代表未分配到染色体伪分子的其他染色体的着丝点卫星数组。C. arabica B区的复杂结构以及所有染色体上没有单一短单体的串联重复,例如在人类ɑ-卫星和拟南芥CEN180卫星2中促进了着丝点的形成,这些特征使得仅通过DNA序列特征预测C. arabica着丝点的确切位置成为不可能。
测序的波旁基因型亚基因组之间的染色体重排
尽管整倍体化事件之后,同源基因对的祖先染色体位置通常得到保留,但C. arabica组装显示了对这一普遍规律的几个例外。我们精确地映射了三次同源末端染色体之间的交换事件,全部涉及A染色质区域,并导致自体四倍体染色体区域的出现(Chr2c:74,564,297-74,718,367,Chr7c:1-1,252,944和Chr10e:1-56,401)。其中最大的一个在图1b中有所说明,而其他两个由于尺寸过小,在图1b的图形放大倍率下无法看到。这些事件导致了用尤根伊亚甜橙同源片段替换了罗布斯塔咖啡同源片段,共影响了169个预测基因,这些基因的异源多倍体条件已经丢失。这些同源替换在C. arabica中是固定的,这可以从所有分析的样品中这些区域缺乏同源SNP来证实(见下一段)。在支持组装的长读取中SNP的分布分析显示,Chr2上的同源交换发生在Chr2c上Cara0002c46780和Cara0002c46790基因之间的基因间空间内,Chr2e上Cara0002e47690和Cara0002e47700基因之间的基因间空间内。Chr7上的同源交换发生在一个Helitron可移动元件内,而Chr10上的同源交换发生在一个突变体可移动元件内。波旁基因型的染色体级组装还揭示了一个以前未发现的大规模同源重组事件,涉及一个相互对称的交换,可能来源于整倍体化事件之前在不同物种间的杂种二倍体细胞系中发生的有丝分裂交换41。这次对称交换交换了本地染色体10的7.6-Mbp的罗布斯塔和尤根伊亚甜橙臂(图1b)。对称交换的位点出现在一个轴精蛋白样蛋白KIN-14R(基因模型Cara0010e09280和Cara0010c09420,见附图39)的转录单元内。Cara0010e09280和Cara0010c09420从负链转录成19个外显子。在外显子6和内含子10中间出现了一个大约3 Kb的明显与交换相关的转换区域(COCT)42,该区域的序列与现代的尤根伊亚甜橙相比更相似,而不是现代的罗布斯塔。这次基因内的对称交换既没有破坏内含子-外显子结构,也没有影响基因的转录活性(附表8)。通过PCR实验证实了‘波旁’中这次同源重组的证据,并显示这个事件不仅限于也门来源的波旁/蒂皮卡种质资源,而且也存在于代表埃塞俄比亚种质资源的‘1-盖沙’(Supplementary Fig. 40)。在这次同源交换之后,一个小的末端同源替换事件(如上所述)用尤根伊亚甜橙的DNA(先前移动到Chr10e同源上)替换了罗布斯塔的55 Kb DNA。
与迄今为止报告的情况不同,区分Chr8c和Chr8e的大型染色体内倒位和易位(图1b,Chr8c:26,514,569-30,375,036,Chr8e:34,155,493-37,608,685)似乎并非后整倍体化事件的结果(另请参见附图12中的接触图的支持证据和附图1-11中与Caturra组装的相同染色体的一致性以排除与组装相关的问题)。尽管C. canephora和C. eugenioides基因组在这一染色体区域上高度解体(附图1–11),但它们似乎证实了这种染色体内重排是两个二倍体原始物种之间的现有变异的一部分,因此染色体重排先于整倍体化事件。
图2:同源染色体在常染色质和异染色质区域之间的序列和结构变异。
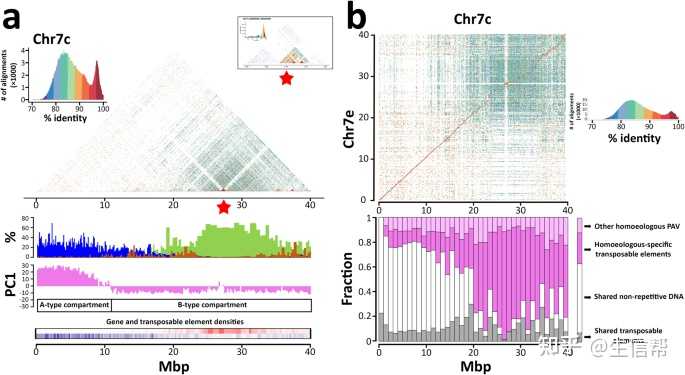

a Chr7c的组成和染色质组织。面板顶部的序列相同性热图显示了一个高度保守的2.7 Kb单体的串联重复数组,由红色星号标示,并在插图中放大;基因(蓝色)、Athila-(棕色)和Chromovirus-derived(橄榄绿色)序列丰度的柱状图,以exonic碱基对百分比(基因)和RepeatMasker使用完整的Coffea Athila和Chromovirus序列屏蔽的碱基对百分比,跨越4447个非重叠基因组窗口包含100 Kb的非重复DNA,并使用100 Kb的基因组窗口定义A/B区段的PC1值的柱状图。b Chr7c和Chr7e之间的比较。每个点代表非重叠的2 Kb窗口之间具有>70%相似性的序列比对。每个点的颜色代表序列相似性的百分比。箱线图表示在同源基因组之间共享的核苷酸分数(白色和灰色)或专有的核苷酸分数(粉色和洋红色)。这些类别进一步分为注释的转座元件(灰色和洋红色)和非重复DNA(白色)。粉色堆栈包括低拷贝DNA以及在拱形区域外部没有被注释为转座元件的其他DNA区段。在两个面板中,x轴表示百万碱基对(Mbp)。源数据提供为源数据文件。
在Coffea arabica物种和阿拉比卡栽培种质中的遗传多样性
我们在一组174个Coffea sp.品种中检测到了7,694,774个变异位点,平均每个品种有716,303,048个信息位点,并分布在22个染色体伪分子中。根据公开可获取的文献报告和本文分析的分类结果(图3a-d和补充图43),我们的全基因组测序面板包括34个C. canephora品种、1个C. eugenioides品种、95个C. arabica品种和44个C. arabica × Coffea sp.引入系(补充数据1)。C. arabica品种的核苷酸多样性中位数为π = 3.12×10-4(图3c)。C. arabica基因组中,具有异常π值的窗口在基因组中呈随机分布(图3d)。总体而言,C. arabica品种每个基因组窗口的纯合SNP数量很低(补充图44),特别是在相对容易清除假阳性SNP的canephora亚基因组中,而不是eugenioides亚基因组。
图3:172个Coffea sp.品种的遗传多样性。


图3a:主成分分析(PCA)的前两个分量的二维图。需要注意的是,C. eugenioides品种未包括在a中,详见补充图43,而C. canephora 33-1品种由于测序覆盖度较低已从两个PCA分析中移除(补充数据1)。图3b:放大了图a中矩形所限定的部分的二维图。图3b(插图):根据不含C. canephora引入区域(每个品种左侧的橄榄绿色框)和含C. canephora引入区域(每个品种右侧的洋红色框)的100 Kb非重复DNA基因组窗口中SNP数量的箱线图分布,涉及3个类似阿拉比卡的样品以及3个Timor杂交衍生物(P7963、T5175和T8667)。箱子表示第一四分位数和第三四分位数,箱子内的水平线表示中位数,须表示±1.5×四分位距。每个框下方的数字表示每个基因组区段的基因组窗口数量。百分位分布(c)和核苷酸多样性(π)的染色体分布(d),跨越4,467个不重叠的含有100 Kb非重复DNA的基因组窗口。在d中,刻度条上的箭头指向中位数值,y轴表示百万碱基对(Mbp)。*在SRA元数据中,测序标本BioSamples SAMN10411969和SAMN10411970分别以Kent和SL34命名,与其一致。源数据作为源数据文件提供。
埃塞俄比亚品种与Bourbon/Typica品种有明显差异(图3b),并贡献了一些具有较高纯合SNP频率的基因组区域。C. arabica中杂合SNP计数的分布可能反映了SNP检测中的基线假阳性误差率,因为根据它们的交配系统,预计这些品种大多数应该是纯合的。由于公开可获取的测序数据的覆盖度较低(补充数据1),过滤程序无法降低误差率。我们未在任何分析的品种中检测到同源SNP频率的增加,也未在我们检测到“Bourbon”基因组装中出现同源纯合替换事件的任何品种中发现同源SNP频率的增加,如果一些品种同时包含了这些区域的两个同源体,则应该会预期如此。这证明了我们在“Bourbon”基因组组装中观察到的同源替换事件代表了祖先事件。祖先二倍体物种的核苷酸多样性值比C. arabica高一个数量级,基因组分布相对均匀(图3c,d),只有C. eugenioides在此处由于具有纯合区段而在单一品种中代表。
我们在95个真正的C. arabica品种中检测到了1,877,440个SNP,这些SNP没有显示出种间杂交的迹象(补充数据1)。使用该数据集得到的系统发育树显示出了强支持的分支(bootstrap值>80%),这些分支主要包括Bourbon/Typica组的广泛使用的栽培品种、森林咖啡生产系统中利用的埃塞俄比亚种质以及园艺咖啡生产系统中利用的埃塞俄比亚种质(补充图45)。使用这个数据集得到的系统发育树显示出强有力的支系(支持率>80%),主要包括广泛使用的波旁/蒂比卡组的栽培品种、森林咖啡生产系统中本地利用的埃塞俄比亚种质资源,或者园艺咖啡生产系统中本地利用的埃塞俄比亚种质资源(附图45)。该树还显示了埃塞俄比亚遗传多样性的明显地理模式。在这个地理模式中,将波旁/蒂比卡组的栽培品种,也称为也门品种,与主裂谷以东埃塞俄比亚高地的地方品种统计支系分组(附图45)。我们重新分类为C. arabica × C. canephora内插系(补充数据1)的所有接种株系中,其基因组窗口的主要部分显示的核苷酸多样性估计与C. arabica相当,而根据品种不同,它们的基因组窗口中的一小部分(取决于接种株系)显示的多样性估计与C. canephora内的观察值相当。C. arabica × C. canephora内插系中显示出较高核苷酸多样性的基因组窗口不是随机分布在整个基因组中,而是在大的连续染色体段中发现,这与C. canephora内插型单倍体的存在相符。因此,C. arabica × C. canephora内插系在PCA双图上与埃塞俄比亚品种和波旁/蒂比卡品种所代表的纯C. arabica种质相比,呈现出偏离的特点,这些种质都具有非常低的多样性(图3b)。从纯C. arabica种质核心越来越远的各个C. arabica × C. canephora内插系在潜在插入的基因组窗口数量上存在差异,但在这些基因组窗口的核苷酸多样性水平上并没有差异。所有这些对于已知的C. arabica × C. canephora内插系(补充数据1)都是正确的,图3b中由Timor-hybrid衍生的(Catimor)接种株系P7963、T5175、T8667以及其他41个之前被归类为阿拉比卡的测序标本,这些标本在文献报告和存档的元数据23,24中都是如此。在原始的文献报告中,其中一些接种株系被分配了代码和来源国,表明它们要么是有意作为内插系进行采样的,要么是从育种机构的种质库引入的(补充数据1)。这些接种株系(n=37)中的插入单倍体倾向于扩展到共享的染色体区域,似乎由于选择优势而被优先保留(补充数据2),或者它们源自共同的祖先事件(补充图47和48)。一个例外是S288接种株系,根据给定的代码,预计它应该对应于无关的C. liberica内插系(补充图49)。携带插入基因组窗口的非洲和印度标本还包括3个著名的类阿拉比卡品种(即肯特、SL28和SL34)、从埃塞俄比亚种植园采样的2个接种株系(GNG1和GUG3)以及埃塞俄比亚森林生产系统的一个接种株系(CHF1)23。肯特、SL28和SL34通常被认为是本土非洲作物种质的一部分。接种株系CHF1是最特殊的情况,因为它携带的插入窗口数量最少,并且这种内插是纯合的(图3b)。这些可能的C. arabica × C. canephora内插系显示出与Timor杂交衍生物中发现的携带C. canephora内插的基因组部分相似,它们还共享插入区域的位置(补充表9)以及多个重组断点(补充图50)。这些相似之处可能表明它们都从一个共同的祖先那里继承了C. canephora的内插。肯特和SL34的公开可用测序数据显示,作为每个品种代表性测序的单个标本在杂合状态下携带C. canephora内插的片段,这表明它们的内插尚未在代表这些品种的种子库中固定,或者它们可能来自测序采样的地点的局部基因流。SL28的公开可用测序数据显示,作为该品种代表性测序的单个标本以纯合状态携带C. canephora内插(补充图51)。我们重新测序了从哥斯达黎加CATIE咖啡种质资源收集到的另一个SL28接种株系(补充表10),结果没有发现内插的迹象(补充图51),这证实了在使用这些来源的有性繁殖材料建立新的种植园时,个体接种株系中可检测到的内插事件很可能是近期污染事件,对遗传纯度构成威胁。为了了解这个问题对咖啡产业和咖啡科学界的规模,并验证它的出现是否发生在Timor杂交和C. liberica衍生物的全球传播之后,我们重新分析了20世纪60年代在埃塞俄比亚进行的考察收集的生物多样性测序数据,该时间点之前就已经传播了抗叶锈材料,并在埃塞俄比亚的咖啡生产系统中引入了这些材料6(补充方法5)。我们将这些生物型与在埃塞俄比亚和其他地方(主要存放在CATIE相同基因库中)采样的栽培品种和地方品种的其他接种株系进行了比较。正如预期的那样,在假定叶锈抵抗材料到达日期之前(43年之前)收集的埃塞俄比亚生物型中未发现内插的迹象(补充图52-53、补充数据3和补充方法6)。相反,我们发现从喀麦隆引进的波旁/蒂比卡品种“Laurina”的一个标本中有隐藏的Timor杂交内插,但在从波旁岛引进的同一品种“Laurina”的另一个标本中没有发现(补充图54)。我们还发现来自坦桑尼亚的两个C. arabica地方品种中存在来自C. liberica的内插(补充图52-53、55)。考虑到Catimor系列中C. canephora内插单倍体的来源是Timor杂交,很容易得出结论,这种自发杂交事件为阿拉比卡种质内部的遗传变异做出了贡献,超出了育种计划中的有意使用范围,并且对其他近期的C. arabica × Coffea sp.杂交事件也是如此。在从WGS和GBS数据集中删除所有这些已知和隐藏的内插接种株系之后(补充图53),对经过筛选的真正C. arabica种质的遗传多样性进行分析证实,栽培品种、地方品种和自发遗传物质都具有有限的遗传基础。
染色体异常和同源交换作为 C. arabica 物种遗传多样性的驱动因素
基于在用于ONT测序的Bourbon个体中发现的可能最近的同源交换事件(附图56),我们开始在94个真正的C. arabica存取样品集中(这些样品也用于SNP分析,附表1)以及4个对照样品中(附表10)鉴定额外的平衡和不平衡结构变异事件(附方法7)。
通过比较98个再测序存取样品与‘Bourbon’43(见图4),即重测序存取样品的深度覆盖和同源SNP变异频率的比较,我们能够识别不同类型的异常,如非整倍体(图4a和附图57)、缺失和重复(图4b、附图58和附表4)以及同源交换(图4a、b,附图59和60以及附表5),这些异常在‘Bourbon’中没有共享。由于大多数存取样品的读取覆盖较低,我们只能可靠地检测至少200 kb大小的事件,并且无法对重新排列发生的染色体位点进行深入分析。我们使用的方法无法检测到在染色体10中已确认的‘Bourbon’中发现的其他互换事件或其他平衡染色体重排,因为只有改变两个亚基因组之间相对拷贝数的事件才能被识别。我们主要采用的方法是基于同源变异频率的变化,从预期的50%值得知何时存在每个亚基因组的两个拷贝。我们先前称之为ROH43,现在将其命名为ROHH。通过将ROHH结果与相对Bourbon的深度覆盖分析相结合,我们能够识别染色体异常和同源交换,无论它们处于纯合态还是杂合态,以及它们是否表现出体细胞嵌合。这一分析进一步证实了之前的观察,即出现在C. arabica染色体2、7和10中的交换事件似乎早在该物种谱系早期就已发生,因为它们似乎在我们分析的所有存取样品中都固定了(这也被我们的SNP分析所证实,见上文)。然而,我们还检测到了4个存在整条染色体非整倍体、44个存在额外同源交换的存取样品以及3个存在额外大片段缺失或重复的存取样品(附图57和60)。我们检测到的绝大多数事件符合杂合或纯合态下的生殖突变的预期,无论是在ROHH还是DOC方面。然而,有两个事件,一个涉及非整倍体,另一个涉及同源交换,尽管在统计上高度显著且物理上非常大,但只能通过假设被测序的个体经历了导致染色体异常体细胞嵌合的体细胞突变,或者被测序的材料来源于至少两个具有不同检测异常的遗传异质个体来解释。


我们发现3个存在三倍体的存取样品,其中一个涉及到染色体9的额外eugenioides源染色体的副本,另一个涉及到染色体11的额外canephora源染色体的副本。我们还发现了MESF1存取样品中可能存在的嵌合状态,该状态涉及Chr2e的三倍体和Chr10c的单倍体。长期以来已知植物通常比动物更容忍非整倍体,多倍体植物经常出现非整倍体个体的自发发生,这可能是由于减数分裂过程中多个染色体组的正确分离错误引起的。已知异源六倍体小麦可容忍单体和三体变种,新创造的合成异源六倍体小麦植株甚至更容易出现非整倍体46。因此,发现C. arabica存取样品中存在非整倍体的情况并不意外。非整倍体条件在减数分裂过程中无法稳定遗传,但营养繁殖可能有利于长期维持这种条件。对所涉及的存取样品进行核型分析可能为检测到的非整倍体提供确凿证据。非整倍体的存在与C. arabica的二价减数分裂行为的不规则观察13,14以及在培育品种内的表型突变体之间的DNA含量变异的观察22是一致的。
我们在大量存取样品中发现同源交换,它们都涉及到染色体1、5、6、7、8、10和11的末端部分(图5和附表5),这些区域富集了外显子序列,贫乏了转座元件,并且比平均染色体更保持同源(附表6)。总的来说,它们没有富集在特定的基因本体论类别(附表7),并且同源交换的位点与在Timor杂交后代中鉴定出的导入片段的同源重组位点不相对应(附图61)。在图4中可见的涉及一个或少数基因组窗口的ROHH峰值对应的较小交换可能由于我们的分析管线的灵敏度限制而未被发现,这是由于大多数存取样品的读取覆盖较低所确定的。大多数事件涉及埃塞俄比亚的存取样品,包括地方品种和代表基于花园和森林的咖啡生产系统的存取样品。在也门波旁/蒂帕卡种质中发现的唯一一个同源交换事件(附图59-60)在Costarica-1存取样品中被检测到,我们在其中发现了一个可能非常大的嵌合交换事件。根据在‘Bourbon’的不同植株中发现的同源交换多态性,我们搜索了其他广为人知的品种存取样品之间的相似多态性,以解决‘Bourbon’中发生的情况是一个罕见案例还是普遍情况的问题。为此,我们重测序了“Geisha”的两个存取样品(附表10),并将它们彼此比较,以及与第三个公开可用的“Geisha”存取样品(附表1)进行比较。我们在Costarica-1中发现的染色体1上的非常大的嵌合交换事件似乎与1-Geisha存取样品中的同源交换事件重叠(附表5),该存取样品对应于我们从CATIE获得的埃塞俄比亚存取样品T.02722(附表3)。这个事件既不在公开可用的“Geisha”存取样品中(附表1)也不在我们从世界咖啡研究中获得的存取样品中(附表10),这一事实证实了阿拉比卡种质中的同源交换在同名存取样品之间是多态的,并且在被标记为不同名称的存取样品之间是共享的。


许多事件涉及到染色体7,大多数发生在4个同源的另一端,因此处于自异源多倍体状态。事件也被立即检测到,下游位置处于自异源多倍体状态,但是那些发生在染色体的末端部分的事件已经在所有存取样品中固定,因此无法检测到,因为它们不会导致DOC或ROHH的变化。独立实验表明,在C. arabica中减数分裂时发生的同源染色体形成四联体或二联体的情况可能受到这种条件的影响,这也可能解释了我们观察到的该染色体的同源交换频率之高。总的来说,不同染色体的这些事件表明,在C. arabica中,同源配对远未完全或严重受抑制。我们试图对具有相似染色体坐标的事件进行聚类,以指示存取样品之间的共享事件,尽管由于为补偿低读取覆盖而使用的大窗口大小所造成的分析低分辨率不足以保证它们是同系的。除此之外,我们还在同一组中的另外两个埃塞俄比亚存取样品(GSSF5和YASF2,附表1)中发现了一个显然相反的事件,同样处于杂合状态。所有这3个存取样品在系统发育树上都相当远离Bourbon/Typica组,并且彼此之间也相当远,这是基于全基因组SNP建立的(附图45)。我们检测到的45个事件中有25个处于杂合状态,这可能表明由于在互换事件之间的频繁发生,它们的起源非常近。我们观察到在阿拉比卡种质中只有一个固定的同源交换事件(超过我们用于χ-scan分析的大小阈值)和多个其他事件仍然是多态的,这一观察结果进一步支持了该物种的起源是近期的假设。
一种与所预期的异源四倍体水平不同的DOC水平,考虑到配对的同源染色体对,结合ROHH的分析结果,我们还能够推断出大型事件的发生,这些事件会改变染色体片段的总拷贝数,这是由于重复或缺失而导致的(见补充图58和补充数据4)。在异质条件下,我们在一个单个进入系列中检测到涉及Chr4e顶端1.5 Mbp序列的单个复制事件。然而,我们无法确定重复片段的当前位置。我们检测到两个大型缺失事件,每个系列中有一个,一个涉及Chr3c顶端约14.2 Mbp的非常大的片段,另一个涉及Chr7e底端2.2 Mbp的片段。第一个事件被推断为异质条件,而第二个事件则为纯合条件。这三个事件都是终端事件,不在染色体内部。虽然多倍体个体可能比二倍体个体更容忍缺失事件,特别是在纯合条件下,但是与同源交换的数量相比,缺失事件的数量非常有限,再加上单体体的非常罕见,这可能表明在类似C. arabica这样的异源四倍体物种中,这些事件也较不容忍。另一方面,观察到的差异可能仅仅源于不同类型染色体突变的发生频率的差异。即使在缺失和复制的情况下,我们必须再次强调,由于分析流程的灵敏度限制,涉及一个或几个基因组窗口的ROHH峰值对应的较小事件可能未被检测到。
我们所确定的各种染色体异常都没有引入新的序列变异,但它们都能够改变同源基因之间的基因剂量,以及在非整倍体、缺失和复制的情况下的总基因剂量。基因拷贝数的这些变化可能导致表达差异,进而导致显著的表型变异,正如组织培养和体细胞胚胎发生的非整倍体体细胞变异经常发生的情况所示。因此,基因组重排可能代表了一种重要的遗传多样性来源,不断补充该物种内部可用核苷酸多样性极其有限的情况。
使用长读技术开发C. arabica的染色体水平组装使我们能够对构成该物种的两个亲代基因组的结构和演化进行详细的比较分析。在每对同源染色体中,我们观察到两个不同的染色质区域,其对应于具有明显不同结构特征和演化历史的区域:A染色质区具有高基因密度和低序列离散度,而围中心B染色质区由于近期转座子插入而具有低基因密度和高序列离散度。同源基因之间的表达差异对于B染色质区的基因要比A染色质区的基因更高,尽管其数量要小得多。当我们考虑到可能参与咖啡因生物合成的基因时,我们检测到拷贝数的变异以及同源基因间的表达差异。表达差异始终是canephora同源基因中相对于eugenioides同源基因更高的表达,正如之前观察到的35。需要进行额外的实验来确定C. arabica中难以寻找的着丝粒区域,例如染色质免疫沉淀测序以识别支持着丝粒蛋白A占位的序列阵列2。
至于多倍体化之后发生的事件,除了更准确地定义先前已描述的三个同源染色体间的非互惠性染色体交换事件之外,我们还发现了一种互惠性交换事件。不同的证据表明,这四个事件似乎普遍存在于所有分析的进入系列中,因此可能在C. arabica形成后很早就发生了。更重要的是,在大量的进入系列中,我们发现了许多额外的染色体异常事件,包括不同类型的非整倍体、缺失和复制,以及私有于单个或群体进入系列的非互惠性染色体交换,无论是在纯合还是杂合状态下。这些事件似乎是最近发生的,可能代表了一种在该物种中创造遗传变异的机制,而该物种的基因组中核苷酸多样性非常低。基于对大量进入系列的全基因组重新测序数据进行的单核苷酸变异分析显示,在已知亲缘关系的个体以及被认为代表C. arabica栽培品种、地方品种和生态型的少数个体中,存在着来自C. canephora的推测插入基因组片段。将这些插入片段与Timor杂交种的衍生物中存在的片段进行比较,该杂交种是C. arabica进入系列与C. canephora进入系列的杂交植物,带有提供抵抗咖啡叶锈病的基因,发现它们具有共同的起源。检测到的插入事件似乎是当今种子库的最新污染事件,如果使用这些来源的有性繁殖材料建立新的阿拉比卡咖啡园,可能对基因纯度构成威胁。
审稿意见







生物,生殖细胞中的染色体组数为四的叫作四倍体。
注:人的染色体组数为二