机器学习中特征工程

一.为什么要做特征工程
1.选对模型有用的特征,让模型达到尽可能大的性能(准确率);
2.剔除掉无用特征,减少模型的过拟合,增加模型泛化能力;
2.对有用特征做相应变化处理,减少模型复杂性,增加模型的性能;
二.特征工程都要做什么
1.特征采集评估
主要是评估需要采集的成本,特征的完整性,特征的有效性
2.特征预处理
做特征的定性分析,缺失值、异常值,基本特征编码和变化
3.特征无量纲化
将特征从一个范围空间映射到新的空间
4.特征选择
选择对模型最有效的特征
5.高级特征变换
对特征进行交叉,降维,等高级技巧,变化出对模型更有效的特征
三.特征采集评估
1.覆盖率判断
这步的覆盖率分享主要是定性根据先验的领域知识做假设判断,一个特征收集上来覆盖率是否能达到较大比例。比如:
需要一个特征用户财富分布,设计一个产品表单去收集这个特征,必然覆盖率很低,所以这个特征就不能考虑。
2.采集成本分析
我们要尽可能让特征采集的成本足够低,避免特征在用户侧采集成本很高,避免特征在服务端的计算成本很高。比如:
低延迟特征:这类特征要求成本很高的实时流处理技术,比如在一个电商网站,某个商品的上一分钟购买数量。
大数据量特征:这类特征一般带来的就是巨大的计算量和存储容量,比如在一个视频推荐场景,通过采集人眼对视频帧的注意力程度,来分析喜好程度。
采集复杂特征:大多数据采集都是通过“埋点”发生在应用端(客户端),这类特征一般带来的就是产品端复杂逻辑影响主功能,也会带来更多资源的消耗(电量),比如上边提到的人眼的注意力程度。
3.特征完整性
在很多场景,采集的独立特征是对模型没有任何意义甚至会带来负面效果,通常是多组特征一起搭配才有意义。比如:
在短视频推荐场景,只采集视频的清晰度做为特征意义不大,通常要搭配网络情况,手机机型等(代表消费水平)。
在一个新闻推荐场景,只采集点击阅读效果可能不佳,因为有标题党带来的误点击,需要搭配阅读退出行为。
4.特征有效性
避免训练时采集的特征,和模型提供服务时采集的方式不一样,导致特征有效性不足从而带来模型的偏差,比如:
构建超市门店下一礼拜瓶装水销量的模型,用气温做为一个特征,训练时用实测气温,而模型提供服务时用了天气预报预测的气温。
在导航地图的耗时预测模型,用了路线上是否发生事故做为特征,在模型提供服务时没有这个特征到时模型表现不佳。
四.特征预处理
1.缺失值
1.缺失率分析
这个时候特征数据已经收集上来了,通过量化的计算缺失率,如果有较多比例的缺失特征出现,就需要分析缺失原因并对缺失值处理,缺失原因一般分为以下三种:
1.完全随机缺失。也就是缺失的数据点是数据集合随机子集,不和数据集中其他任何特征有关系.
2.随机缺失。数据的缺失和其他变量有关系,比如利用收集的用户信息做为特征,体重这个特征会丢失,因为一般女性更不想暴露体重,所以女生缺失的概率更大。
3.非随机缺失。这类数据的缺失往往是因为数据自身的原因导致(相当通过缺失就可以预测自己或和自己建立联系),假如要做一个调查问卷预测一个人是否会犯罪(所有选项都是选填),里边有一项是否以前有过犯罪,那么缺失的原因是这个人以前有过犯罪而不填这项。(假如2中存在这种现象,体重太大的人不想暴露体重,那么也属于这种)
有了原因分析,可以复制更好的判断如何做缺失值处理。
2.缺失值处理
一般缺失值处理方法有以下几种:
1.直接忽略。
有些算法可以自动处理少量的缺失值,比如xgboost。


2.删除样本
缺点:如果缺失较多会删除较多的样本,如果不是完全随机分布完全,会带来模型的偏差
3.中位数,众数,平均值等简单插补
缺点:如果不是完全随机分布,会破坏特征之间的分布关系,
4.随机抽取已有特征
缺点:如果非完全分布,会破坏特征之间的分布关系
5.创造一个缺失值特征。
比如性别特征,如果存在缺失,可以创造一个缺失的特征值“未知”,特征只从而变成了[男,女,未知]
缺点:一般没有什么缺点,缺失值的样本的预测偏差会增加
6.KNN插补
缺点:计算量大耗时,异常点敏感不好处理
7.多重插补
效果较好,但是计算量很大
缺失值处理,更多查看 《how to handle missing data》 https://towardsdatascience.com/how-to-handle-missing-data-8646b18db0d4


2.异常值检测和处理
比较简单异常值的判断方法一般有如下:
1.领域知识判断。
根据领域知识或者统计学知识检测出异常值,比如在一个电商网站,收集的年龄应该在[14,100]范围内, 超过这个范围应该都属于异常值。
2.3倍标准差规则。
不好设置业务规则的,假如数据符合正态分布,可以用3倍标准差规则来判断,也就是数据和均值的差值超过3倍的标准差认为是异常值。正负3 的概率是 99.7%,那么距离平均值 3 之外的值出现的概率为P(|x-u| > 3) <= 0.003
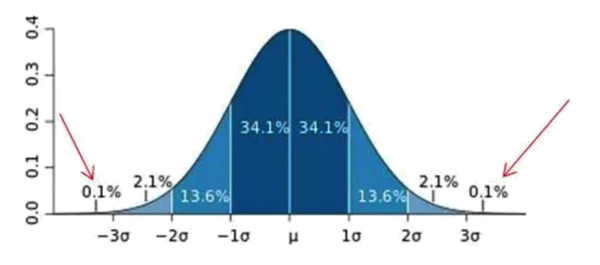

3.箱型图。
把1/4和3/4分位数的值分别扩大3倍做为最小最大边界值,超出边界值认为异常。
4.模型判断。
KNN,KMEANS,预测回归模型
异常值的处理可以和缺失值类似
3.样本不均衡的处理
不考虑在模型,loss和评估指标上改进,只在数据上做工作,如果没法在真实采集上做更多工作,一般有以下三种做法:
1.人工增强数据。
比如在图片分类中,可以对类别少的图片进行 旋转,光照,扭曲变形等增强方式进行扩充
2.过采样。
对类别少的样本进行过采样,简单就是复制几份增加副本
3.欠采样。
对类别多的样本扔掉部分,这种用的比较少
4.基本的特征变化和编码
特征变化和编码主要是要特征定量化,通过领域和模型的专业知识对定量特征做相应的转化,常见做的有以下:
1.one-hot 编码
一般用于将定性特征编码,比如 性别的取值有[男性、女性、未知],那么男性的编码就是[1,0,0]
2.class 编码
比如学历是取值为[小学、初中、高中、大学 ],可以用4个class 来编码,小学=0,初中=1,高中=2,大学=3
这类编码除了分类描述,还能表现出一定逻辑排序关系,起到更强表达能力。
one-hot和class编码除了上边表达的如果有逻辑排序关系外用class编码,完全独立用one-hot编码,在使用模型上也有一些判断标准,如下:
1.如果模型中要做距离度量,对大小敏感,比如LR和SVM等模型,那么one-hot编码更合适
2.如果模型对大小不敏感,比如树模型就可以采用class 编码,one-hot编码会导致树的分裂变多,一般使用树模型为了避免过拟合会限制深度,这样一些特征可能会被舍弃掉
3.二值化编码
主要是根据领域知识对定量特征做冗余信息压缩,比如要判断一个人是否生病,体温的特征就可以二值化编码为 0,1,发热和不发热,除了做冗余信息压缩也能减少噪音数据的影响
4.散列编码
可以解决one-hot维度过高的问题,通过哈希函数将编码映射到一个固定的空间,丧失模型解释性
5.连续数值离散化
以下是找的离散化的优点(来源于网上公开资料):
0. 离散特征的增加和减少都很容易,易于模型的快速迭代;
- 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
- 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
- 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
- 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
- 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
- 特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险
除了这些优点,还有一个显著的优点,就是可以加入领域的先验知识,如在商品推荐上,0.99元和1.01元会带来用户对价格差异性认知,那么用1元区间离散化就会融入这种先验知识。
常见的离散化做法有以下几种:
1.等距法。 也就是上边提到的价格以1元为区间划分
2.等频法。也就是先确定离散区间,比如3组,让排序的特征在每组中出现的数量相等。
6.连续值的数学变换
1.log 变换 y=log(x+1)
对于特征中大于0的连续特征,主要用在数据分布区间过大,导致方差不大。比如商品的购买量,新闻的阅读数等等
2.box-cox 变换
尝试好的λ值,让变换后的数据尽量满足正态分布,(计算抓换后的数据标准差和均值,看落入区间的特征数量比例)
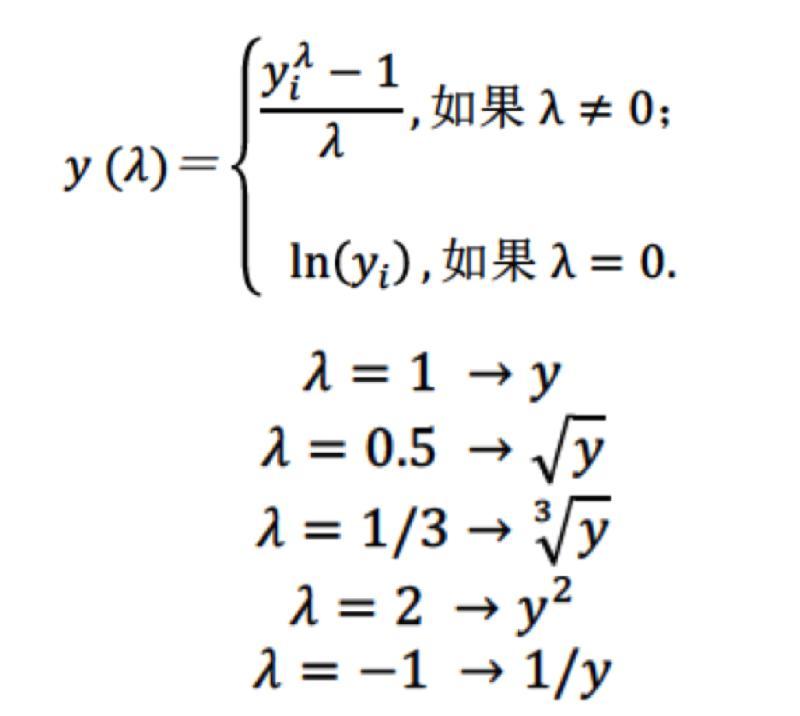

7.连续特征的无量纲化
无量纲化的目的主要有以下点:
1.不同维度的特征在模型学习中可以产生一定比较性,也会利于各种自动和手动的特征交叉,比如身高和年龄
2.在一些距离和距离有关的模型中(比如LR,SVM,KNN,K-means),因为特征尺度差异,损失函数的等高线是椭圆形,导致模型收敛编码或者无法收敛。做了同一纬度的纲化,可以加速模型的收敛过程,在类似的算法中,如果特征不做无量纲化,有可能无法收敛得到一个很好的模型。


在距离无关的模型中(比如树模型,贝叶斯),无量纲化是非必须条件。无量纲化一般有以下做法:
1.区间缩放

2.标准化

x和s分别为均值和标准差
8.连续特征的平滑
因为数据的稀疏性,通常直接统计的数据会有一定的偏差,直接做为特征进行比较会损失公平,例如某个商品的点击量是 10000 次,成单量是 100 次,那转化率就是 1%。但有时,例如一个商品点击量是 3次,成交率量是 1 次,这样算来转化率为 33%,这个时候如果用转化率直接做为特征计算会丧失公平,同样还有在商品评分上,10000个评分,好评9500和2个评分,2个好评,直接算好评率也会带来问题。一般这个时候会常采用以下两种平滑处理:
1.贝叶斯平滑
2.威尔逊区间平滑
五.特征选择
特征选择主要目的是选择有意义的特征,减少特征数量、模型复杂度,亦能减少模型过拟合的风险
1.基于统计的过滤法
1.方差选择。方差太小可以舍弃
2.卡方验证。通过计算特征和预测值之间的卡方值,卡方分布越大,特征相关性越强。
3.皮尔逊相关系数。 如果特征和预测目标存在线性关系,那么皮尔逊相关系数的分值会较大。
4.互信息法。当特征和预测目标完全独立,互信息等于0。


2.包装法
训练一个基模型(一般都会选择效果比较好的模型,svm,gbdt),进行多次训练和测试,每次训练的时候抹掉一个或者多个特征,测试模型的效果。如果去掉某个特征后效果下降很多,证明这个特征有效
3.嵌入法
1.正则惩罚法
在机器学习中L1正则化会将参数稀疏化,L2将参数权重趋于0。
比如用LR模型加入L1惩罚项,一般来说不重要的特征的权重会被惩罚到0,但是注意:两个高度相关的特征可能会有一个的权重被惩罚为0,这个时候采用L2正则化交叉校验,也就是将L2权重差在阈值范围内但是L1特征被惩罚为0的特征挑选出来
2.模型学习
比如采用树模型,越靠近的根部的分裂点一般就是比较重要的特征
5.高级特征变换
1.降维
PCA,LDA,AutoEncoder等。 降低数据维度,让数据更可分,提高信噪比
2.通过模型表达特征
比如以下
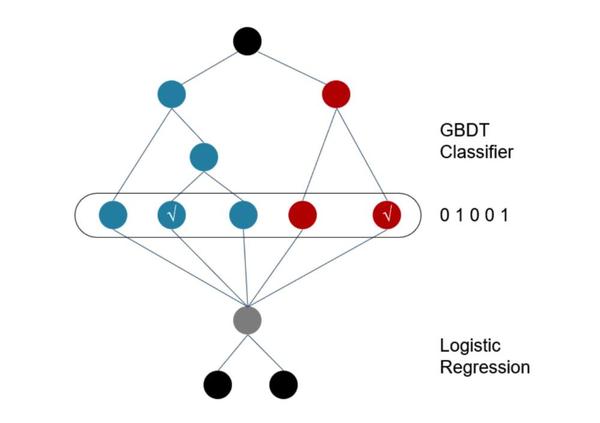
1.LR+GBDT
通过树模型学习表达连续特征为离散特征,再输入LR模型学习

2.通过神经网络表达。
在上一节中已经有提到,word2vec 表示item,cnn或bert预训练表示图像和文本等。
3.特征交叉
1.通过业务领域知识做手动特征交叉
特征交叉常见的做法有笛卡尔积和hadamard积,以下这图能比较好的说明这两种交叉的区别。


比如第一种笛卡尔交叉会带来没有意义的交叉(女性 X 男性平均播放时长)。这里举一个比较好的例子:
1.微视中会有 这种交叉特征 : 视频名称_推荐数_跳过数,比如 王者荣耀_30_30。代表王者荣耀推送了30次,用户跳过了30次,那么那次再推送王者荣耀,用户非常大概率还是跳过,基于这种特征交叉,就可以比较容易捕获到用户对某种题材的喜好。
还有些特征做了交叉,才有使用意义,比如
2.比如推荐的视频要将清晰度做为一个特征,那么最好是将这个视频清晰度和用户接入网络情况做交叉。
2.FM 自动交叉




通过矩阵分解减少参数量,通过数学变化,减少计算量,通过FM机可以做到二阶的笛卡尔特征交叉。相应的变种还有FFM,引入了“域”的概念,在FM每个特征和其他特征交叉的隐向量一致,而在FFM中,一个特征和其他特征交叉时,可以采用不同的“域”,不同“域”的隐向量不同。