
模型可解释性之SHAP

一. 模型可解释性的意义
机器学习在很多领域取得了重要的进步,也帮助人减少了不少体力劳动。要训练一个机器学习模型,以及将模型应用在实际场景中,最重要的是数据的收集以及处理。那么,如何使用模型指导数据收集就成了一个重要的问题,因为搞清楚这个问题,可以让“人工智能”的“人工”部分聚焦在重要的维度,事半功倍。
另外,对于一个模型,它是否符合原本对它的预期,也是在考察模型效果时的一个需要考虑的因素。换句话说,一个模型对于一个特定的样本,哪一些特征起到的决定性作用;再换句话说,当面对老板的“灵魂拷问”时,如何跟他解释他关注的样本没得到更好的效果的原因。
所以,模型可解释性的两层重要的意义:
- 指导业务:模型中的那些特征最重要,使用模型指导业务
- 解释case:解释对特定案例,是哪个特征造成效果的好与不好
在众多模型中,可解释性最强的当然是线性模型;但是由于线性模型在特征提取方面存在天然的弱势,以及过于依赖原始的特征工程,在稍微复杂一些的场景中,基本见不到线性模型的影子。
现在效果比较好的几类模型,tree based模型和neural network模型可获得较好的效果,但他们同时也被称为“黑盒”模型。原因是对于这类模型来说,上面的两点应用很难实现。
所以,打开“黑盒”模型就成了一个值得研究的课题。
二. SHAP
SHAP是解决模型可解释性的一种方法。
主要思想是:合作博弈中个体的边缘收益。通过计算在合作中个体的贡献来确定该个体的重要程度。计算方法是**计算组合中包含某个特征的收益,减去该组合不包含这个特征时的收益,即可得到该特征在这种组合中的贡献度;再计算所有组合,加权平均,得到该特征的整体贡献度。**这就是SHAP的原理,理解了这个他的计算方法就简单了。嗯,计算复杂度!!!
关于SHAP,推荐阅读以下资料。
interpretable-ml-book中的介绍
https://christophm.github.io/interpretable-ml-book/shapley.html
https://christophm.github.io/interpretable-ml-book/shap.html
知乎的介绍
不再黑盒,机器学习解释利器:SHAP原理及实战
博弈论&夏普利值!提高机器学习可解释性的新方法
SHAP知识点全汇总(对上面英语文章的翻译)
需要使用SHAP,请参考 https://github.com/slundberg/shap
1. SHAP解释特征
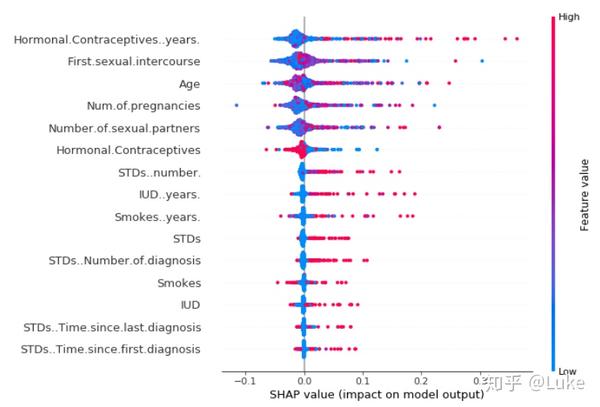

图片来源 https://christophm.github.io/interpretable-ml-book/shap.html
图中每个点代表一个样本点。好的特征应该是将样本分散开的特征。
2. SHAP解释单个样本
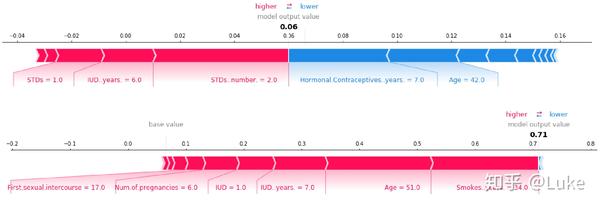
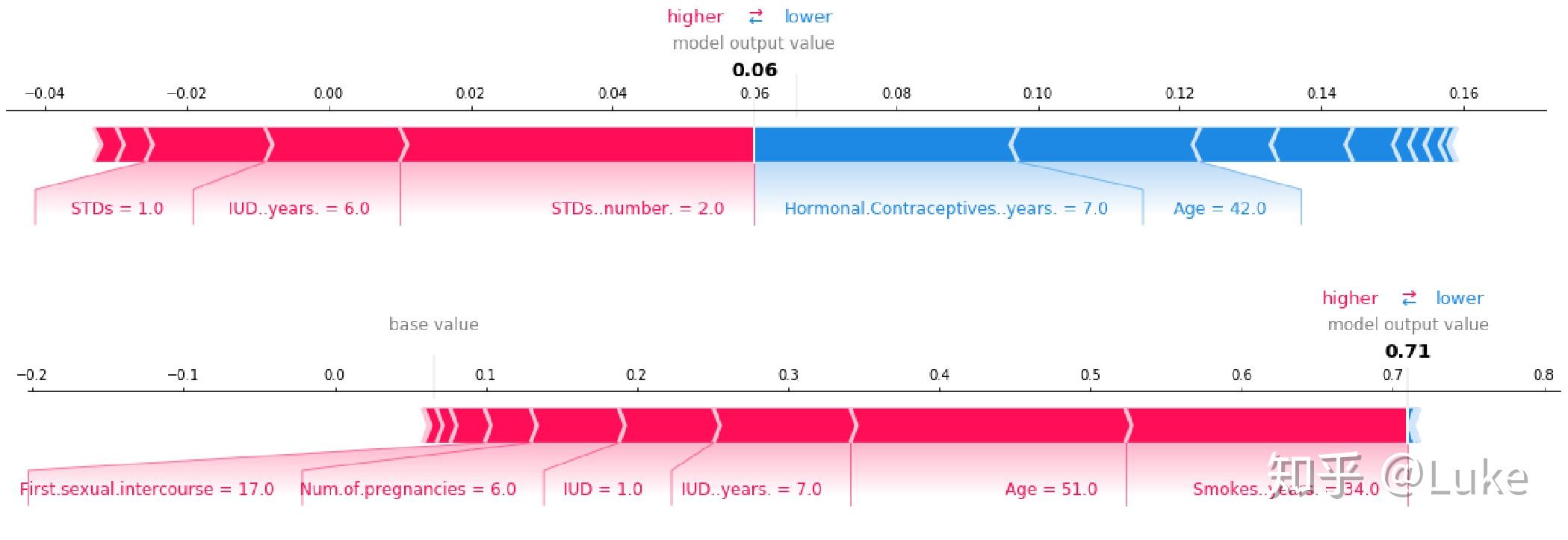
图片来源 https://christophm.github.io/interpretable-ml-book/shap.html
两个图分别代表两个样本。其中红色表示使得预测值提高,蓝色相反。
从图中可以明显找出对于单个个例来说,到底是哪些特征对于该样本造成的影响最大。(看起来可以完美抵御老板的灵魂拷问呢!)
三. 几点思考
1. 特征标准化
在比较特征贡献度时,应保持特征在同一个标准尺度中。一个简单的例子,比如特征从范围0~1变为0~100,那么在相同的模型中,它的权重可能缩小100倍,这并不代表该特征变得不重要了。
但对于SHAP这一类计算边缘贡献的方法来说,特征是否标准化看起来并没有那么重要。但为了模型训练的稳定性,建议还是将特征标准化一下。
2. SHAP的解释是否合理?
- 从整体来看,一个特征的对模型的贡献,等于加入特征后,对模型整体的影响?这样计算应该是不完全的(比如样本呈-1~1均匀分布是,其贡献均值很可能是0),至少还应该考虑上方。所以,SHAP在计算某个特征的重要性的时候计算的是每个样本上shap value的绝对值的平均值。
I_j=\frac{1}{n}\sum_{i=1}^{n}|\phi_j^i| \\
- 对于单个样本来说,shap value表示的就是特征对于该样本边缘贡献,可等价为特征对样本的影响。
文章被以下专栏收录
